De chamadas de API para modelos de linguagem grandes (LLMs) a fluxos de trabalho autônomos e orientados por metas, há uma mudança fundamental no paradigma dos aplicativos de IA. A comunidade de código aberto desempenhou um papel fundamental nessa onda, dando origem a uma infinidade de ferramentas de IA voltadas para tarefas de pesquisa específicas. Essas ferramentas não são mais modelos únicos, mas sistemas complexos que integram recursos de planejamento, colaboração, recuperação de informações e invocação de ferramentas. Neste documento, faremos um mergulho profundo em dez assistentes de pesquisa de código aberto representativos e analisaremos seus caminhos tecnológicos, filosofias de design e posicionamento estratégico no ecossistema de IA.
Sistemas Multiagentes (MAS): Colaboração Estruturada e Adaptação Dinâmica
Os sistemas multiagentes (MAS) resolvem problemas complexos que são difíceis de serem resolvidos por uma única inteligência, permitindo que várias inteligências independentes trabalhem juntas. O DeerFlow e o OWL demonstram os dois caminhos de implementação dominantes nessa área: hierárquico e descentralizado.
O DeerFlow representa um modelo hierárquico e estruturado de colaboração. Ele desconstrói o sistema em Coordenador, Planejador e Equipes de Especialistas, o que foi projetado para se assemelhar a uma estrutura corporativa bem organizada. O fluxo de trabalho é determinístico: o Planejador decompõe as tarefas, o Coordenador as atribui e a Inteligência Especializada as executa. A vantagem desse modelo é que ele é extremamente eficiente e previsível ao lidar com tarefas claramente delimitadas que podem ser decompostas de forma eficiente. Por exemplo, ao realizar uma auditoria de segurança de uma base de código em grande escala, o DeerFlow pode atribuir tarefas de forma estável a inteligências com funções diferentes, como análise de código e detecção de vulnerabilidades, e agregar relatórios.

Endereço do projeto:https://github.com/bytedance/deer-flow
A OWL incorpora a filosofia de colaboração descentralizada e dinamicamente adaptável. Ele se baseia na estrutura CAMEL-AI, que se concentra na "interpretação de papéis" e na "comunicação e negociação" entre inteligências. Diferentemente da divisão de trabalho predefinida no DeerFlow, as inteligências no OWL podem negociar dinamicamente e assumir diferentes funções de acordo com o andamento das tarefas em tempo real. Esse modelo de colaboração emergente é vantajoso ao lidar com problemas abertos e não estruturados (por exemplo, exploração científica interdisciplinar) porque permite que o sistema explore a melhor maneira de colaborar por conta própria por meio da interação das inteligências sem um caminho claro para uma solução.

Endereço do projeto:https://github.com/camel-ai/owl
Advanced Retrieval Augmented Generation (Advanced RAG): da recuperação de informações à exploração do conhecimento
O Retrieval-Augmented Generation (RAG) tornou-se uma técnica padrão para atenuar as ilusões de modelo e introduzir informações em tempo real, e o WebThinker e o Search-R1 o levaram de um modelo simples de "geração de recuperação" para uma "exploração agêntica" mais avançada. O WebThinker e o Search-R1 o levaram de um modelo simples de "geração de recuperação" para uma "exploração agêntica" mais avançada.
A principal inovação do WebThinker é a capacidade de oferecer ao LLM a navegação autônoma. Ele vai além do escopo do RAG tradicional, que extrai apenas trechos de texto de páginas de resultados de mecanismos de pesquisa (SERPs) ou bancos de dados vetoriais, e é capaz de imitar o comportamento de um usuário humano que clica em um link e se aprofunda no conteúdo de uma página da Web. Seu processo de loop fechado "pensar-pesquisar-escrever" gera essencialmente um Rastro de Raciocínio detalhado, que é otimizado pelo aprendizado por reforço. Isso permite que ele crie um quadro de conhecimento mais abrangente na análise da opinião pública ou em tarefas de rastreamento do setor que exigem profundidade e amplitude de informações.

Endereço do projeto:https://github.com/RUC-NLPIR/WebThinker
O Search-R1 concentra-se em "Metacognição para pesquisa". Não se trata de um agente de pesquisa fixo, mas de uma estrutura modular para criar e avaliar agentes de pesquisa. Os usuários podem combinar livremente diferentes modelos de linguagem grandes, como LLaMA3, Qwen2.5 etc., com algoritmos de aprendizagem por reforço, como PPO, GRPO etc., da mesma forma que configuram um servidor. Essa abstração de meta-nível o torna uma poderosa ferramenta de pesquisa, permitindo que os desenvolvedores explorem a questão fundamental de como a IA aprende a pesquisar, em vez de ficarem satisfeitos com os próprios resultados da pesquisa.

Endereço do projeto:https://github.com/PeterGriffinJin/Search-R1
Inteligência de borda e soberania de dados: a ascensão da IA localizada
A Alita e a AgenticSeek são representativas das soluções que estão levando a computação de IA da nuvem para a borda, à medida que aumentam as demandas por privacidade de dados e capacidade de resposta.
O conceito central do Alita é simplificar a integração e a reutilização de ferramentas por meio de interfaces padronizadas. Seu Protocolo de Contexto de Modelo (MCP) pode ser entendido como uma "Interface Binária de Aplicativo (ABI) para ferramentas de IA". Ao definir um formato de interação uniforme para diferentes ferramentas, o Alita permite o acesso rápido e a expansão da funcionalidade sem a necessidade de adaptações complexas para cada nova ferramenta. Essa natureza "plug-and-play" permite que a arquitetura de raciocínio de módulo único permaneça leve e, ao mesmo tempo, tenha um forte potencial de autoevolução, reduzindo consideravelmente as barreiras para a criação de aplicativos complexos de IA para indivíduos e pequenas equipes.
Endereço do projeto:https://github.com/CharlesQ9/Alita
O AgenticSeek leva a soberania de dados ao extremo. Ele é um agente de IA que é executado inteiramente no dispositivo local e não depende de nenhuma chamada de API na nuvem, garantindo que nenhum dado saia da área local. Seu mecanismo interno de correspondência de inteligência de tarefas pode ser considerado como um modelo leve de "Mixture of Experts (MoE)" do lado do dispositivo, programando de forma inteligente os recursos locais mais adequados com base no tipo de tarefa (navegação, codificação, planejamento). Isso lhe confere uma vantagem insubstituível ao lidar com dados altamente confidenciais, como dados financeiros e médicos, ou ao trabalhar em ambientes off-line.
Endereço do projeto:https://github.com/Fosowl/agenticSeek
Capacidade de modelagem desbloqueada: o debate sobre o ajuste fino supervisionado versus o caminho do aprendizado por reforço
O SimpleDeepSearcher e o ReCall representam aplicações inovadoras de dois caminhos tecnológicos principais, respectivamente.
O SimpleDeepSearcher provou que o Supervised Fine-Tuning (SFT) de alta qualidade é igualmente capaz de alcançar recursos de pesquisa complexos que antes eram considerados possíveis apenas com o Reinforcement Learning (RL). A chave para seu sucesso está na forma como os dados de treinamento são construídos. Em vez de usar pares de dados simples (entrada, saída final), ele gera dados de "trajetória de raciocínio" que contêm etapas intermediárias e processos de tomada de decisão, simulando interações reais de páginas da Web. Essa imitação do "processo de raciocínio" é menos dispendiosa e mais estável do que começar do zero com a exploração do aprendizado por reforço e oferece um atalho valioso para o treinamento de modelos especializados de alto desempenho com recursos limitados.

Endereço do projeto:https://github.com/RUCAIBox/SimpleDeepSearcher
O ReCall se concentra em um caminho de aprendizagem por reforço puro, abordando a capacidade de generalização dos LLMs para "aprender a usar ferramentas". Seu recurso mais atraente é que ele não requer dados de chamadas de ferramentas rotuladas manualmente. O modelo recebe feedback dos resultados retornados (sucesso, falha, mensagens de erro) por meio da interação direta com o ambiente (por exemplo, pontos de extremidade da API) e usa isso como um sinal de aprendizado para otimizar continuamente sua estratégia de invocação de ferramentas. Isso é análogo ao Reinforcement Learning from AI Feedback (RLAIF), que permite que os modelos aprendam de forma autônoma a invocar ferramentas do tipo OpenAI em fluxos de tarefas complexos. Esse recurso é uma etapa essencial no caminho para alcançar a IA de uso geral (AGI).
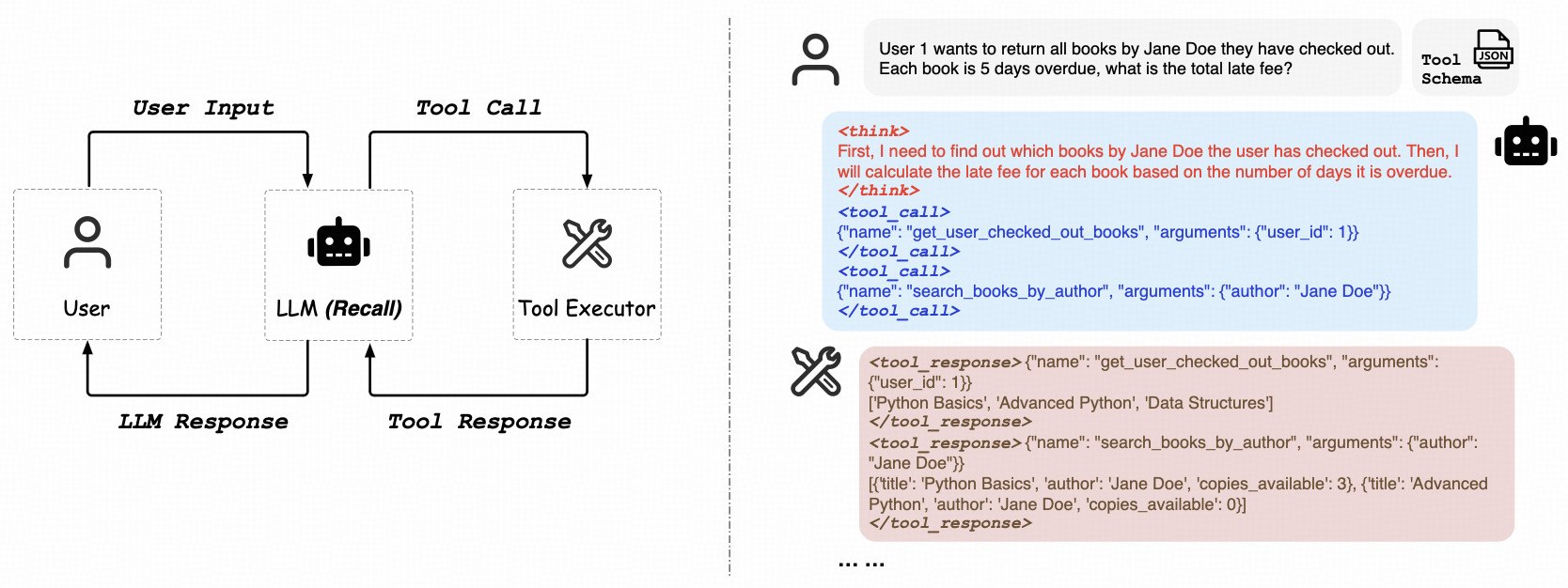
Endereço do projeto:https://github.com/Agent-RL/ReCall
Plataformas de ponta a ponta e rigor de pesquisa
À medida que os recursos subjacentes amadurecem, a integração de várias funções em uma plataforma de ponta a ponta e a garantia da confiabilidade do resultado se tornam um nível mais alto de busca.
A Suna está posicionada como um "IDE de fluxo de trabalho nativo de IA". Em vez de se concentrar na inovação de uma tecnologia de IA subjacente, a Suna se concentra em melhorar a experiência do desenvolvedor (DX). Ao integrar perfeitamente a navegação na Web, o processamento de arquivos, a execução da linha de comando e até mesmo a implantação de sites, a Suna visa eliminar o custo de alternar entre diferentes ferramentas em um fluxo de trabalho técnico. É mais como um Zapier ou Make para desenvolvedores, integrando profundamente os recursos de IA em todo o processo de gerenciamento e execução de projetos.

Endereço do projeto:https://github.com/kortix-ai/suna
O DeepResearcher, por outro lado, aborda diretamente o maior desafio da IA em pesquisas sérias: a confiabilidade. Ele usa o aprendizado por reforço de ponta a ponta para treinar modelos e criar uma estratégia de pesquisa rigorosa. Seu principal mecanismo de "autorreflexão" representa uma espécie de "humildade epistêmica". Quando o modelo ainda não consegue chegar a uma conclusão de alta confiança depois de verificar várias fontes de informação, ele optará ativamente por "admitir que não sabe" em vez de alucinar com confiança, como fazem muitos modelos. Esse tipo de consciência e honestidade sobre a incerteza é uma qualidade necessária para que a IA se transforme de um "gerador de informações" em um "parceiro de pesquisa" confiável.

Endereço do projeto:https://github.com/GAIR-NLP/DeepResearcher