Devido ao tráfego excessivo e a um ataque cibernético, o site e o aplicativo do DeepSeek ficaram fora do ar por alguns dias e a API não está funcionando.

Anteriormente, compartilhamos o método para implantar o DeepSeek-R1 localmente (consulteImplantação local do DeepSeek-R1), mas o usuário comum está limitado a uma configuração de hardware que dificulta a execução até mesmo de um modelo de 70b, quanto mais de um modelo completo de 671b.
Felizmente, todas as principais plataformas têm acesso ao DeepSeek-R1, portanto, você pode experimentá-lo como um substituto simples.
I. Microsserviços NVIDIA NIM
NVIDIA Build: integre vários modelos de IA e experimente-os gratuitamente
Site: https://build.nvidia.com/deepseek-ai/deepseek-r1
A NVIDIA implementou o parâmetro de volume total 671B do DeepSeek-R1 Modelos, a versão da Web é simples de usar e você pode ver a janela de bate-papo ao clicar nela:
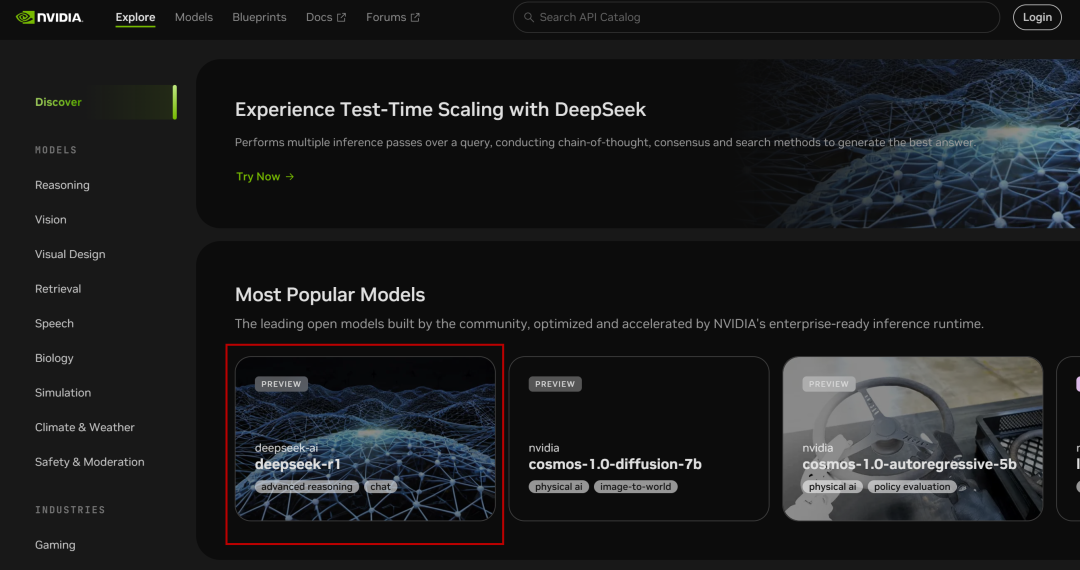
A página de código também está listada à direita:
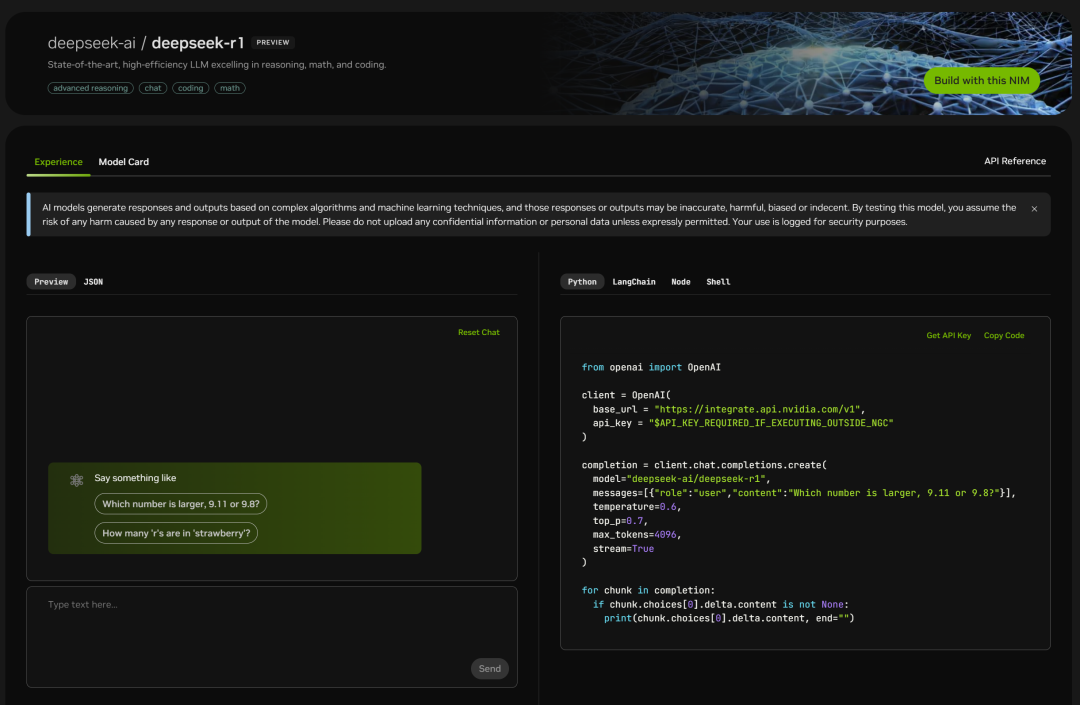
Basta testá-lo:
Abaixo da caixa de bate-papo, você também pode ativar alguns itens de parâmetro (que podem ser padronizados na maioria dos casos):
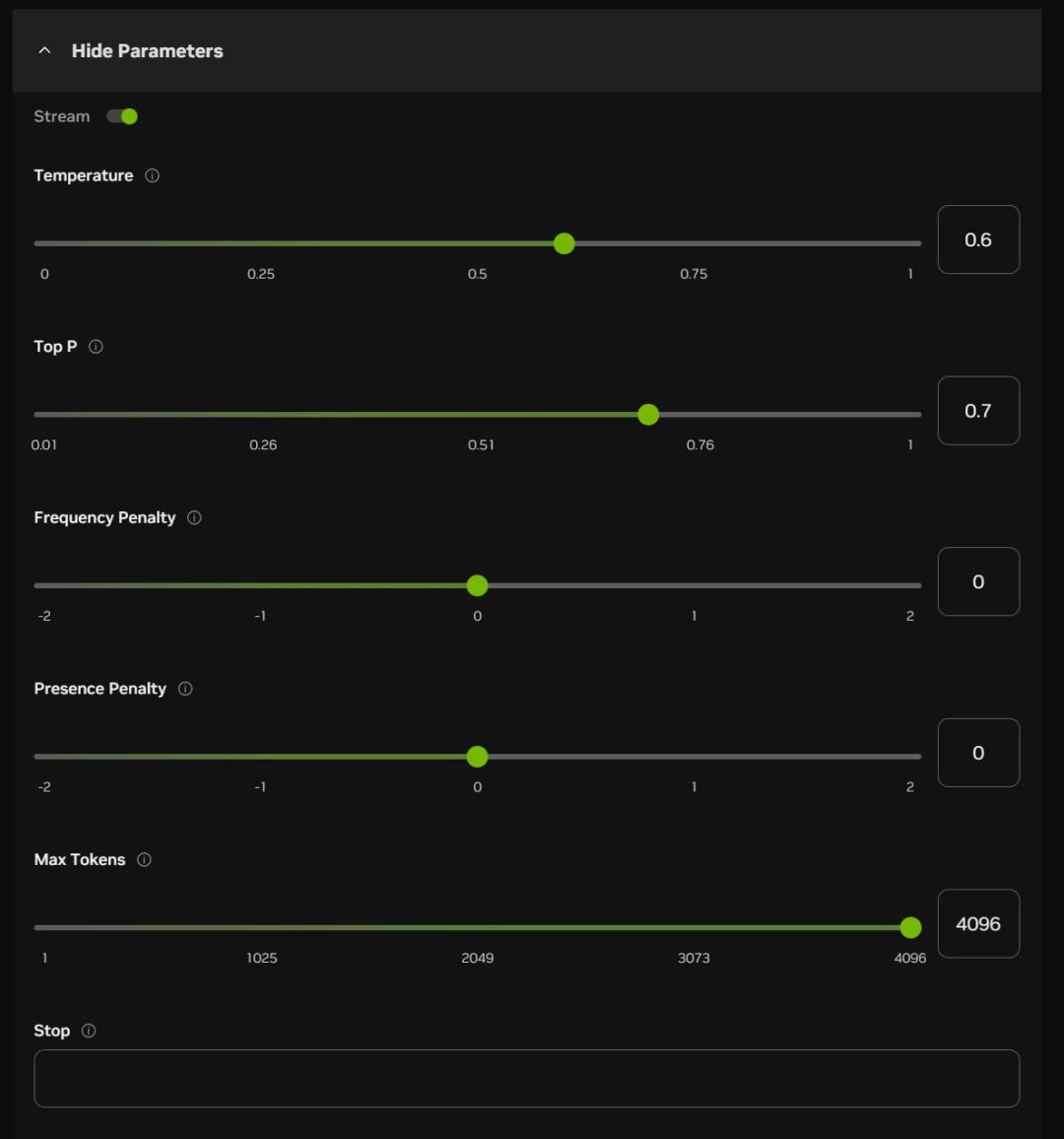
Os significados aproximados e as funções dessas opções estão listados abaixo:
Temperatura:
Quanto maior o valor, mais aleatória será a saída e mais respostas criativas poderão ser geradas
P superior (amostragem nuclear):
Valores mais altos retêm mais tokens de qualidade probabilística e geram mais diversidade
Penalidade de frequência:
Valores mais altos penalizam mais as palavras de alta frequência e reduzem a verbosidade ou a repetição
Penalidade de presença:
Quanto maior o valor, mais inclinado o modelo estará a experimentar novas palavras
Máximo de fichas:
Quanto maior o valor, maior o comprimento potencial da resposta
Pare:
Interromper a saída ao gerar determinados caracteres ou sequências, para evitar a geração de tópicos muito longos ou esgotados.
Atualmente, devido ao número cada vez maior de brancos (observe o número de pessoas na fila no gráfico abaixo), o NIM está atrasado em parte do tempo:
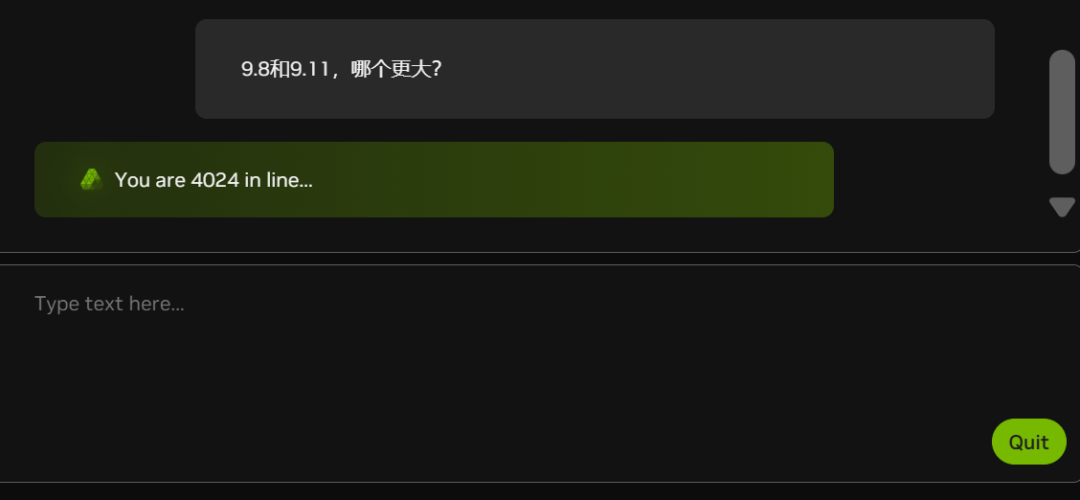
A NVIDIA também está com falta de placas de vídeo?
Os microsserviços NIM também oferecem suporte a chamadas de API para o DeepSeek-R1, mas você precisa se inscrever em uma conta com um endereço de e-mail:
O processo de registro é relativamente simples, usando apenas a verificação de e-mail:
Depois de se registrar, você pode clicar em "Build with this NIM" (Criar com este NIM) no canto superior direito da interface de bate-papo para gerar uma API KEY e, no momento, você receberá 1.000 pontos (1.000 interações) por se registrar, portanto, você pode usar tudo isso e depois se registrar novamente com um novo endereço de e-mail.
A plataforma de microsserviços NIM também oferece acesso a muitos outros modelos:

II. Microsoft Azure
Site da Web:
https://ai.azure.com
O Microsoft Azure permite que você crie um chatbot e interaja com o modelo por meio de um playground de bate-papo.
O Azure é muito trabalhoso para se inscrever, primeiro você precisa criar uma conta da Microsoft (basta fazer login se já tiver uma):
A criação de uma conta também requer verificação de e-mail:
Para terminar, prove que você é humano respondendo a 10 perguntas consecutivas do mundo inferior:

Chegar aqui não é suficiente para criar uma assinatura:
Verifique o número do telefone celular, bem como o número da conta bancária e outras informações:
Em seguida, selecione "No technical support" (Sem suporte técnico):

Aqui você pode iniciar a implementação na nuvem. No "Catálogo de modelos", você pode ver o modelo DeepSeek-R1 em destaque:
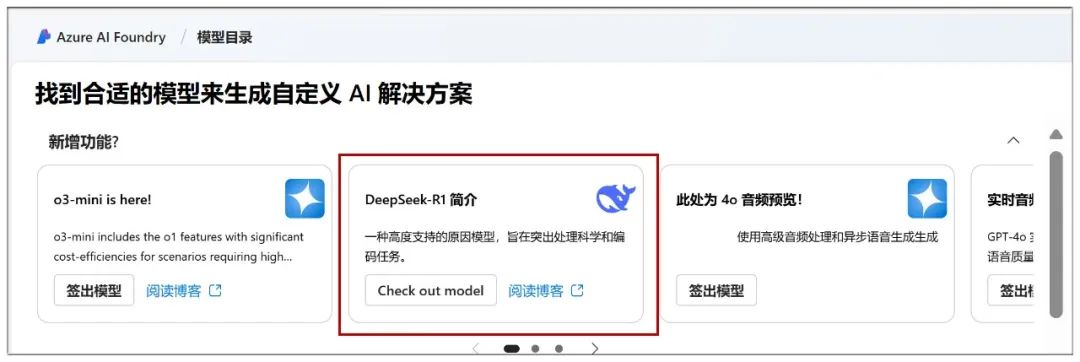
Uma vez clicado, clique em "Deploy" (Implantar) na próxima página:
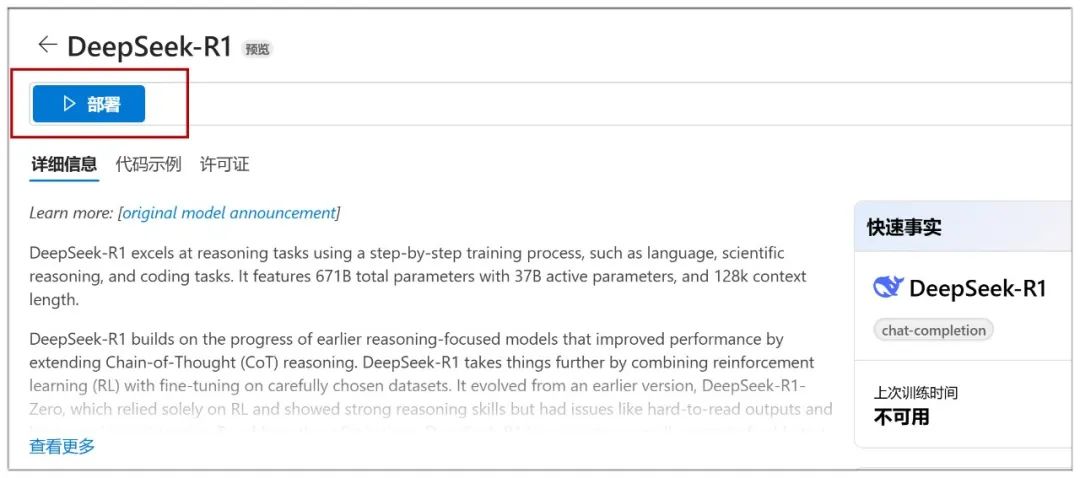
Em seguida, você precisa selecionar "Create new project" (Criar novo projeto):
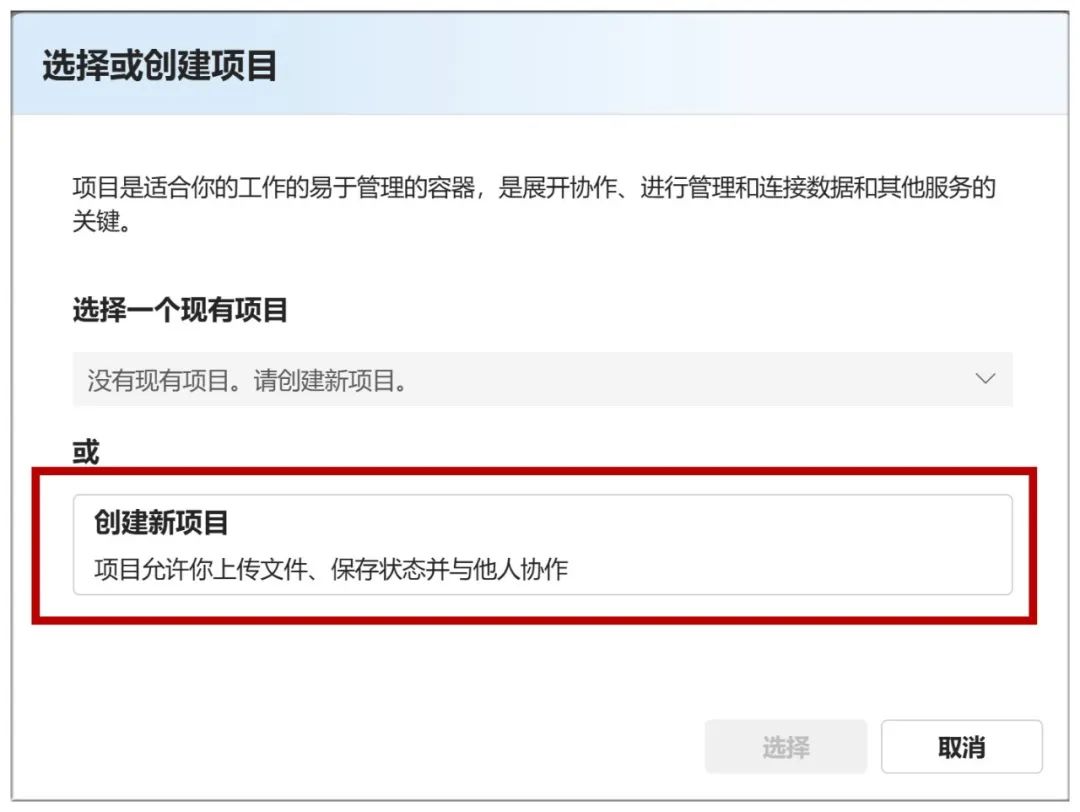
Em seguida, defina todos eles como padrão e clique em "Next" (Avançar):
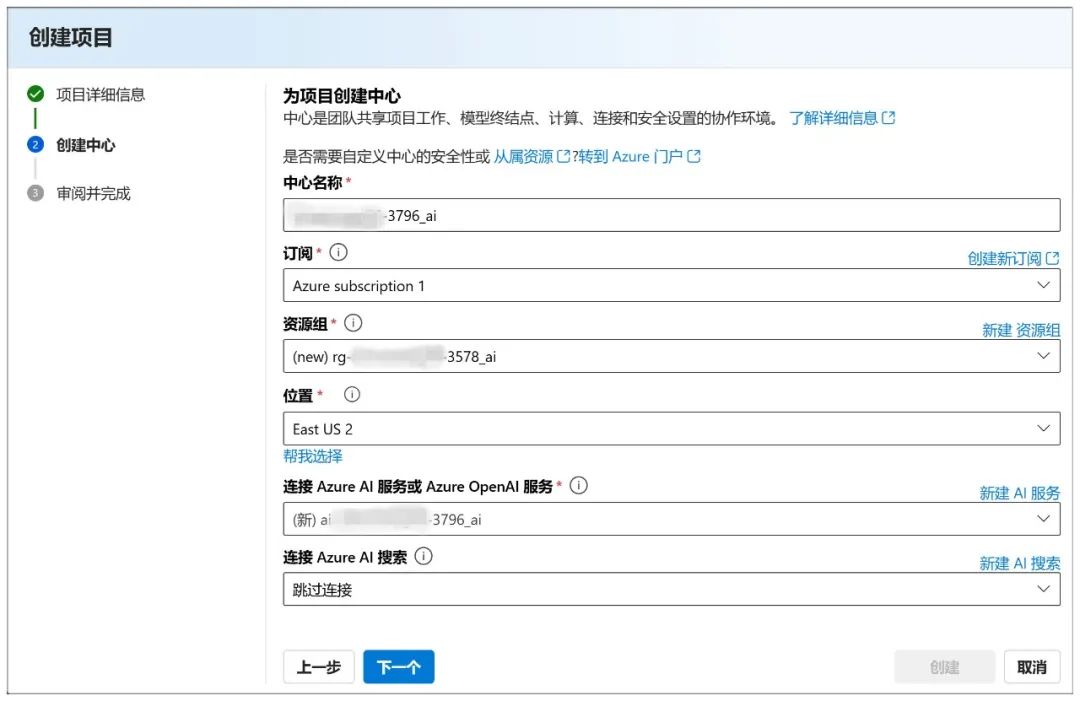
Em seguida, clique em "Create" (Criar):
A criação nessa página é iniciada e demora um pouco para esperar:

Quando terminar, você chegará a esta página, onde poderá clicar em "Deploy" para ir para a próxima etapa:
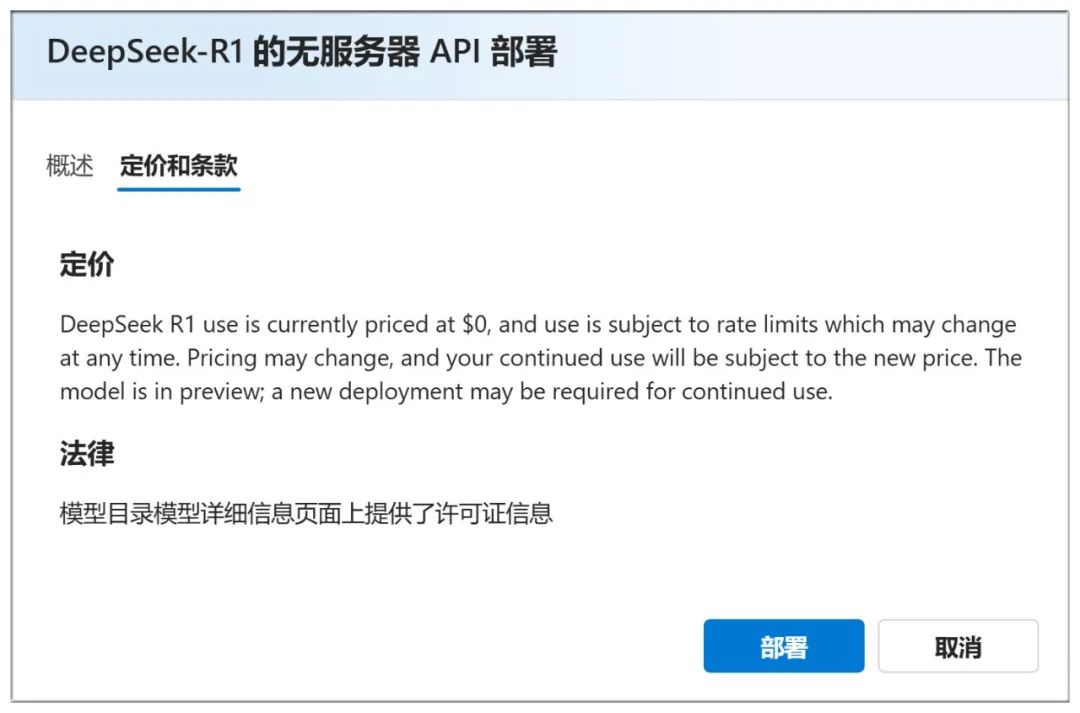
Você também pode verificar a seção "Preços e termos" acima para ver que o uso é gratuito:
Continue nesta página clicando em "Deployment" (Implantação) e clique em "Open in Playground" (Abrir no Playground):
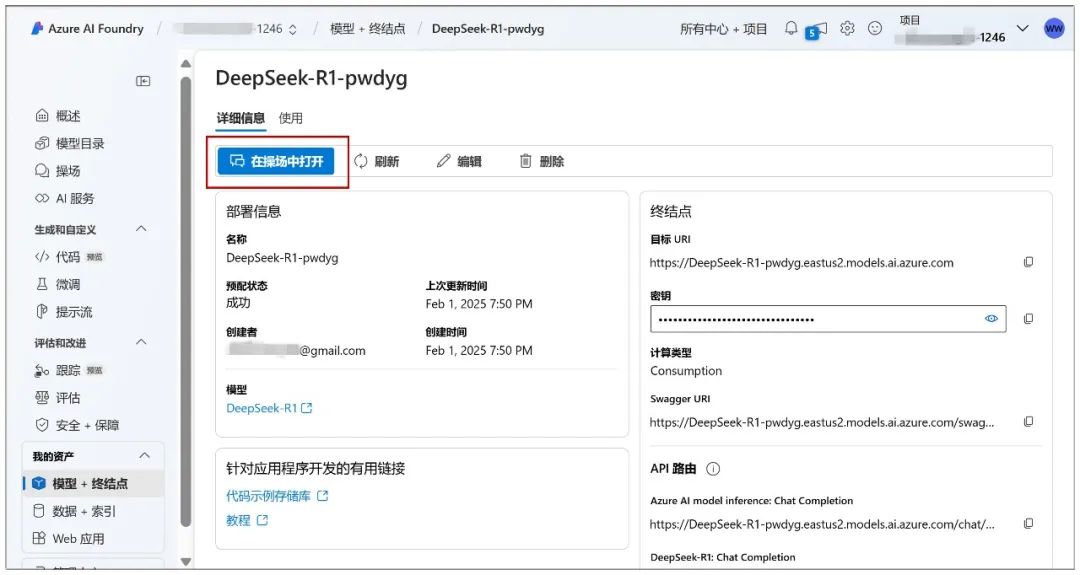
Então, o diálogo pode começar:
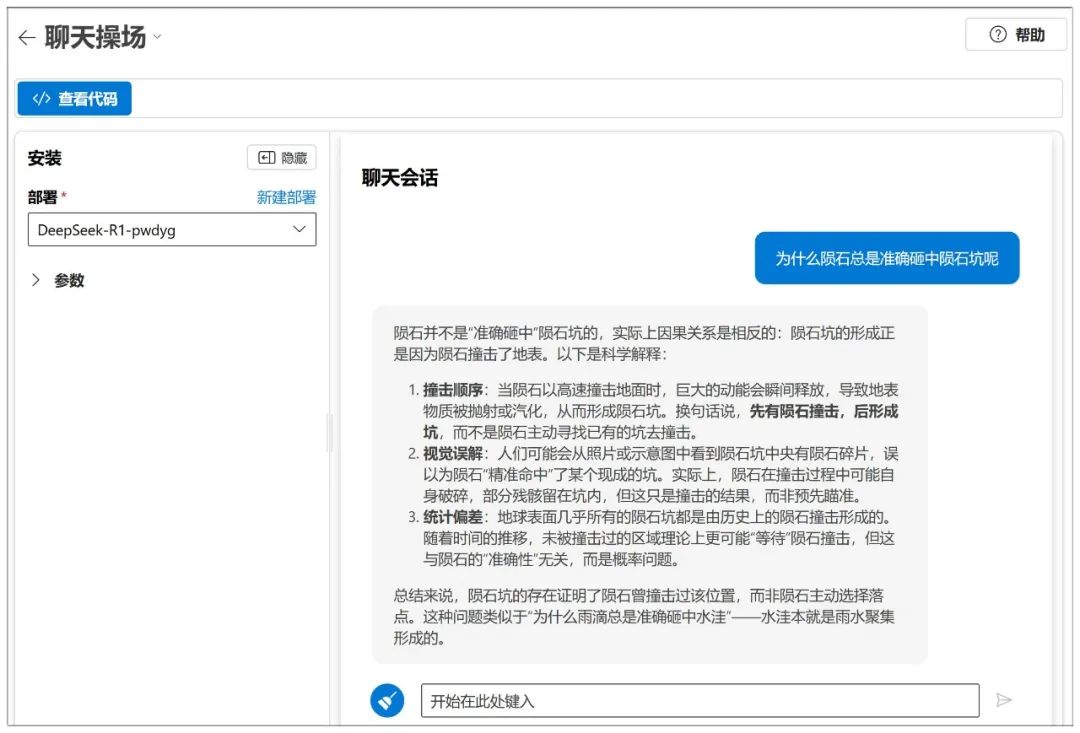
O Azure também tem disponível o ajuste de parâmetros semelhante ao NIM:
Como uma plataforma, há muitos modelos que podem ser implementados:
Os modelos já implantados podem ser acessados rapidamente no futuro por meio de "Playground" ou "Model + Endpoint" no menu à esquerda:
III. Amazon AWS
Site da Web:
https://aws.amazon.com/cn/blogs/aws/deepseek-r1-models-now-available-on-aws
O DeepSeek-R1 também está em destaque e alinhado.
O processo de registro do Amazon AWS e do Microsoft Azure é quase tão problemático quanto, ambos têm que preencher o método de pagamento, mas também a verificação do telefone + verificação de voz, que não será descrita em detalhes aqui:

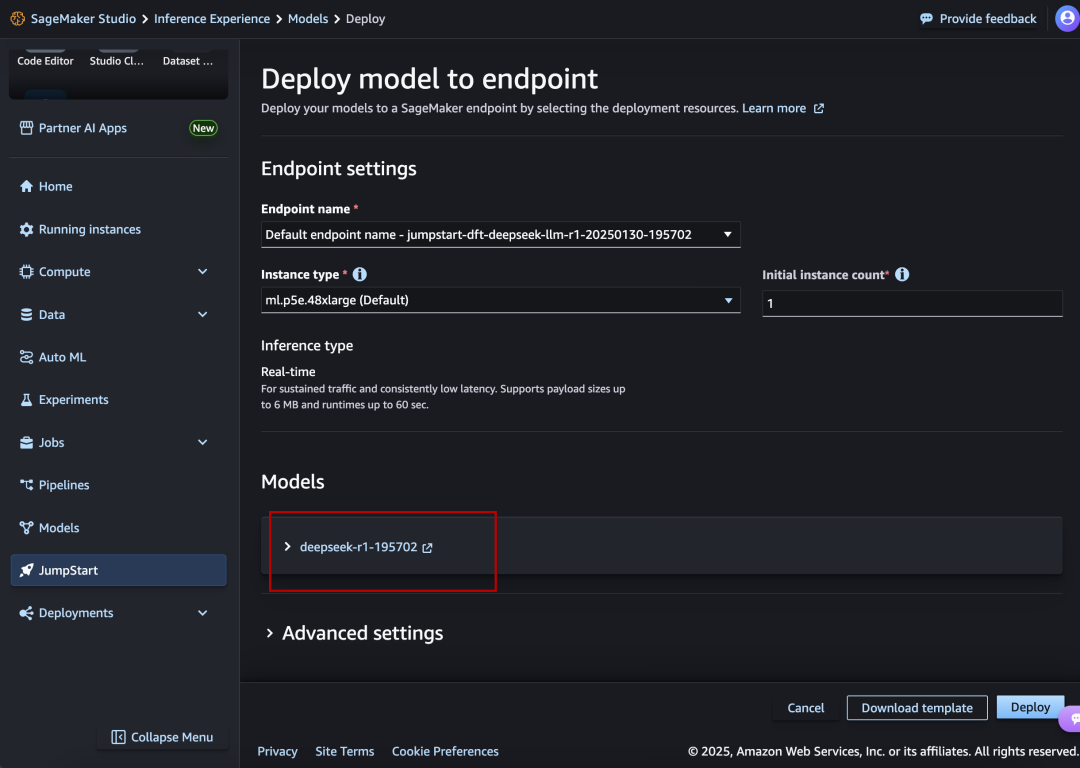
O processo exato de implantação é praticamente o mesmo do Microsoft Azure:
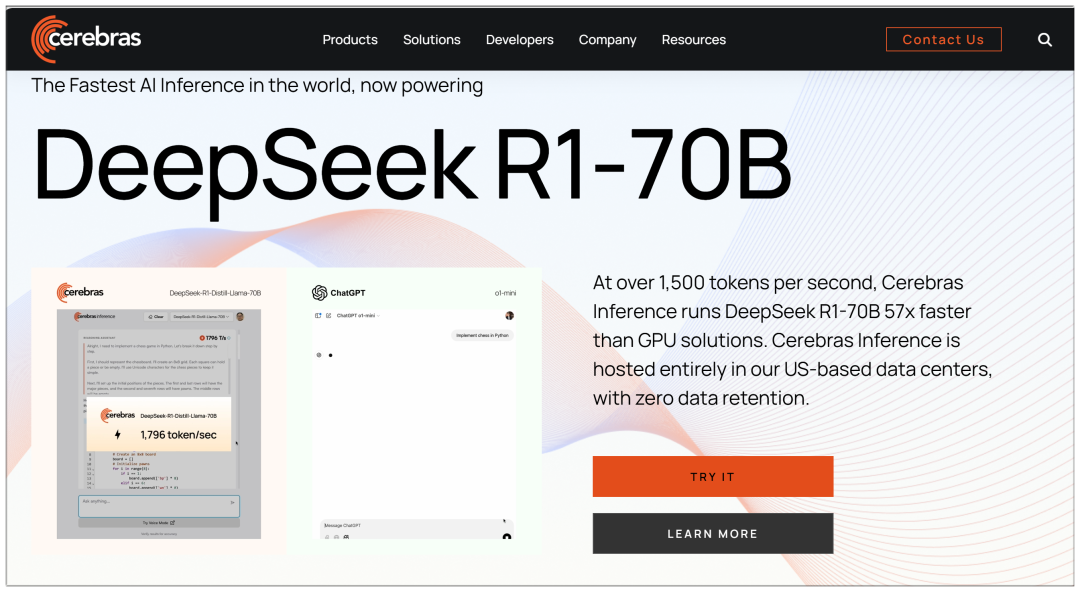
IV. Cerebras
Cerebras: a plataforma de computação de alto desempenho e inferência de IA mais rápida do mundo disponível atualmente
Site: https://cerebras.ai
Ao contrário de várias plataformas grandes, a Cerebras usa um modelo de 70b, alegando ser "57 vezes mais rápida do que as soluções de GPU":
Depois que o registro de e-mail for inserido, o menu suspenso na parte superior permitirá que você selecione DeepSeek-R1:
As velocidades no mundo real são, de fato, mais rápidas, embora não tão exageradas quanto se afirma:
V. Groq
Groq: provedor de soluções de aceleração de inferência de modelo grande de IA, interface de modelo grande gratuita e de alta velocidade
Site: https://groq.com/groqcloud-makes-deepseek-r1-distill-llama-70b-available

Os modelos também estão disponíveis para seleção assim que o e-mail for registrado e inserido:

Também é rápido, mas, novamente, o 70b parece um pouco mais retardado do que o Cerebras?
Observe que a interface de bate-papo pode ser acessada diretamente enquanto estiver conectado:
https://console.groq.com/playground?model=deepseek-r1-distill-llama-70b
Lista completa do DeepSeek V3 e R1:
AMD
GPUs AMD Instinct™ potencializam o DeepSeek-V3: revolucionando o desenvolvimento de IA com SGLang (GPUs AMD Instinct™ potencializam o DeepSeek-V3: revolucionando o desenvolvimento de IA com SGLang)
NVIDIA
Placa modelo NVIDIA DeepSeek-R1 (Placa modelo NVIDIA DeepSeek-R1)
Microsoft Azure
Executando o DeepSeek-R1 em uma única VM NDv5 MI300X (executando o DeepSeek-R1 em uma única VM NDv5 MI300X)
Baseten
https://www.baseten.co/library/deepseek-v3/
Novita AI
Novita AI usa SGLang executando DeepSeek-V3 para OpenRouter (Novita AI usando SGLang para executar o DeepSeek-V3 para OpenRouter)
ByteDance Volcengine
O modelo em tamanho real do DeepSeek aterrissa no Volcano Engine!
DataCrunch
Implantar o DeepSeek-R1 671B em 8x NVIDIA H200 com SGLang (Implementação do DeepSeek-R1 671B em 8x NVIDIA H200 usando SGLang)
Hiperbólico
https://x.com/zjasper666/status/1872657228676895185
Vultr
Como implantar o modelo de linguagem grande (LLM) do Deepseek V3 usando SGLang (Como implementar com SGLang) Deepseek V3 Modelagem de linguagem grande (LLM))
RunPod
O que há de novo para o uso do LLM sem servidor no RunPod em 2025? (Quais são os novos recursos usados pelo Serverless LLM no RunPod em 2025?)