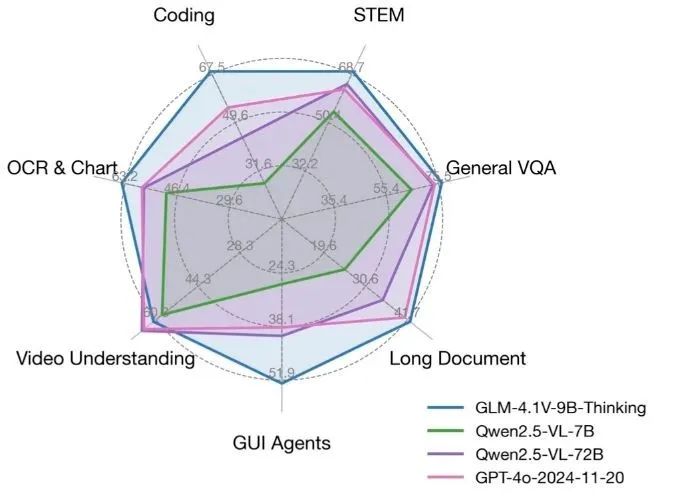
O GLM-4.1V-Thinking é um modelo de linguagem visual de código aberto desenvolvido pelo KEG Lab (THUDM) da Universidade de Tsinghua, com foco em recursos de raciocínio multimodal. Com base no modelo básico GLM-4-9B-0414, o GLM-4.1V-Thinking aprimora significativamente a capacidade de processamento de tarefas complexas por meio do aprendizado por reforço e do mecanismo de raciocínio de "cadeia de raciocínio". Ele suporta contextos ultralongos de 64k, processamento de imagens de alta resolução 4K e é compatível com proporções arbitrárias de imagens, além de suporte bilíngue para inglês e chinês. O modelo se destaca em tarefas como matemática, código, compreensão de documentos longos e raciocínio de vídeo e, em algumas análises, supera até mesmo o GPT-4o. O código e o modelo estão disponíveis no GitHub sob a licença MIT e são gratuitos para uso comercial por desenvolvedores, pesquisadores e empresas.
Lista de funções
- Suporte a contextos de 64k muito longos para lidar com documentos longos ou diálogos complexos.
- Lida com imagens de alta resolução 4K e suporta proporções arbitrárias.
- Oferece suporte bilíngue em inglês e chinês, adequado para cenários em vários idiomas.
- Integrar mecanismos de raciocínio de "cadeia de pensamento" para melhorar a precisão em tarefas de matemática, código e lógica.
- Oferece suporte ao raciocínio de vídeo para analisar o conteúdo do vídeo e responder a perguntas relacionadas.
- Código-fonte e modelos abertos, com base na licença MIT, permitindo o uso comercial gratuito.
- As demonstrações on-line do Hugging Face e do ModelScope estão disponíveis para uma rápida experiência dos recursos de modelagem.
- Suporta a execução em uma única placa de vídeo 3090 para ambientes de desenvolvimento com recursos limitados.
Usando a Ajuda
Instalação e implementação
O GLM-4.1V-Thinking fornece arquivos completos de código e modelo com um processo de implantação fácil para os desenvolvedores executarem localmente ou em um servidor. Veja a seguir as etapas detalhadas de instalação e uso:
1. preparação ambiental
Ele precisa ser executado em um ambiente habilitado para GPU; recomenda-se uma placa de vídeo NVIDIA (como a RTX 3090). Certifique-se de que o Python 3.8 ou superior esteja instalado, bem como o PyTorch. Aqui estão as etapas para instalar as dependências:
pip install git+https://github.com/huggingface/transformers.git
pip install torch torchvision torchaudio
pip install -r requirements.txt
Se for necessário o ajuste fino do modelo, consulte finetune/README.md usando o kit de ferramentas LLaMA-Factory. Ao fazer o ajuste fino, é recomendável usar a estratégia Zero3 para garantir a estabilidade do treinamento e evitar o problema de perda zero que pode resultar do Zero2.
2. download do modelo
O modelo GLM-4.1V-Thinking pode ser baixado dos repositórios Hugging Face ou GitHub. Execute o código a seguir para carregar o modelo:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Suporte ao modelo bfloat16 formato, menor espaço de memória e adequado para operação com uma única GPU.
3. raciocínio de imagem única
O GLM-4.1V-Thinking oferece suporte a tarefas de raciocínio com entrada de imagens. Abaixo está um exemplo simples de uma descrição de imagem:
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/sample_image.png"},
{"type": "text", "text": "描述这张图片"}
]
}
]
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
comandante-em-chefe (militar) sample_image.png Substitua pelo URL real da imagem ou pelo caminho local. O modelo analisa a imagem e gera uma descrição detalhada.
4. raciocínio em vídeo
O GLM-4.1V-Thinking oferece suporte à análise de conteúdo de vídeo. Os usuários podem carregar um arquivo de vídeo por meio de um código de amostra em um repositório do GitHub ou por meio de uma plataforma de demonstração on-line (por exemplo, Hugging Face), e o modelo analisará o vídeo e responderá a perguntas sobre ele. Por exemplo, se você carregar um vídeo de uma reunião e perguntar "quais tópicos foram discutidos no vídeo", o modelo extrairá as principais informações e gerará uma resposta precisa.
5. compreensão de documentos longos
O modelo suporta contextos longos de 64k, o que é ideal para processar documentos longos. Os usuários podem inserir texto no modelo e solicitar conteúdo específico ou resumir os principais pontos do documento. Por exemplo, insira um artigo acadêmico de 50 páginas e pergunte "Quais são as principais conclusões do artigo?" e o modelo as extrairá e resumirá rapidamente.
6. apresentação on-line
Nenhuma implantação local é necessária e pode ser experimentada diretamente por meio de uma demonstração on-line fornecida pela Hugging Face ou pela ModelScope. Acesse os links abaixo:
- Demonstração do Face Hugging:
https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking - Demonstração do ModelScope:
https://modelscope.cn/models/THUDM/GLM-4.1V-9B-Thinking
Os usuários podem fazer upload de imagens, vídeos ou inserir texto para testar rapidamente o raciocínio do modelo.
7. ajuste fino do modelo
Os desenvolvedores podem usar o kit de ferramentas LLaMA-Factory para ajustar o modelo a tarefas específicas. O arquivo de configuração de ajuste fino está localizado no diretório configs/lora.yamlExecute o seguinte comando para iniciar o ajuste fino:
cd finetune
python finetune.py data/YourDataset/ THUDM/GLM-4-9B-0414 configs/lora.yaml
Certifique-se de que o conjunto de dados esteja formatado corretamente; recomenda-se o formato JSON. Após o ajuste fino, o modelo pode ser melhor adaptado a tarefas específicas do domínio, como análise de imagens médicas ou processamento de documentos jurídicos.
Operação da função em destaque
- raciocínio de cadeia mentalO modelo decompõe problemas complexos por meio de um mecanismo de "cadeia de pensamento". Por exemplo, em uma tarefa de matemática, o modelo deriva a resposta passo a passo para garantir um resultado preciso. O usuário digita "Solve the quadratic equation x² + 2x - 3 = 0" (Resolva a equação quadrática x² + 2x - 3 = 0) e o modelo apresenta etapas detalhadas para resolver o problema.
- suporte multimodalOs usuários podem inserir imagens e texto. Por exemplo, se você carregar um diagrama de circuito e perguntar "How does the circuit work?" (Como o circuito funciona?), o modelo combinará a imagem e a pergunta para gerar uma explicação detalhada.
- Bilíngue chinês-inglêsO modelo suporta entradas mistas em chinês e inglês, o que é adequado para cenários entre idiomas. Por exemplo, insira uma pergunta em chinês e uma descrição de imagem em inglês, e o modelo responderá no idioma especificado.
advertência
- Certifique-se de que a GPU tenha memória suficiente; recomenda-se pelo menos 24 GB.
- Habilite a configuração YaRN para processamento de contexto longo para otimizar o desempenho com o arquivo de configuração
config.jsonacertou em cheio"rope_scaling": {"type": "yarn", "factor": 4.0}. - A velocidade da inferência do modelo depende do hardware, e a placa de vídeo 3090 permite uma resposta em tempo real.
cenário do aplicativo
- pesquisa acadêmica
Os pesquisadores podem usar o GLM-4.1V-Thinking para analisar longos artigos acadêmicos e extrair as principais conclusões ou resumir o conteúdo. O modelo também pode processar imagens experimentais e auxiliar na análise de gráficos de dados. - Suporte educacional
Os alunos podem carregar imagens de problemas de matemática ou de experimentos científicos, e o modelo fornecerá etapas detalhadas para resolver os problemas ou explicações sobre os experimentos, adequadas para o estudo autônomo ou para o ensino. - criação de conteúdo
Os criadores podem inserir imagens ou vídeos para gerar textos descritivos ou scripts criativos. Por exemplo, insira um vídeo de viagem para gerar uma descrição da atração. - aplicativo corporativo
As empresas podem usar o modelo para automação de documentos, como análise de termos de contrato ou geração de relatórios. O suporte bilíngue em inglês e chinês o torna adequado para organizações multinacionais.
QA
- Quais tipos de entrada são compatíveis com o GLM-4.1V-Thinking?
O modelo suporta entradas de imagem, vídeo e texto, e é compatível com imagens 4K e contextos de 64k para tarefas multimodais. - É necessário um hardware de alto desempenho?
Funciona com uma única placa de vídeo RTX 3090, com 24 GB de memória de vídeo recomendada para um raciocínio suave. - Como posso ajustar meu modelo?
Usando o kit de ferramentas LLaMA-Factory, consulte o repositório do GitHub para ofinetune/README.mdconfigure o arquivolora.yamlAjuste fino. - Os modelos são gratuitos?
Sim, o modelo é de código aberto com base na licença MIT, que permite o uso comercial gratuito. - Como posso experimentar o modelo?
Teste rapidamente a funcionalidade do modelo fazendo upload de imagens ou texto por meio do Hugging Face ou da demonstração on-line do ModelScope.