Easy Dataset: uma ferramenta fácil para criar grandes conjuntos de dados com ajuste fino de modelos
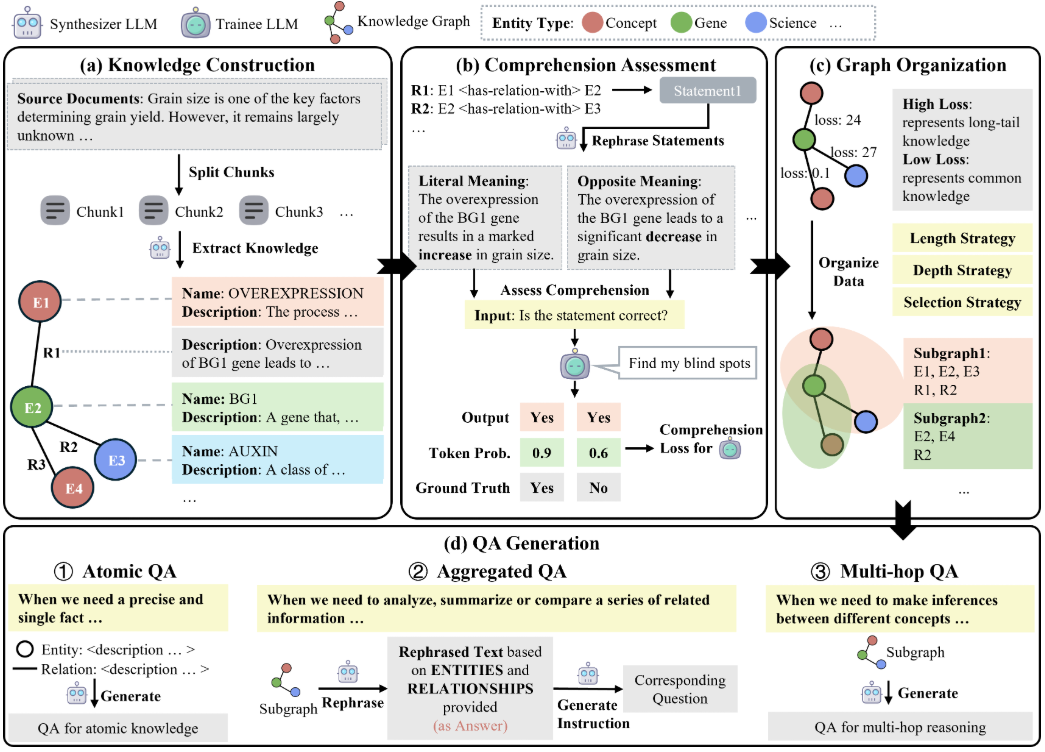
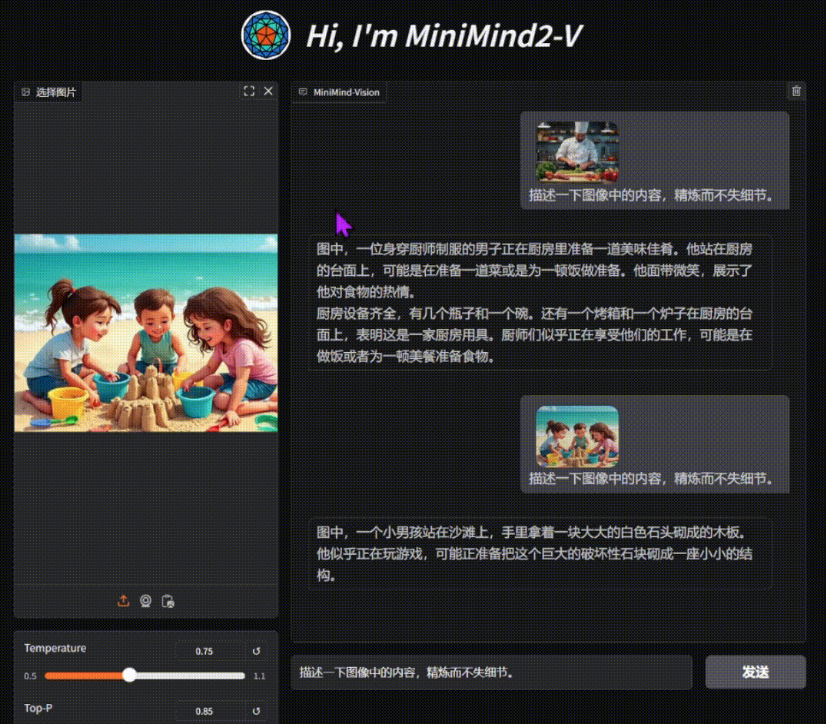
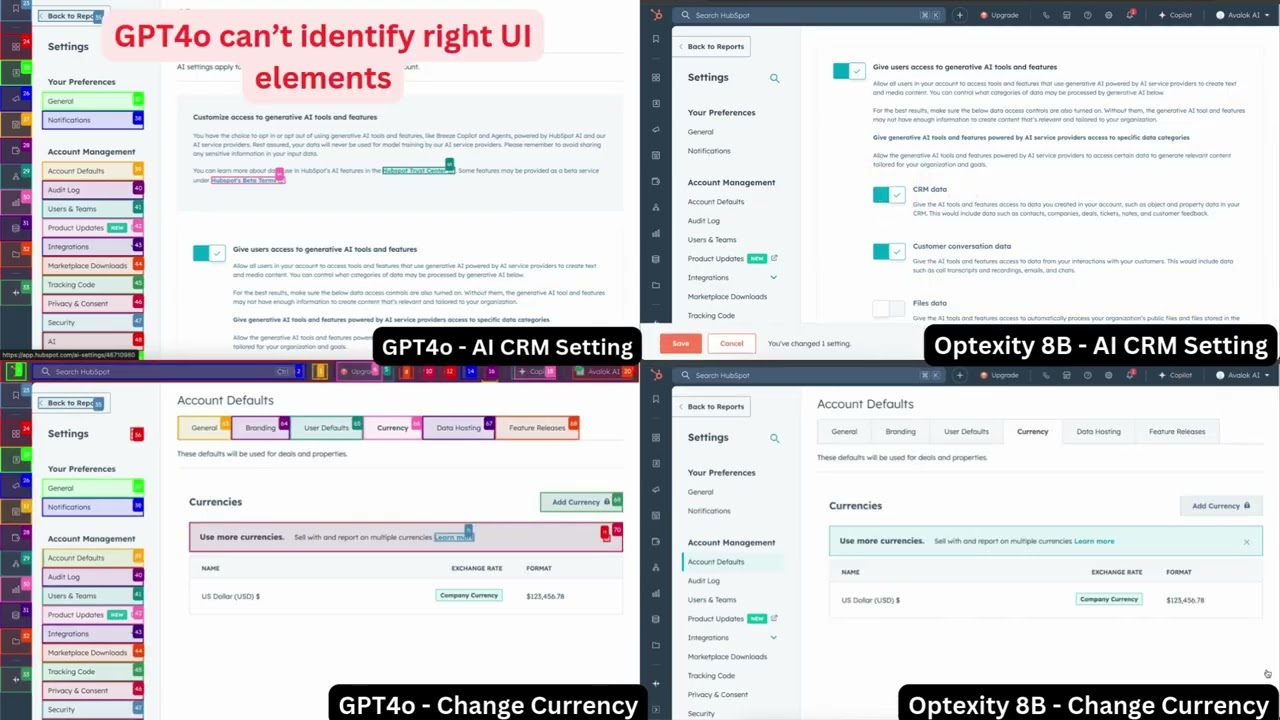
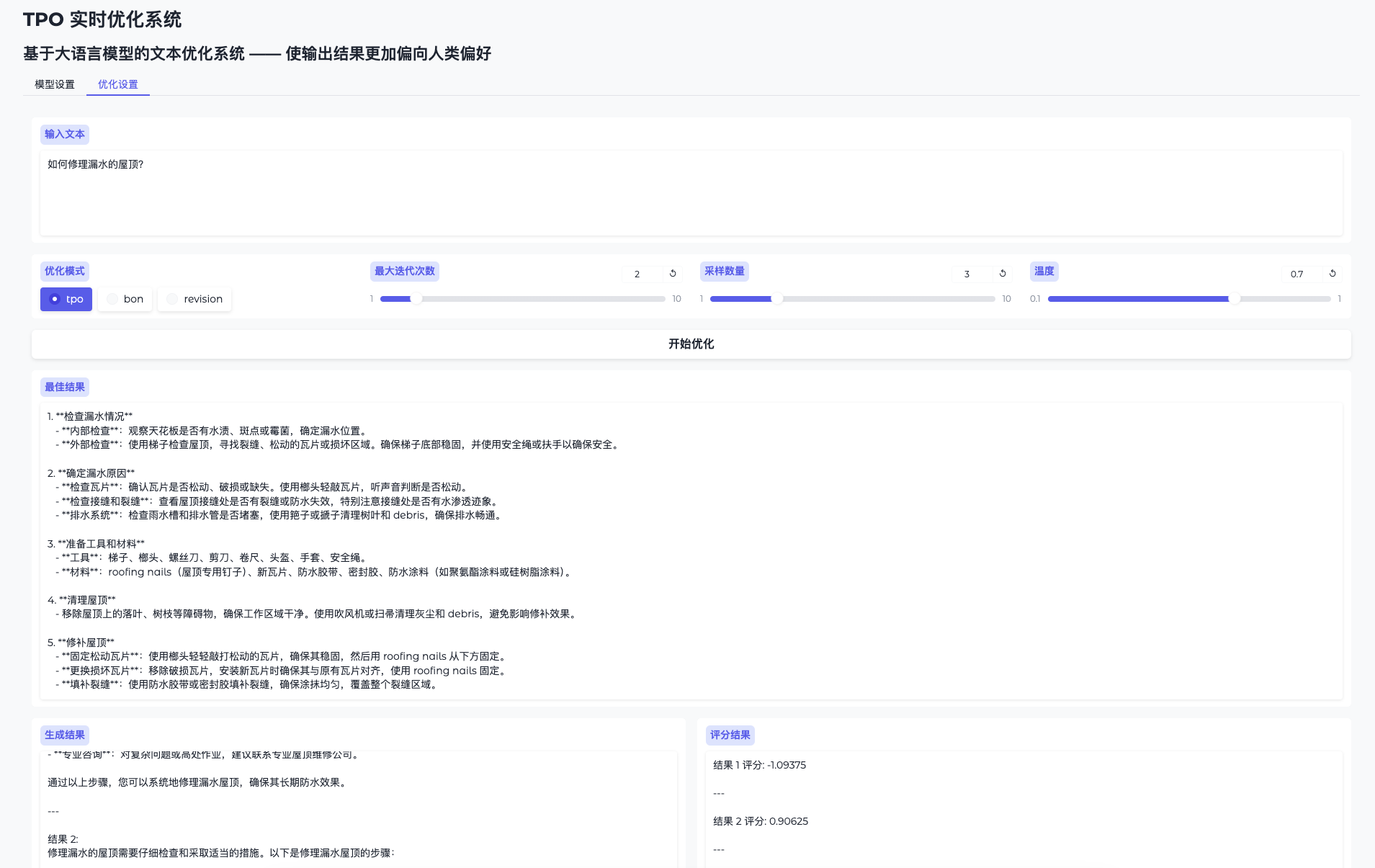
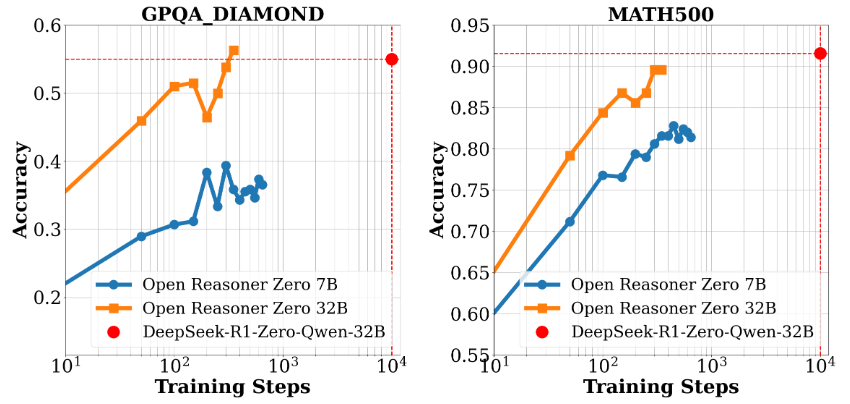
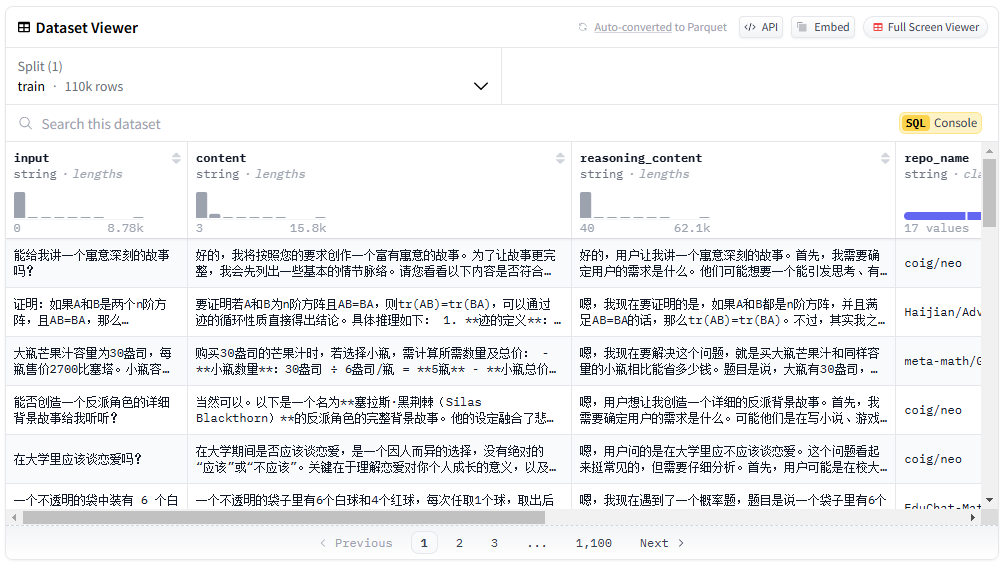
O Easy Dataset é uma ferramenta de código aberto projetada especificamente para o ajuste fino de modelos grandes (LLMs), hospedada no GitHub. Ela oferece uma interface fácil de usar que permite aos usuários fazer upload de arquivos, segmentar automaticamente o conteúdo, gerar perguntas e respostas e, por fim, gerar conjuntos de dados estruturados adequados para o ajuste fino. O desenvolvedor, Cona...