O desenvolvimento de macromodelos multimodais está entrando em uma nova fase, passando do simples reconhecimento de imagens ("ver") para o raciocínio lógico complexo e a compreensão profunda ("ver e pensar"). Recentemente, a Smart Spectrum AI lançou e abriu o código-fonte do GLM-4.1V-Thinking na série GLM-4.1V-9B-Thinking demonstrando novos avanços em suas habilidades cognitivas de ordem superior na modelagem de linguagem visual.
A inovação central do modelo é a introdução de um método chamado Aprendizado por reforço com amostragem de currículo (RLCS, Reinforcement Learning with Curriculum Sampling) estratégia de treinamento. Essa abordagem treina o modelo programando tarefas de fácil a difícil, semelhante ao processo de aprendizado humano, resultando em um progresso significativo em tarefas de raciocínio complexas.
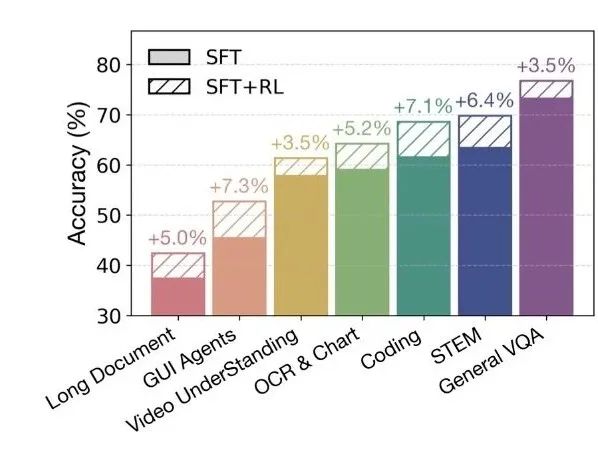
O que mais chama a atenção nele é seu desempenho. Apesar do GLM-4.1V-9B-Thinking Com apenas 9 bilhões de parâmetros, ele iguala ou até excede os 72 bilhões de parâmetros em 18 benchmarks autorizados. Qwen2.5-VL-72BEsse resultado desafia a noção tradicional de que "modelos maiores são mais poderosos". Esse resultado desafia a noção tradicional de que "quanto maior o modelo, mais poderoso ele é" e destaca o grande potencial de arquiteturas de modelos avançados e estratégias de treinamento eficientes para melhorar o desempenho e economizar recursos.

Links para recursos relacionados:
- Dissertação. GLM-4.1V-Thinking: rumo a um raciocínio multimodal versátil com aprendizado por reforço escalonável
- Repositórios de código-fonte aberto.
- Experiência on-line.
- Documentação da API. Plataforma aberta de modelo grande
Demonstração das principais competências e aplicativos do modelo
GLM-4.1V-9B-Thinking Com a introdução do mecanismo Chain-of-Thought, é possível mostrar o processo de raciocínio detalhado durante a emissão da resposta. Isso não só aumenta a precisão e a riqueza das respostas, mas também melhora a interpretabilidade dos resultados. O modelo integra amplos recursos de processamento multimodal por meio de treinamento híbrido.
- Compreensão de vídeo e imagem. A capacidade de analisar até duas horas de vídeo ou conduzir perguntas e respostas detalhadas sobre conteúdo de imagens complexas demonstra uma análise lógica sólida.
- Solução de problemas interdisciplinares. Oferece suporte à resolução de problemas diagramáticos em matemática, física, biologia, química e outras disciplinas, e pode fornecer etapas detalhadas para pensar sobre eles.
- Extração de informações de alta precisão. Reconhece e estrutura com precisão a saída de informações gráficas e de texto em imagens e vídeos.
- Documentação e interação de interface. Ele pode compreender nativamente o conteúdo de documentos nas áreas financeira, governamental e outras, além de reconhecer elementos da GUI e executar comandos como clicar e deslizar, atuando como um "corpo inteligente da GUI".
- Visão para geração de código. Capacidade de escrever automaticamente código de front-end com base em capturas de tela da interface inserida.
Abaixo estão alguns exemplos de aplicações típicas:
Exemplo 1: Análise e raciocínio gráfico
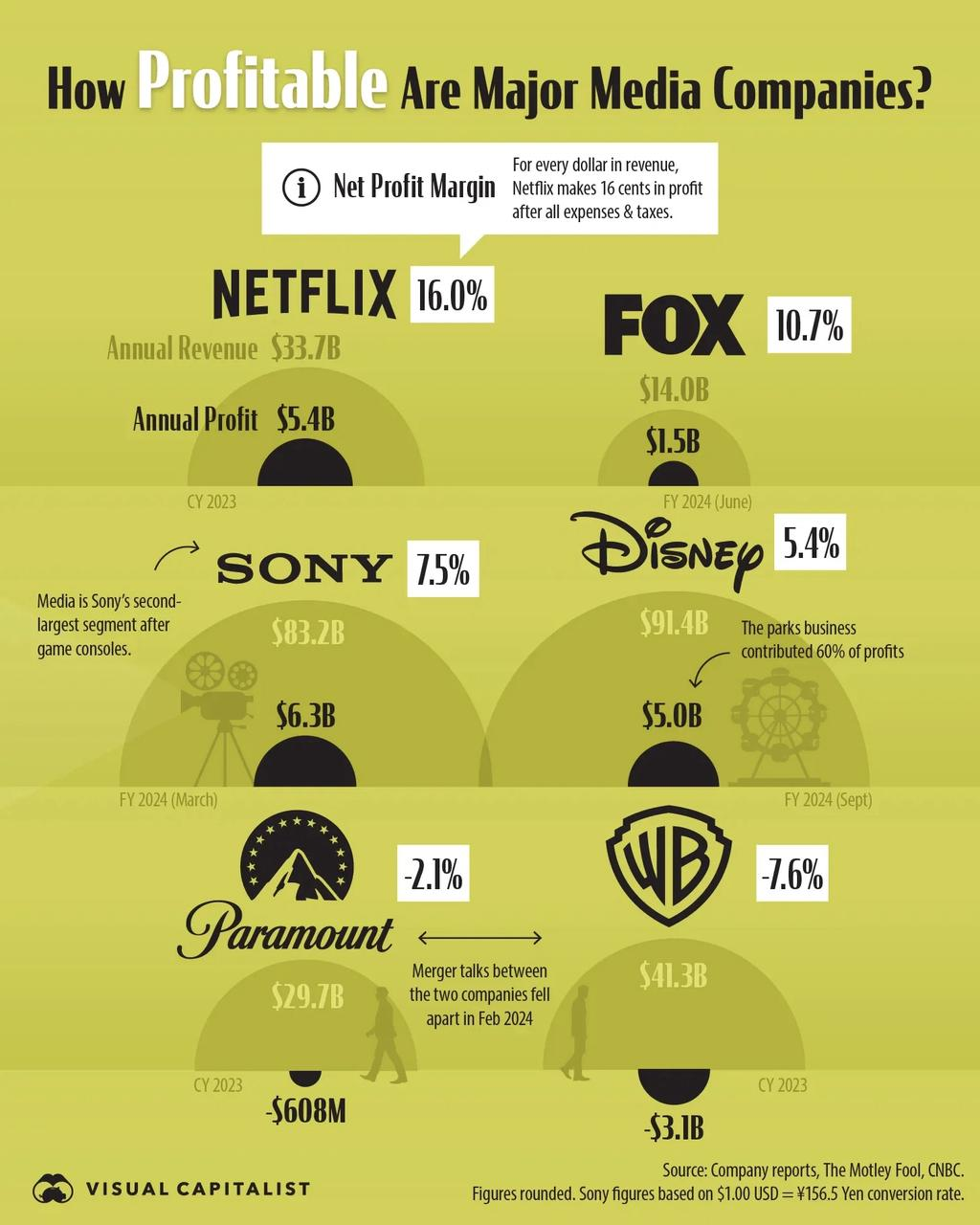
Comando de entrada.
Identifique a empresa com o maior lucro anual nesse gráfico e a maior divisão dessa empresa.
Saída do modelo.
A Sony tem o maior lucro anual, $6.3B. Para a Sony, a nota afirma: "A mídia é o segundo maior segmento da Sony, depois dos consoles de jogos." Portanto, o maior segmento são os consoles de jogos. Assim, o maior segmento é o de consoles de jogos.
Exemplo 2: Como resolver questões de matemática de nível GCE

Comando de entrada.
Por favor, me ajude com esse tópico, fornecendo o processo e a resposta detalhados.
Saída do modelo (processo de raciocínio parcial).
- Sabe-se que PA ⊥ plano ABCD, portanto PA ⊥ AD e PA ⊥ AB.
- Como AB ⊥ AD e a interseção de PA e AB é A, AD ⊥ plano PAB.
- Como AD ⊂ plano PAD, o plano PAB ⊥ plano PAD.
Exemplo 3: Identificação e operação da interface gráfica do usuário (GUI)

Comando de entrada.
No APP, ajude-me a criar uma reunião com o Dr. Smith em uma quinzena, às 15h.
Saídas de modelo (instruções de operação).
Ação: {"action_type": "click", "box_2d": [[27,840,122,885]]}
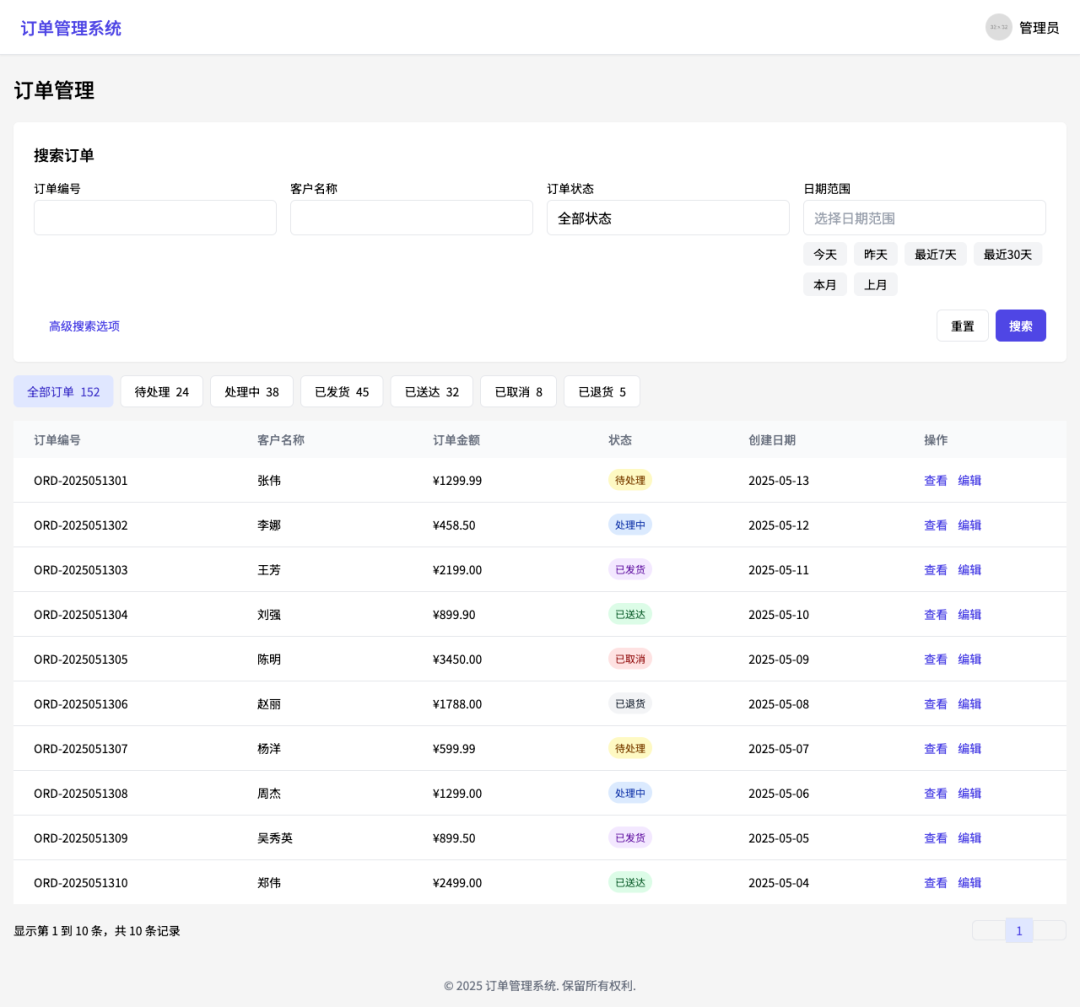
Exemplo 4: De acordo com a imagem para gerar o código web de front-end
Esse recurso demonstra a poderosa capacidade do modelo de traduzir designs visuais diretamente em código utilizável, aumentando consideravelmente a eficiência do desenvolvimento front-end.
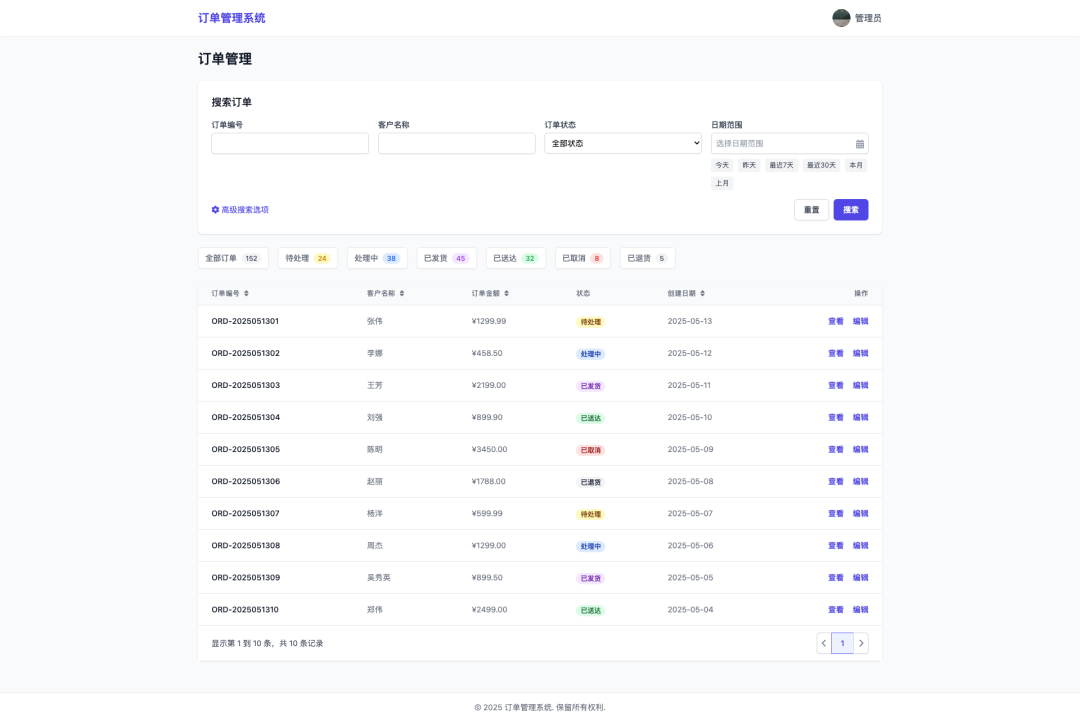
Comando de entrada.
Crie uma página da Web semelhante à imagem de entrada e converta-a em código React.
Código React gerado por modelo.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>订单管理系统</title>
<script src="https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/react-dom@18.0.0/umd/react-dom.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@babel/standalone/babel.js"></script>
<script src="https://cdn.tailwindcss.com"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"></link>
<link href="https://fonts.geekzu.org/css2?family=Noto+Sans+SC:wght@400;500;700&display=swap" rel="stylesheet">
<style>
body {
font-family: 'Noto Sans SC', sans-serif;
background-color: #f5f5f5;
}
</style>
</head>
<body>
<div id="root"></div>
<script type="text/babel">
const Header = () => {
return (
<header className="bg-white shadow-sm py-4 px-6 flex justify-between items-center border-b">
<h1 className="text-xl font-medium text-indigo-600">订单管理系统</h1>
<div className="flex items-center">
<img src="https://placehold.co/32x32" alt="管理员头像" className="w-8 h-8 rounded-full mr-2" />
<span>管理员</span>
</div>
</header>
);
};
const SearchForm = () => {
return (
<div className="bg-white rounded-md shadow-sm p-6 mb-4">
<h2 className="text-lg font-medium mb-4">搜索订单</h2>
<div className="grid grid-cols-1 md:grid-cols-4 gap-4">
<div>
<label className="block text-sm mb-1">订单编号</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">客户名称</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">订单状态</label>
<select className="w-full border rounded-md px-3 py-2 appearance-none bg-white">
<option>全部状态</option>
</select>
</div>
<div>
<label className="block text-sm mb-1">日期范围</label>
<div className="relative">
<input type="text" placeholder="选择日期范围" className="w-full border rounded-md px-3 py-2" />
<div className="absolute right-2 top-2 text-gray-400">
<i className="fas fa-calendar"></i>
</div>
</div>
<div className="flex flex-wrap mt-2 gap-2">
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">今天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">昨天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近7天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近30天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">本月</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">上月</button>
</div>
</div>
</div>
<div className="flex items-center justify-between mt-4">
<a href="#" className="text-indigo-600 flex items-center text-sm">
<i className="fas fa-cog mr-1"></i> 高级搜索选项
</a>
<div className="flex gap-2">
<button className="px-4 py-2 border rounded-md text-sm">重置</button>
<button className="px-4 py-2 bg-indigo-600 text-white rounded-md text-sm">搜索</button>
</div>
</div>
</div>
);
};
const OrderStatusFilters = () => {
const filters = [
{ name: "全部订单", count: 152, active: true },
{ name: "待处理", count: 24, active: false },
{ name: "处理中", count: 38, active: false },
{ name: "已发货", count: 45, active: false },
{ name: "已送达", count: 32, active: false },
{ name: "已取消", count: 8, active: false },
{ name: "已退货", count: 5, active: false },
];
return (
<div className="flex flex-wrap gap-2 mb-4">
{filters.map((filter, index) => (
<button
key={index}
className={`px-4 py-2 rounded-md text-sm ${
filter.active
? "bg-indigo-100 text-indigo-700"
: "bg-white border"
}`}
>
{filter.name} {filter.count > 0 && <span className="ml-1">{filter.count}</span>}
</button>
))}
</div>
);
};
const OrderTable = () => {
const orders = [
{ id: "ORD-2025051301", customer: "张伟", amount: "¥1299.99", status: "待处理", date: "2025-05-13" },
{ id: "ORD-2025051302", customer: "李娜", amount: "¥458.50", status: "处理中", date: "2025-05-12" },
{ id: "ORD-2025051303", customer: "王芳", amount: "¥2199.00", status: "已发货", date: "2025-05-11" },
{ id: "ORD-2025051304", customer: "刘强", amount: "¥899.90", status: "已送达", date: "2025-05-10" },
{ id: "ORD-2025051305", customer: "陈明", amount: "¥3450.00", status: "已取消", date: "2025-05-09" },
{ id: "ORD-2025051306", customer: "赵丽", amount: "¥1788.00", status: "已退货", date: "2025-05-08" },
{ id: "ORD-2025051307", customer: "杨洋", amount: "¥599.99", status: "待处理", date: "2025-05-07" },
{ id: "ORD-2025051308", customer: "周杰", amount: "¥1299.00", status: "处理中", date: "2025-05-06" },
{ id: "ORD-2025051309", customer: "吴秀英", amount: "¥899.50", status: "已发货", date: "2025-05-05" },
{ id: "ORD-2025051310", customer: "郑伟", amount: "¥2499.00", status: "已送达", date: "2025-05-04" },
];
const getStatusClass = (status) => {
switch(status) {
case "待处理": return "bg-yellow-100 text-yellow-800";
case "处理中": return "bg-blue-100 text-blue-800";
case "已发货": return "bg-purple-100 text-purple-800";
case "已送达": return "bg-green-100 text-green-800";
case "已取消": return "bg-red-100 text-red-800";
case "已退货": return "bg-gray-100 text-gray-800";
default: return "bg-gray-100 text-gray-800";
}
};
return (
<div className="overflow-x-auto">
<table className="min-w-full bg-white">
<thead>
<tr className="bg-gray-50 text-left text-sm">
<th className="px-6 py-3 font-medium text-gray-500">订单编号 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">客户名称 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">订单金额 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">状态 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">创建日期 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">操作</th>
</tr>
</thead>
<tbody className="divide-y divide-gray-200">
{orders.map((order, index) => (
<tr key={index} className="hover:bg-gray-50">
<td className="px-6 py-4 text-sm">{order.id}</td>
<td className="px-6 py-4 text-sm">{order.customer}</td>
<td className="px-6 py-4 text-sm">{order.amount}</td>
<td className="px-6 py-4">
<span className={`px-2 py-1 rounded-full text-xs ${getStatusClass(order.status)}`}>
{order.status}
</span>
</td>
<td className="px-6 py-4 text-sm">{order.date}</td>
<td className="px-6 py-4 text-sm">
<button className="text-indigo-600 mr-3">查看</button>
<button className="text-indigo-600">编辑</button>
</td>
</tr>
))}
</tbody>
</table>
</div>
);
};
const Pagination = () => {
return (
<div className="flex items-center justify-between mt-4 text-sm">
<div>显示第 1 到 10 条,共 10 条记录</div>
<div className="flex items-center">
<button className="px-3 py-1 border rounded-l-md">
<i className="fas fa-chevron-left"></i>
</button>
<button className="px-3 py-1 border-t border-b bg-indigo-100 text-indigo-600">1</button>
<button className="px-3 py-1 border rounded-r-md">
<i className="fas fa-chevron-right"></i>
</button>
</div>
</div>
);
};
const Footer = () => {
return (
<footer className="py-4 text-center text-gray-500 text-sm">
© 2025 订单管理系统. 保留所有权利.
</footer>
);
};
const App = () => {
return (
<div className="min-h-screen flex flex-col">
<Header />
<main className="flex-1 max-w-7xl mx-auto w-full px-4 py-6">
<h1 className="text-2xl font-medium mb-6">订单管理</h1>
<SearchForm />
<OrderStatusFilters />
<OrderTable />
<Pagination />
</main>
<Footer />
</div>
);
};
ReactDOM.render(<App />, document.getElementById('root'));
</script>
</body>
</html>
Exemplo 5: Análise de princípios de fenômenos físicos
Comando de entrada.
Qual é o motivo desse fenômeno? Por que há água no copo do meio?
Saída do modelo.
Esse fenômeno se deve ao **fenômeno capilar (ou ação capilar)**. Especificamente: o papel de seda é um material poroso e os espaços entre suas fibras são semelhantes a "capilares". Quando os copos da esquerda e da direita que contêm líquidos de cores diferentes são conectados ao copo vazio no meio por uma toalha de papel, a toalha de papel transportará o líquido vermelho à esquerda e o líquido azul à direita através dos espaços nas fibras até o copo vazio no meio, aproveitando a absorção de água da própria toalha de papel e a capilaridade entre as fibras. À medida que esse processo de transporte prossegue, o copo vazio no meio é gradualmente preenchido com líquido, resultando no fenômeno da "água no copo do meio".
Estrutura técnica e metodologia de treinamento
GLM-4.1V-Thinking O desempenho eficiente decorre de sua arquitetura de modelo refinada e do processo de treinamento em etapas.
arquitetura do modelo
A arquitetura do modelo consiste em três partes: um codificador visual (ViT Encoder), um adaptador (MLP Projector) e um decodificador de linguagem.
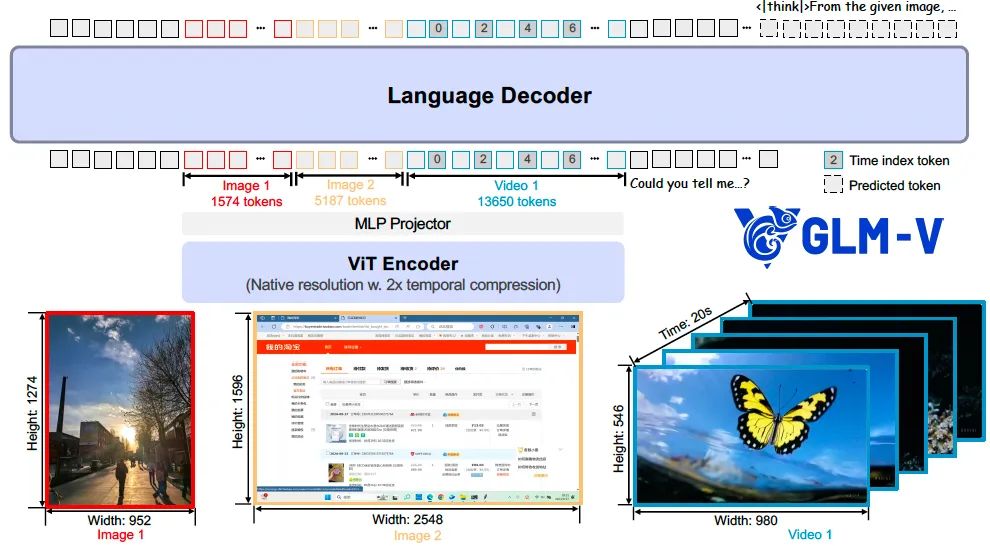
O modelo foi escolhido AIMv2-Huge como um codificador visual, e a convolução 2D é estendida em 3D para lidar eficientemente com a dimensão temporal da entrada de vídeo. Dois aprimoramentos importantes são introduzidos no modelo para aumentar sua adaptabilidade a imagens de resolução e proporção arbitrárias:
- Codificação de posição rotacional bidimensional (2D-RoPE). Essa tecnologia ajuda o modelo a entender melhor as relações espaciais em uma imagem, permitindo que ele estabilize proporções extremas acima de 200:1 e imagens de alta resolução acima de 4K.
- Adaptação dinâmica da resolução. Ao preservar a incorporação posicional absoluta do modelo pré-treinado do ViT e combiná-lo com o método de interpolação bicúbica, o modelo pode ser adaptado dinamicamente a entradas de diferentes resoluções durante o treinamento.
Na parte do decodificador de linguagem, o modelo estende a codificação de posição rotacional (RoPE) original para Codificação de posição rotacional tridimensional (3D-RoPE)que aprimora significativamente a compreensão espacial do modelo ao processar entradas mistas de gráfico e vídeo sem afetar o desempenho do processamento de texto simples.
Processo de treinamento
O treinamento do modelo é dividido em três etapas: pré-treinamento, ajuste fino supervisionado (SFT) e aprendizado por reforço (RL).
- Fase de pré-treinamento. Ele é dividido em duas subfases: pré-treinamento multimodal genérico e treinamento contínuo de contexto longo. O primeiro tem como objetivo estabelecer uma compreensão multimodal básica; o segundo amplia o comprimento da sequência de processamento do modelo para 32.768, introduzindo sequências de quadros de vídeo e conteúdo gráfico muito longo para aprimorar o processamento de vídeos longos e de alta resolução.
- Fase de ajuste fino supervisionado (SFT). Nessa fase, o modelo é totalmente ajustado parametricamente usando um conjunto de dados de alta qualidade do Chain of Thought (CoT). Todas as amostras de treinamento estão em um formato uniforme, forçando o modelo a aprender a gerar processos de raciocínio detalhados em vez de dar respostas diretas.
<think> {推理过程} </think> <answer> {最终答案} </answer>Essa etapa fortalece efetivamente a capacidade do modelo de raciocinar causalmente durante longos períodos de tempo.
- Estágio de Aprendizagem Intensiva de Amostragem de Curso (RLCS). Essa é a chave para melhorar o desempenho do modelo. Com base no modelo de ajuste fino supervisionado, a equipe de desenvolvimento combinou o Aprendizado por Reforço baseado em Recompensas Verificáveis (RLVR) e o Aprendizado por Reforço baseado em Feedback Humano (RLHF). Usando um mecanismo de "amostragem de curso", o modelo começa com tarefas simples em várias dimensões, como resolução de problemas STEM, interação com GUI e compreensão de documentos, e passa gradualmente para tarefas complexas. Esse paradigma de aprendizado dinâmico, de fácil a difícil, otimiza o desempenho do modelo em termos de utilidade, precisão e estabilidade.