大規模言語モデル(LLM)のAPIコールから、自律的で目標駆動型のエージェント型ワークフローまで、AIアプリケーションのパラダイムに根本的な変化が起きている。オープンソースコミュニティはこの波において重要な役割を果たし、特定の研究タスクに特化した多数のAIツールを生み出した。これらのツールはもはや単一のモデルではなく、計画、コラボレーション、情報検索、ツール呼び出し機能を統合した複雑なシステムである。本稿では、代表的なオープンソースの研究支援ツール10製品について、その技術的道筋、設計思想、AIエコシステムにおける戦略的位置づけを分析する。
マルチ・エージェント・システム(MAS):構造化されたコラボレーションと動的適応
マルチ・エージェント・システム(MAS)は、複数の独立したインテリジェンスが協働できるようにすることで、単一のインテリジェンスでは対処が難しい複雑な問題を解決する。DeerFlowとOWLは、この分野で支配的な2つの実装経路(階層型と分散型)を示している。
DeerFlowは階層的で構造化されたコラボレーションモデルです。DeerFlowはシステムをCoordinator、Planner、Expert Teamsに分解し、組織化された企業構造に似せて設計されている。ワークフローは決定論的で、プランナーがタスクを分解し、コーディネーターがタスクを割り当て、エキスパート・インテリジェンスが実行する。このモデルの利点は、効率的に分解できる明確な境界のあるタスクを扱う場合、非常に効率的で予測可能であることです。例えば、大規模なコードベースのセキュリティ監査を実行する場合、DeerFlowは、コード解析や脆弱性検出のような異なる役割を持つインテリジェンスにタスクを安定的に割り当て、レポートを集約することができます。

プロジェクトの住所https://github.com/bytedance/deer-flow
OWLは、分散型で動的に適応するコラボレーションの哲学を体現している。これはCAMEL-AIフレームワークに基づいており、インテリジェンス間の「ロールプレイング」と「コミュニケーションとネゴシエーション」が中心となっている。DeerFlowのあらかじめ定義された役割分担とは異なり、OWLのインテリジェンスは、タスクのリアルタイムの進捗に応じて、動的に交渉し、異なる役割を担うことができる。この創発的コラボレーションモデルは、オープンエンドで構造化されていない問題(例えば、学際的な科学的探究)を扱う場合に有利である。OWLの柔軟性は、予測可能性を犠牲にすることになるが、これはマルチインテリジェントシステムの設計における中心的なトレードオフである。

プロジェクトの住所https://github.com/camel-ai/owl
高度検索拡張世代(Advanced RAG):情報検索から知識探索へ
検索補強型生成(RAG)は、モデルの錯覚を緩和し、リアルタイムの情報を導入するための標準的な手法となっており、WebThinkerとSearch-R1は、これを単純な「検索生成」モデルから、より高度な「エージェント探索」へと発展させた。WebThinkerとSearch-R1は、単純な "検索生成 "モデルから、より高度な "エージェント探索 "へと発展させた。
WebThinkerの核となる画期的な点は、LLMに自律的なブラウジングを与える機能である。検索エンジンの結果ページ(SERP)やベクターデータベースからテキストスニペットを抽出するだけの従来のRAGの範囲を超え、リンクをクリックしてウェブページの内容を深く掘り下げる人間のユーザーの行動を模倣することができる。そのクローズドループの「思考-検索-書き込み」プロセスは、基本的に詳細な推論トレースを生成し、強化学習によって最適化される。これにより、情報の深さと広さの両方を必要とする世論分析や業界追跡タスクにおいて、より包括的な知識イメージを構築することができる。

プロジェクトの住所https://github.com/RUC-NLPIR/WebThinker
Search-R1は、「検索のためのメタ認知」に焦点を当てている。これは固定的な検索エージェントではなく、検索エージェントを構築・評価するためのモジュラーフレームワークである。ユーザは、LLaMA3、Qwen2.5などの異なる大規模言語モデルと、PPO、GRPOなどの強化学習アルゴリズムを、サーバを構成するように自由に組み合わせることができる。このメタレベルの抽象化により、開発者は検索結果そのものに満足するのではなく、AIがどのように検索を学習するのかという根本的な問題を探求することができ、強力な研究ツールとなる。

プロジェクトの住所https://github.com/PeterGriffinJin/Search-R1
エッジ・インテリジェンスとデータ主権:ローカライズされたAIの台頭
AlitaとAgenticSeekは、データプライバシーと応答性に対する要求が高まる中、AIコンピューティングをクラウドからエッジへと押し進めるソリューションの代表格である。
Alitaのコアコンセプトは、標準化されたインターフェースを通じてツールの統合と再利用を簡素化することである。そのモデルコンテキストプロトコル(MCP)は、「AIツールのためのアプリケーションバイナリインターフェース(ABI)」として理解することができる。異なるツールに対して統一されたインタラクションフォーマットを定義することで、Alitaは新しいツールごとに複雑な適合を行うことなく、迅速なアクセスと機能拡張を可能にする。この "プラグアンドプレイ "の性質により、単一モジュールの推論アーキテクチャは、自己進化の可能性を強く持ちながら軽量であり続けることができ、個人や小規模チームのための複雑なAIアプリケーションを構築する障壁を大幅に低減します。
プロジェクトの住所https://github.com/CharlesQ9/Alita
AgenticSeekはデータ主権を極限まで高めている。このAIエージェントは、完全にローカル・デバイス上で動作し、クラウドAPI呼び出しに依存しないため、データがローカル・エリア外に出ることはない。その内部タスク・インテリジェンス・マッチング・メカニズムは、軽量なデバイス側の「MoE(Mixture of Experts)」モデルと考えることができ、タスクのタイプ(ブラウジング、コーディング、プランニング)に基づいて、最も適切なローカル・リソースをインテリジェントにスケジューリングする。これにより、金融データや医療データなど機密性の高いデータを扱う場合や、オフライン環境で作業する場合に、何物にも代えがたい優位性を発揮する。
プロジェクトの住所https://github.com/Fosowl/agenticSeek
解き放たれるモデリング能力:教師あり微調整対強化学習の経路論争
SimpleDeepSearcherとReCallは、それぞれ2つの主流技術の革新的な応用である。
SimpleDeepSearcherは、高品質な教師ありファインチューニング(SFT)が、これまで強化学習(RL)でしか達成できないと考えられていた複雑な研究能力も同等に達成できることを証明した。その成功の鍵は、学習データの構築方法にある。単純な(入力、最終出力)データのペアを使用する代わりに、実際のウェブページのやりとりをシミュレートすることで、中間ステップと意思決定プロセスを含む「推論の軌跡」データを生成する。この "思考プロセス "の模倣は、強化学習探索でゼロから始めるよりも低コストで安定的であり、限られたリソースで高性能な特殊モデルを訓練するための貴重な近道を提供する。

プロジェクトの住所https://github.com/RUCAIBox/SimpleDeepSearcher
ReCallは純粋な強化学習経路に焦点を当て、「道具の使い方を学習する」LLMの汎化能力に取り組んでいる。その最大の特徴は、手動でラベル付けされたツール呼び出しデータを必要としないことである。このモデルは、環境(APIエンドポイントなど)との直接的な相互作用を通じて、返された結果(成功、失敗、エラーメッセージ)からフィードバックを受け取り、これを学習シグナルとして使用して、ツール呼び出し戦略を継続的に最適化する。これはAIフィードバックからの強化学習(RLAIF)に類似しており、複雑なタスクフローにおいてOpenAIスタイルのツールを呼び出すことをモデルが自律的に学習することを可能にする。この機能は、汎用AI(AGI)の実現に向けた重要なステップである。
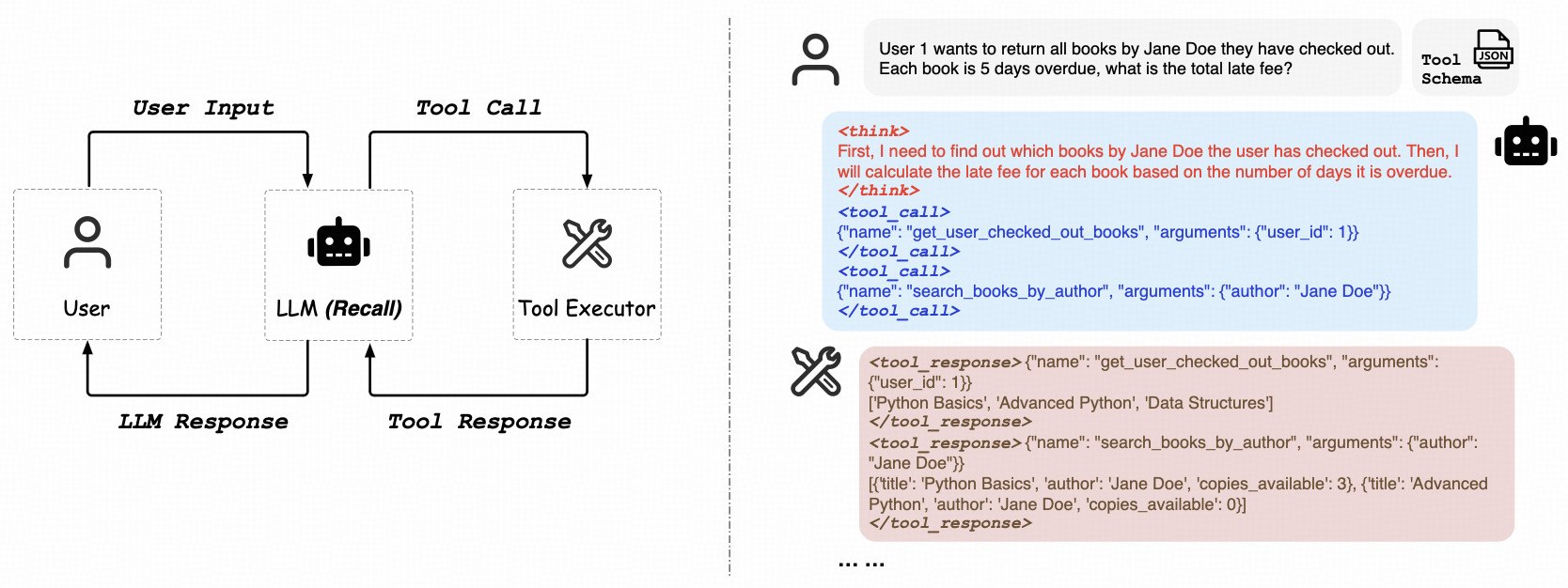
プロジェクトの住所https://github.com/Agent-RL/ReCall
エンド・ツー・エンドのプラットフォームと研究の厳密性
基礎となる機能が成熟するにつれ、複数の機能をエンド・ツー・エンドのプラットフォームに統合し、アウトプットの信頼性を確保することが、より高いレベルで追求されるようになる。
Sunaは「AIネイティブなワークフローIDE」と位置づけられている。Sunaは、基礎となるAI技術の革新に焦点を当てるのではなく、開発者のエクスペリエンス(DX)を向上させることに重点を置いている。ウェブブラウジング、ファイル処理、コマンドライン実行、さらにはウェブサイトのデプロイまでをシームレスに統合することで、Sunaは技術ワークフローにおいて異なるツールを切り替えるコストをなくすことを目指している。開発者向けのZapierやMakeのようなもので、プロジェクト管理と実行の全プロセスにAI機能を深く統合している。

プロジェクトの住所https://github.com/kortix-ai/suna
一方、DeepResearcherは、本格的な研究におけるAIの最大の課題である「信頼性」に直接取り組んでいる。DeepResearcherは、エンドツーエンドの強化学習を用いてモデルを訓練し、厳密な研究戦略を構築する。その核となる「自己反省」メカニズムは、一種の「認識的謙虚さ」を表している。モデルが複数の情報源を検証してもなお確信度の高い結論に到達できない場合、多くのモデルのように自信満々に幻覚を見るのではなく、積極的に「わからないことを認める」ことを選択する。このような不確実性に対する認識と誠実さは、AIが「情報生成者」から信頼できる「研究パートナー」へと変貌するために必要な資質である。