最近发现了一个开源项目,它提供了一种很好的 RAG 思路,它将 DeepSeek-R1 的推理能力结合 Agentic Workflow 应用于 RAG 检索
项目地址
https://github.com/deansaco/r1-reasoning-rag.git
项目通过结合 DeepSeek-R1、Tavily 和 LangGraph,实现了由 AI 主导的动态信息检索与回答机制,利用 deepseek 的 r1 推理来主动地从知识库中检索、丢弃和综合信息,以完整回答一个复杂问题
新旧 RAG 对比
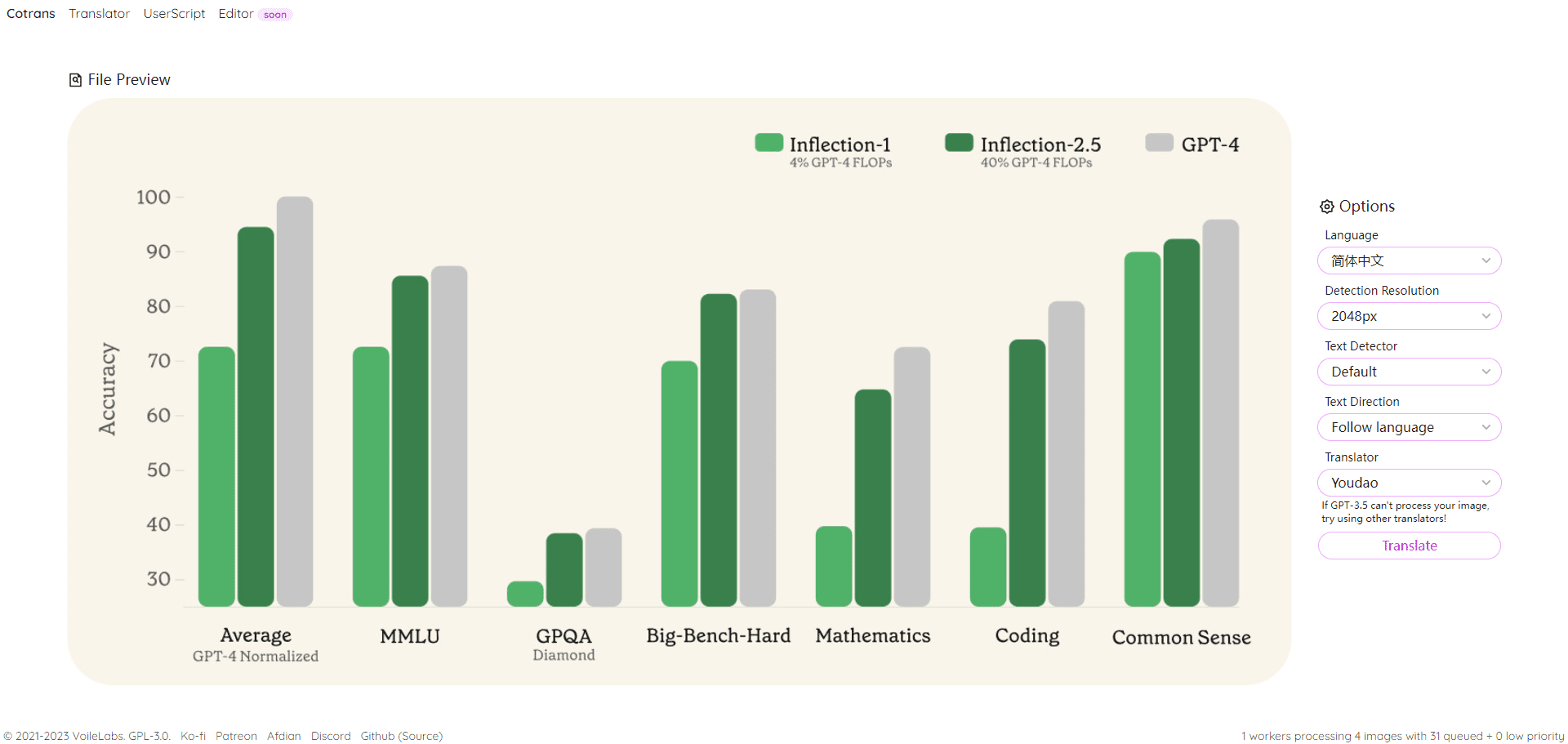
传统的 RAG(检索增强生成)做法有点死板,通常是在处理完搜索后,通过相似性搜索找到一些内容,再按匹配度重新排个序,选出看起来靠谱的信息片段给到大型语言模型(LLM)去生成答案。但这么做特别依赖于那个重排序模型的质量,要是这模型不给力,就容易漏掉重要信息或者把错的东西传给 LLM,结果出来的答案就不靠谱了。
现在 LangGraph 团队对这个过程做了大升级,用上了 DeepSeek-R1 的强大推理能力,把以前那种固定不动的筛选方式变成了一个更灵活、能根据情况调整的动态过程。他们把这个叫做“代理检索”,这种方式让 AI 不仅能主动发现缺少的信息,还能在找资料的过程中不断优化自己的策略,形成一种循环优化的效果,这样交给 LLM 的内容就更加准确了。
这种改进实际上是把测试时扩展的概念从模型内部推理应用到了 RAG 检索中,大大提高了检索的准确性和效率。对于搞 RAG 检索技术的人来说,这个新方法绝对值得好好研究一下!
核心技术与亮点
DeepSeek-R1 推理能力
最新的 DeepSeek-R1 是一款强大的推理模型
- 深度思考分析资讯内容
- 对现有内容进行评估
- 通过多轮推理辨别缺失的内容,以提高检索结果的准确性
Tavily 即时资讯搜索
Tavily 提供即时的资讯搜索,能使大模型过去最新的资讯,扩展模型的知识范围
- 可动态检索来铺冲缺失的资讯内容,而非仅仅依靠静态数据
LangGraph 递归检索(Recursive Retrieval)
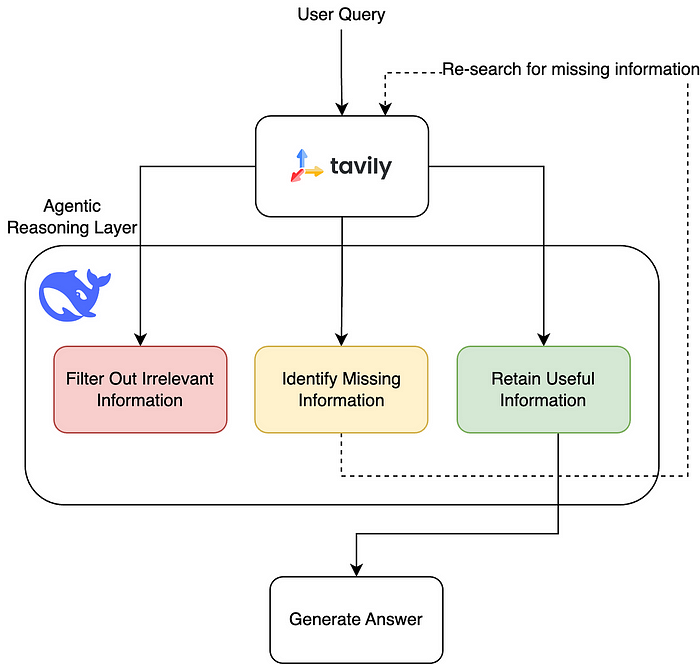
透过 Agentic AI 机制,让大模型在多轮检索与推理后形成闭环学习,大致流程如下:
- 第一步检索问题相关的资讯
- 第二步分析资讯内容是否足够以回答问题
- 第三步如果资讯不足,则进行进一步查询
- 第四步过滤不相关的内容,只保留有效的资讯
这样的 递归式 检索机制,确保大模型能够不断优化查询结果,使得过滤后的资讯更加完整与准确
源码分析
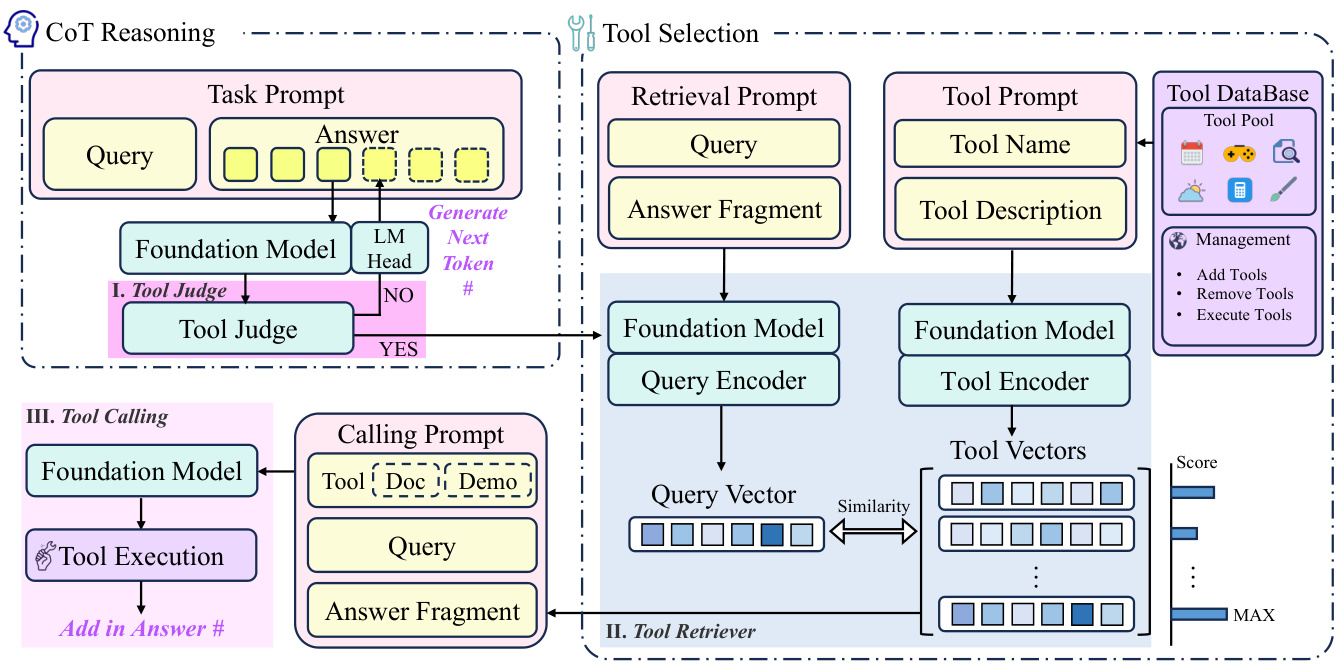
从源码上来看,就很简单的三个文件:agent、llm、prompts
Agent
这部分的核心思路在于 create_workflow 这个函数
 它定义了这个
它定义了这个 workflow 的节点,其中 add_conditional_edges 部分定义的是条件边,整个处理思路就是一开始看到的那张图的递归逻辑
如果不熟悉 LangGraph 的话,可以查看一下相关的资料。
LangGraph 构造的是个图的数据结构,有节点(node) 和边(edge),那它的边也可以是带条件的。
每次检索后,都会通过大模型进行筛查,过滤掉没用的信息(Filter Out Irrelevant Information),保留有用的信息(Retain Useful Information),对于缺失的信息(Identify Missing Information)就再进行一次检索,然后重复这个过程直到找到想要的答案
prompts
这里主要定义了两个提示词。VALIDATE_RETRIEVAL :它用于验证检索到的信息是否能够回答给定的问题。该模板有两个输入变量:retrieved_context(检索到的上下文)和 question(问题)。其主要目的是生成一个JSON格式的响应,根据提供的文本块来判断它们是否包含能够回答问题的信息。 
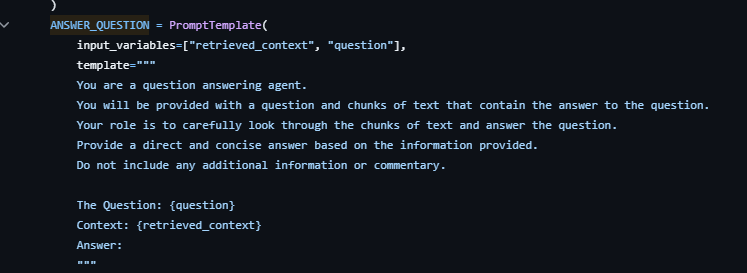
ANSWER_QUESTION:用于指导一个问答代理(question answering agent)根据提供的文本块来回答问题。该模板同样有两个输入变量:retrieved_context(检索到的上下文)和 question(问题)。其主要目的是基于给定的上下文信息提供一个直接且简洁的答案。
llm
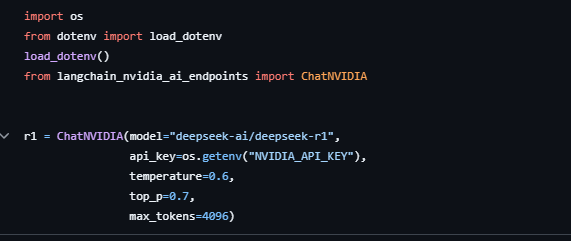
这里很简单就是定义使用的 r1 模型
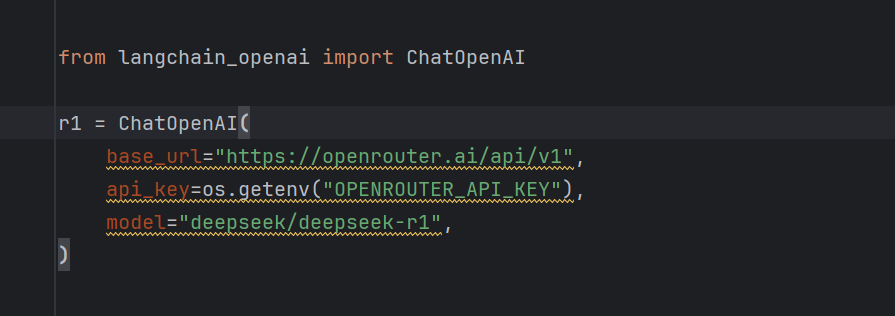
可以改用其他厂商提供的模型,例如 openrouter 的免费 r1 模型
测试效果
我这里单独写了一个脚本,没有使用项目中的,问一下 《哪吒2》中哪吒的师傅的师傅是谁
首先它会先调用搜索去查资料,然后开始验证

接着它会开始分析,并得到 哪吒的师父是太乙真人 这个有效信息,而且也发现了缺失的信息 太乙真人的师父(即哪吒的师祖)的具体身份或名字

接着它就会去继续搜索缺失的信息,并继续对搜索回来的信息进行分析校验

后面因为我这边网络断了,就报错了,但是从上图可以看到,它应该是可以找到这个关键的信息了