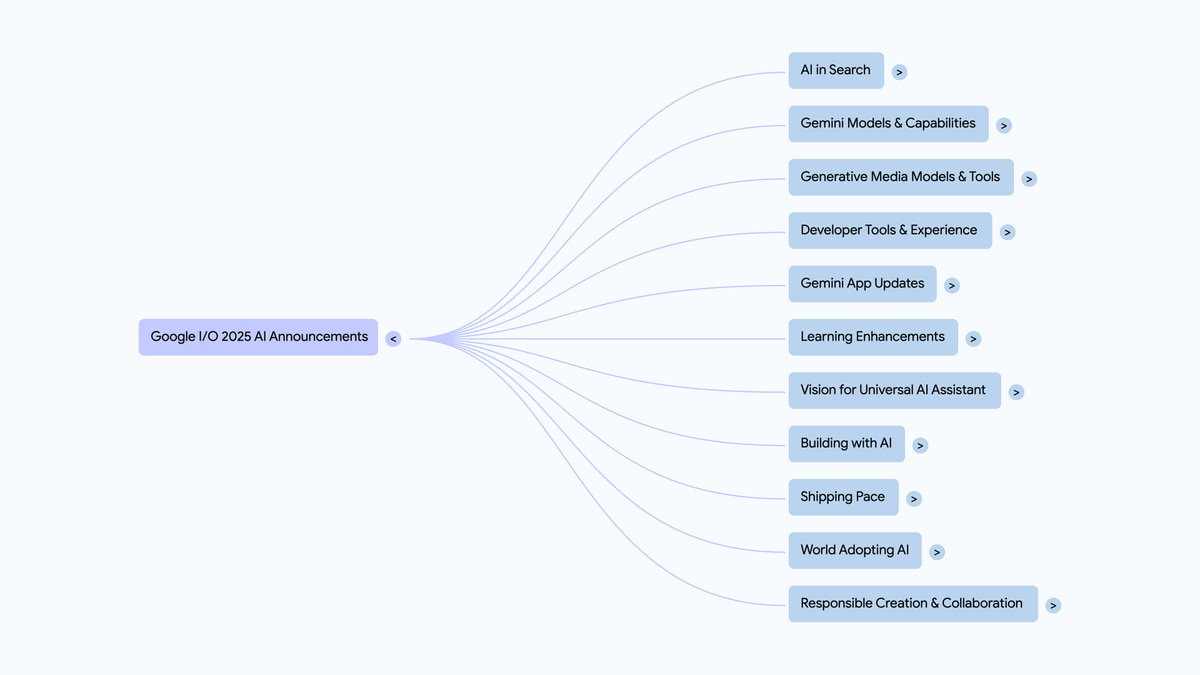
Meta AI O V-JEPA 2 (Video Joint Embedding Predictive Architecture 2), seu modelo mundial mais recente, foi lançado em 11 de junho. O modelo atinge o desempenho mais avançado em compreensão visual e previsão do mundo físico e pode ser usado para o planejamento "zero-shot" de robôs que interagem com objetos desconhecidos em ambientes desconhecidos.
Juntamente com o lançamento do modelo, há três novos testes de benchmark projetados para avaliar com mais precisão a capacidade dos modelos existentes de raciocinar sobre o mundo físico. Essa mudança não é apenas mais um passo no caminho do Meta para alcançar a inteligência de máquina avançada (AMI), mas também fornece ao setor como um todo um novo parâmetro para medir a capacidade da IA de interagir com o mundo físico.

O que é o modelo mundial?
Os bebês humanos estabelecem sua intuição sobre o mundo por meio da observação muito antes de aprenderem a falar. Por exemplo, jogue uma bola de tênis para cima e ela cairá sem pairar no ar ou se transformar repentinamente em uma maçã. Essa intuição física é uma manifestação do modelo do mundo interno.
Esse modelo interno nos permite prever as consequências do nosso próprio comportamento ou do comportamento dos outros e, assim, planejar com antecedência. Ao navegar em uma sala lotada, subconscientemente antecipamos caminhos para evitar colisões; ao preparar o jantar, avaliamos empiricamente quando devemos desligar o fogo.
Para criar agentes de IA que possam "pensar antes de agir" no mundo físico, seu modelo de mundo deve ter três recursos principais:
- entendimentosCapacidade de reconhecer objetos, ações e movimentos em um vídeo.
- anteciparCapacidade de prever a evolução do mundo e como ele mudará em resposta a intervenções comportamentais específicas.
- planejar (como fazer algo)Planejamento de uma série de ações que levarão à realização de uma meta, com base em recursos de previsão.

Detalhes do modelo V-JEPA 2
O V-JEPA 2 é um modelo com 1,2 bilhão de parâmetros criado com base na arquitetura JEPA (Joint Embedded Prediction Architecture) proposta pela primeira vez pela Meta em 2022. O modelo é treinado principalmente por meio de aprendizado autossupervisionado em grandes quantidades de vídeo, o que lhe dá uma visão de como o mundo funciona sem a necessidade de rotulagem humana.
Seu núcleo contém dois componentes:
- CodificadorVídeo bruto de entrada e incorporação de saída que capturam as principais informações semânticas sobre o estado do mundo.
- PreditorInformações contextuais: receba informações contextuais, como embeddings de vídeo e alvos de previsão, e produza embeddings de previsão para o futuro.

O treinamento para o V-JEPA 2 é dividido em duas fases:
- Pré-treinamento sem movimentoO modelo foi treinado primeiramente em mais de 1 milhão de horas de vídeo e 1 milhão de imagens. Esses dados lhe ensinaram os conceitos básicos de como os objetos se movem e interagem. Após essa fase, o modelo atingiu o nível mais alto em tarefas como reconhecimento de ações (Something-Something v2), antecipação de ações (Epic-Kitchens-100) e testes de vídeo (Perception Test, TempCompass).
- Treinamento com condicionamento de movimentoEtapa 1: Com base na primeira etapa, o modelo é treinado usando dados que contêm os movimentos visuais e de controle do robô. Essa etapa permitiu que o preditor aprendesse a levar em conta "ações específicas". De forma notável, essa fase permitiu que o modelo obtivesse recursos eficazes de planejamento e controle usando apenas 62 horas de dados do robô.
O V-JEPA 2 demonstra excelentes recursos de amostra zero em tarefas de planejamento de robôs. Treinada em um conjunto de dados DROID de código aberto, ela pode ser implantada diretamente nos robôs do MetaLab sem nenhum ajuste fino para novos ambientes ou novos robôs.
Para tarefas curtas, como agarrar e colocar, basta fornecer ao robô uma imagem do estado da meta. O robô usa o preditor V-JEPA 2 para "visualizar" as consequências da execução de uma série de ações candidatas e seleciona a que mais se aproxima do objetivo. Por meio do controle preditivo de modelo, o robô pode replanejar e executar ações continuamente. Para tarefas mais complexas e de longa duração, o robô pode ser orientado por meio de uma série de submetas visuais. Dessa forma, o V-JEPA 2 alcançou uma taxa de sucesso de 65% - 80% no manuseio de tarefas de pegar e colocar objetos não vistos em um novo ambiente.

V-JEPA 2 Recursos relacionados.
Estabelecendo novos padrões de referência para a compreensão da física
Os três novos testes de benchmark lançados juntamente com o modelo não são menos importantes do que o próprio modelo. Eles foram projetados para solucionar as falhas no sistema de avaliação atual e estimular a comunidade a criar modelos que realmente compreendam o mundo físico. Embora os seres humanos possam alcançar uma precisão de 85% - 95% nesses testes, ainda há uma lacuna significativa entre o desempenho dos principais modelos, incluindo o V-JEPA 2, e os seres humanos.
- IntPhys 2
O benchmark tem como objetivo medir a capacidade de um modelo de distinguir entre cenários fisicamente "possíveis" e "impossíveis". Ele usa o mecanismo de jogo para gerar pares de vídeos, um dos quais está sujeito a um evento que viola as leis da física em um determinado nó. O modelo precisa identificar qual vídeo é problemático. Os resultados dos testes mostram que o modelo de vídeo atual tem um desempenho próximo ao da adivinhação aleatória nessa tarefa.Recursos IntPhys 2.
- Pares mínimos de vídeo (MVPBench)
Esse benchmark avalia a compreensão física de um modelo de linguagem de vídeo por meio de perguntas de múltipla escolha. Ele é engenhoso, pois cada amostra tem um "par de variação mínima": um vídeo que é visualmente muito semelhante, mas com respostas opostas. O modelo deve responder corretamente a ambas as perguntas para marcar pontos, o que efetivamente reduz o problema de "atalhos" do modelo por meio de dicas visuais ou textuais superficiais.Recursos do MVPBench.
- CausalVQA
O benchmark se concentra na compreensão causal do mundo físico. Ele apresenta modelos com contrafactuais ("O que aconteceria se ......?") , expectativas ("O que acontecerá em seguida?") e planejamento ("O que devo fazer em seguida para atingir meu objetivo?") e outras perguntas. Os testes constataram que, embora o modelo multimodal grande tenha respondido bem à pergunta "o que aconteceu", ele não teve um bom desempenho em perguntas como "o que poderia ter acontecido" ou "o que poderia ter acontecido". mal.
Recursos do CausalVQA.
A Meta também postou um Face Hugging emas paradas (de best-sellers)que são usados para acompanhar o progresso dos modelos da comunidade em relação a esses novos padrões de referência.
A próxima etapa da inteligência de máquina avançada
O V-JEPA 2 é apenas o começo. Atualmente, ele aprende e faz previsões em uma única escala de tempo. No entanto, tarefas como "colocar os pratos na máquina de lavar louça" ou "assar um bolo" exigem planejamento hierárquico em diferentes escalas de tempo.
Portanto, pesquisas futuras se concentrarão em modelos JEPA hierárquicos capazes de aprender, raciocinar e planejar em várias escalas espaciais e temporais. Outra direção importante são os modelos JEPA multimodais, que são capazes de fundir informações visuais, auditivas, táteis e outras informações sensoriais para previsão. Essas explorações continuarão a impulsionar a profunda integração da IA com o mundo físico.