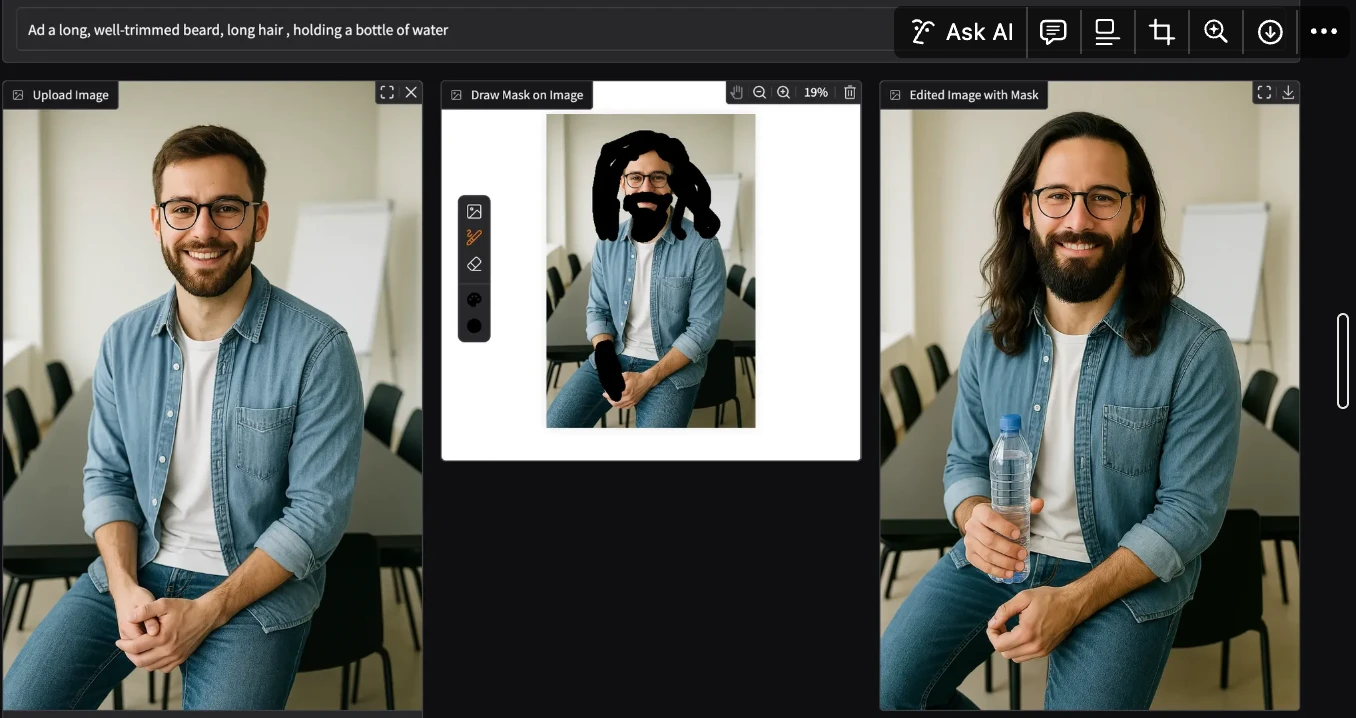
近期,AI 智能体记忆领域的一则声明引发了业界的广泛关注。Mem0 公司发布研究报告,宣称其产品在 AI 智能体记忆技术方面达到了行业领先(SOTA)水平,并在特定基准测试中超越了包括 Zep 在内的竞争对手。然而,这一说法迅速遭到了 Zep 团队的质疑。Zep 指出,在正确实施的情况下,其产品在 Mem0 选用的 LoCoMo 基准测试中,性能实际上要高出 Mem0 大约 24%。这一显著差异,促使人们对基准测试的公正性、实验设计的严谨性以及最终结论的可靠性进行更深入的探究。
在人工智能这个竞争激烈的赛道,获得 SOTA (State-of-the-Art) 的称号对任何公司而言都意义重大。它不仅意味着技术上的领先,更能吸引投资、人才和市场关注。因此,任何关于 SOTA 的声明,尤其是通过基准测试得出的结论,都理应受到严格的审视。
Zep 声称:正确实施下,LoCoMo 测试结果反转
Zep 团队在其回应中指出,当 LoCoMo 实验按照其产品的最佳实践进行配置时,结果与 Mem0 报告大相径庭。

除本文讨论的 "Zep (Correct)" 外,所有分数均来自 Mem0 报告。
根据 Zep 公布的评估,其产品 J 分数达到了 84.61%,相较于 Mem0 最佳配置(Mem0 Graph)的约 68.4%,实现了约 23.6% 的相对性能提升。这与 Mem0 论文中报告的 Zep 65.99% 的得分形成鲜明对比,Zep 认为这很可能是由于下文将讨论的实施错误直接导致的。
在**搜索延迟(p95 搜索延迟)**方面,Zep 指出,当其系统为并发搜索正确配置时,p95 搜索延迟为 0.632 秒。这优于 Mem0 报告中 Zep 的 0.778 秒(Zep 推测该数据因其顺序搜索实施而被夸大),并略快于 Mem0 的图形搜索延迟(0.657 秒)。

除本文讨论的 "Zep (Correct)" 外,所有分数均来自 Mem0 报告。
值得注意的是,Mem0 的基础配置(Mem0 Base)显示出更低的搜索延迟(0.200 秒)。但这并非一个完全对等的比较,因为 Mem0 Base 使用的是一个更简单的向量存储/缓存,不具备图形数据库的关系能力,并且它在 Mem0 的各种变体中准确性得分也是最低的。对于需要更复杂记忆结构、追求响应速度的生产级 AI 智能体而言,Zep 高效的并发搜索展示了强大的性能。Zep 方面说明,其延迟数据是在 AWS us-west-2 环境下,通过 NAT 设置进行传输测量的。
LoCoMo 基准测试的局限性引发质疑
Mem0 选择 LoCoMo 作为其研究的基准测试,这一决策本身也受到了 Zep 的审视,后者认为该基准在设计和执行层面存在若干根本性缺陷。设计和执行一个全面且无偏差的基准测试本身就是一项艰巨的任务,它需要深厚的专业知识、充足的资源以及对被测系统内部机制的透彻理解。
Zep 团队指出的 LoCoMo 的主要问题包括:
- 对话长度与复杂度不足:LoCoMo 中的对话平均长度在 16,000 到 26,000 Tokens 之间。虽然这看起来很长,但对于现代 LLM 而言,这通常在其上下文窗口能力范围之内。这种长度未能真正对长期记忆检索能力构成压力。一个有力的证据是,Mem0 自己的结果显示,其系统的表现甚至不如一个简单的“全上下文基线”(即将整个对话内容直接输入 LLM)。全上下文基线的 J 分数约为 73%,而 Mem0 的最佳分数约为 68%。如果简单提供所有文本就能获得比专业记忆系统更好的结果,那么该基准测试就未能充分考察真实世界 AI 智能体交互中对记忆能力的严苛要求。
- 未能测试关键记忆功能:该基准缺乏旨在测试“知识更新”的问题。对于 AI 智能体记忆而言,信息随时间变化(例如用户更换工作)后的记忆更新是一项至关重要的功能。
- 数据质量问题:数据集本身存在多项质量瑕疵:
- 无法使用的类别:由于缺少标准答案,类别 5 无法使用,迫使 Mem0 和 Zep 在评估中都排除了这一类别。
- 多模态错误:部分问题针对图像提问,但必要信息并未出现在数据集创建过程中由 BLIP 模型生成的图像描述中。
- 错误的说话者归属:一些问题错误地将行为或陈述归因于错误的说话者。
- 问题定义不明确:某些问题含糊不清,可能有多个潜在的正确答案(例如,询问某人何时去露营,而此人可能在七月和八月都去过)。
考虑到这些错误和不一致之处,LoCoMo 作为衡量 AI 智能体记忆性能的权威标准的可靠性值得商榷。不幸的是,LoCoMo 并非个例。其他一些基准测试,如 HotPotQA,也曾因使用 LLM 训练数据(如维基百科)、问题过于简单化以及事实错误等问题而受到诟病。这凸显了在 AI 领域进行稳健基准测试所面临的持续挑战。
Mem0 对 Zep 评估方法受到的指责
除了 LoCoMo 基准自身的争议外,Mem0 论文中对 Zep 的比较,据 Zep 方面称,是基于一种有缺陷的实施方式,从而未能准确反映 Zep 的真实能力:
- 错误的用户模型:Mem0 使用了一个为单个用户-助手交互设计的用户图结构,但却将用户角色分配给了对话中的双方参与者。这很可能混淆了 Zep 的内部逻辑,使其将对话视为单个用户在不同消息间身份不断切换。
- 不恰当的时间戳处理:时间戳通过附加到消息末尾的方式传递,而非使用 Zep 专用的 created_at 字段。这种非标准方法会干扰 Zep 的时序推理能力。
- 顺序搜索与并行搜索:搜索操作是按顺序执行而非并行执行,这人为地夸大了 Mem0 报告中 Zep 的搜索延迟。
Zep 认为,这些实施错误从根本上曲解了 Zep 的设计运作方式,不可避免地导致了 Mem0 论文中所报告的欠佳性能。
行业呼唤更优的基准测试:Zep 为何青睐 LongMemEval
LoCoMo 引发的争议,更加凸显了行业对更稳健、更贴近现实的基准测试的需求。Zep 团队表示更倾向于像 LongMemEval 这样的评估标准,因为它在多个方面弥补了 LoCoMo 的不足:
- 长度与挑战性:包含明显更长的对话(平均 115k Tokens),真正考验上下文极限。
- 时序推理与状态变化:明确测试对时间的理解以及处理信息变化(知识更新)的能力。
- 质量:由人工策划和设计,旨在保证高质量。
- 企业相关性:更能代表真实世界企业级应用的复杂性和需求。

据报道,Zep 在 LongMemEval 上展现了强劲的性能,与基线相比,在准确性和延迟方面均取得了显著改进,尤其是在多会话综合和时序推理等复杂任务上。
进行基准测试是一项复杂的工作,评估竞争对手产品时更需勤勉尽责和专业知识,以确保比较的公平性和准确性。从 Zep 提出的详细反驳来看,Mem0 声称的 SOTA 性能,似乎是建立在一个存在缺陷的基准测试(LoCoMo)和对竞争对手系统(Zep)的错误实施之上。
当在同一基准测试下得到正确评估时,Zep 在准确性上显著优于 Mem0,并且在搜索延迟方面表现出高度竞争力,尤其是在比较基于图的实现时。这种差异凸显了严谨实验设计和深入理解被评估系统对于得出可信结论的至关重要性。
展望未来,AI 领域迫切需要更好、更具代表性的基准测试。行业观察者也鼓励 Mem0 团队在如 LongMemEval 这样更具挑战性和现实意义的基准上评估其产品(Zep 已在此类基准上公布了其结果),以便就 AI 智能体的长期记忆能力进行更有意义的横向比较。这不仅关乎个别产品的声誉,更关系到整个行业技术进步方向的正确指引。