breve
A fragmentação de dados é uma etapa fundamental dos sistemas RAG (Retrieval Augmented Generation). Ele divide documentos grandes em partes menores e gerenciáveis para indexação, recuperação e processamento eficientes. Este LEIAME fornece RAG Visão geral dos vários métodos de chunking disponíveis no pipeline.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Importância do chunking no RAG
A fragmentação eficaz é essencial para o sistema RAG porque pode:
- Melhorar a precisão da recuperação criando unidades de informação coerentes e autônomas.
- Aumento da eficiência da geração de incorporação e da pesquisa de similaridade.
- Permite uma seleção de contexto mais precisa ao gerar respostas.
- Ajude a gerenciar modelos de linguagem e sistemas incorporados de Token Limitações.
Método de fragmentação
Implementamos seis métodos diferentes de chunking, cada um com diferentes vantagens e cenários de uso:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
- ClusterSemanticChunker
- LLMSemanticChunker
fragmentação
1. RecursiveCharacterTextSplitter

2. TokenTextSplitter

3. KamradtSemanticChunker
4. KamradtModifiedChunker

5. clusterSemanticChunker

6. LLMSemanticChunker

Descrição do método
- RecursiveCharacterTextSplitterDivisão de texto: divide o texto com base em uma hierarquia de delimitadores, priorizando pontos de interrupção naturais no documento.
- TokenTextSplitterDivisão de texto: divide o texto em blocos de um número fixo de tokens, garantindo que a divisão ocorra nos limites dos tokens.
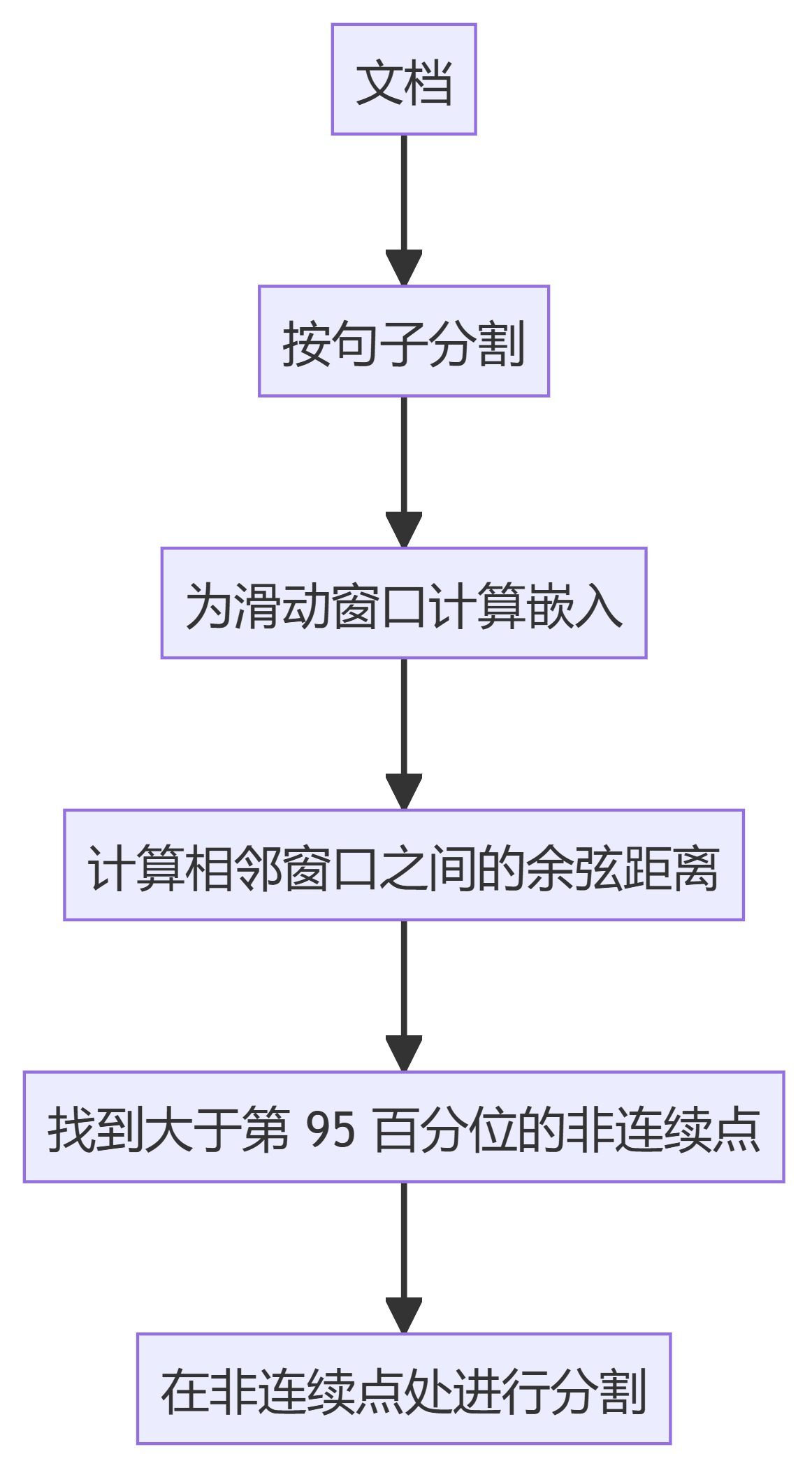
- KamradtSemanticChunkerUse a incorporação de janelas deslizantes para identificar descontinuidades semânticas e segmentar o texto adequadamente.
- KamradtModifiedChunkerKamradtSemanticChunker: uma versão aprimorada do KamradtSemanticChunker que usa a pesquisa de bissecção para encontrar o limite ideal para a segmentação.
- ClusterSemanticChunkerDivisão do texto em partes, cálculo dos embeddings e uso de programação dinâmica para criar partes ideais com base na similaridade semântica.
- LLMSemanticChunkerUse a modelagem de linguagem para identificar pontos de segmentação apropriados no texto.
Uso
Para usar esses métodos de fragmentação em seu processo RAG:
- através de (uma lacuna)
chunkerspara importar os chunkers necessários. - Inicialize o agrupador com os parâmetros apropriados (por exemplo, tamanho máximo do agrupamento, sobreposição).
- Passe seu documento para o fragmentador para obter resultados de fragmentação.
Exemplo:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
Como escolher um método de fragmentação
A escolha do método de fragmentação depende de seu caso de uso específico:
- Para a divisão simples de texto, você pode usar o RecursiveCharacterTextSplitter ou o TokenTextSplitter.
- Se a segmentação com reconhecimento semântico for necessária, considere o KamradtSemanticChunker ou o KamradtModifiedChunker.
- Para obter um chunking semântico mais avançado, use o ClusterSemanticChunker ou o LLMSemanticChunker.
Fatores a serem considerados ao selecionar um método:
- Estrutura do documento e tipos de conteúdo
- Tamanho do bloco e sobreposição necessários
- Recursos de computação disponíveis
- Requisitos específicos do sistema de recuperação (por exemplo, baseado em vetores ou em palavras-chave)
É possível experimentar diferentes métodos e encontrar o que melhor se adapta às suas necessidades de documentação e recuperação.
Integração com sistemas RAG
Depois de concluir o chunking, geralmente são executadas as seguintes etapas:
- Gerar embeddings para cada pedaço (para sistemas de recuperação baseados em vetores).
- Indexar esses blocos no sistema de recuperação selecionado (por exemplo, banco de dados vetorial, índice invertido).
- Ao responder a uma consulta, use os blocos de índice na etapa de recuperação.