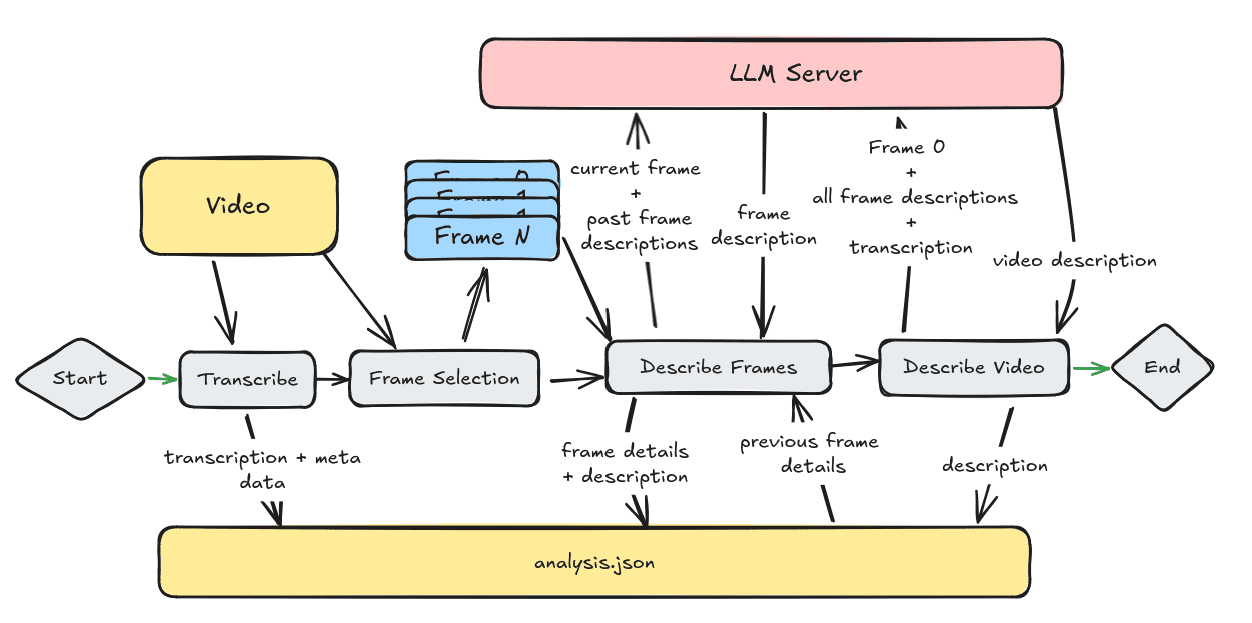
Twelve Labs: soluções multimodais de IA para compreensão de conteúdo de vídeo, pesquisa de vídeo, geração e incorporação de serviços de API
A Twelve Labs é uma empresa de IA multimodal focada na compreensão de vídeo, dedicada a ajudar os usuários a compreender e processar grandes quantidades de conteúdo de vídeo por meio de tecnologias avançadas de IA. Suas principais tecnologias incluem pesquisa, geração e incorporação de vídeo, que são capazes de extrair os principais recursos do vídeo, como ações, objetos, texto na tela, fala e personagens...