OntoCastはGitHubでホストされているオープンソースのフレームワークで、ドキュメントからセマンティックトリプルを抽出して知識グラフを構築することに重点を置いている。オントロジー管理、自然言語処理、ナレッジグラフのシリアライゼーション技術を組み合わせ、非構造化テキストを構造化されたクエリ可能なデータに変換する。OntoCastはオントロジー駆動型の抽出を使用して意味的一貫性を確保し、テキスト、JSON、PDF、Markdownなど様々なファイル形式をサポートする。ユーザーはネイティブまたはREST APIを介して使用することができ、OpenAIまたはネイティブモデル(Ollama経由など)のいずれかをサポートする。OpenAIまたはネイティブモデル(例えばOllama経由)。複雑なドキュメントから構造化された情報を抽出する必要があるシナリオのための、自動化されたオントロジーの作成、エンティティの曖昧性解消、セマンティック・チャンキングが主な機能です。プロジェクトは、迅速なデプロイと使用のために、詳細なドキュメントとDocker設定を提供します。
機能一覧
- 意味的三項対立の抽出:知識グラフを構築するために文書から主語-述語-目的語の三項対立を抽出する。
- オントロジー管理: 自動的にオントロジーを作成、検証、最適化し、セマンティックな一貫性を確保します。
- エンティティの曖昧性解消: データ精度を向上させるため、文書内のエンティティ参照がブロックをまたぐ問題を解決する。
- マルチフォーマット対応:テキスト、JSON、PDF、Markdownなど、複数のファイルフォーマットを扱えます。
- 意味的チャンキング:意味的類似性に基づいてテキストをセグメンテーションし、情報抽出を最適化する。
- GraphRAGサポート:検索機能を向上させるために、ナレッジグラフベースの検索機能拡張の生成をサポート。
- MCP互換:統合と呼び出しが容易なモデル制御プロトコルのエンドポイントを提供します。
- 三項ストレージのサポート:FusekiとNeo4jの三項ストレージをサポート。
- ローカルおよびクラウド展開:ローカルでの実行、またはREST API経由でのアクセスをサポート。
ヘルプの使用
設置プロセス
OntoCastはPythonベースのフレームワークであり、Dockerを使用してデプロイすることが推奨されています。以下は、詳細なインストールと設定の手順です:
- クローンプロジェクト
ターミナルで以下のコマンドを実行し、OntoCastプロジェクトをローカルにクローンします:git clone https://github.com/growgraph/ontocast.git cd ontocast - 依存関係のインストール
このプロジェクトではPython環境を使用します。uv依存関係を管理するツール。以下のコマンドを実行してインストールしてください:uv pip install -r requirements.txtそうでなければ
uvそれはpipそれに代わるものだ:pip install -r requirements.txt - 三項ストレージの設定
OntoCastは、三項ストレージバックエンドとしてFuseki(推奨)とNeo4jをサポートしています。以下はFusekiの例です:- 入る
docker/fusekiディレクトリにある環境設定ファイルをコピーして編集する:cp docker/fuseki/.env.example docker/fuseki/.env - コンパイラ
.envファイルを使用して、例えば、FusekiのURIと認証情報を設定します:FUSEKI_URI=http://localhost:3032/test FUSEKI_AUTH=admin/abc123-qwe - 布石サービスを開始する:
cd docker/fuseki docker compose --env-file .env up -d
- 入る
- 言語モデルの設定
OntoCastはOpenAIまたはネイティブモデル(Ollama経由など)をサポートしています。プロジェクトのルートディレクトリの.envファイルでモデルのパラメーターを設定する:LLM_PROVIDER=openai LLM_MODEL_NAME=gpt-4o-mini LLM_TEMPERATURE=0.0 OPENAI_API_KEY=your_openai_api_key_hereローカルモデル(Ollamaなど)を使用する場合は設定する:
LLM_PROVIDER=ollama LLM_BASE_URL=http://localhost:11434 - 運営サービス
OntoCastサービスを開始するには、次のコマンドを使用します:uv run serve --ontology-directory ONTOLOGY_DIR --working-directory WORKING_DIRそのうちのひとつだ。
ONTOLOGY_DIRはオントロジーファイルの保存パスである。WORKING_DIRは、処理されたデータを保存するための作業ディレクトリである。 - Dockerイメージの構築(オプション)
Dockerを使用してOntoCastを実行したい場合は、イメージをビルドすることができます:docker buildx build -t growgraph/ontocast:0.1.4 .
使用方法
OntoCastの中核機能は、意味トリプルを抽出し、知識グラフを構築することである:
- 書類の準備
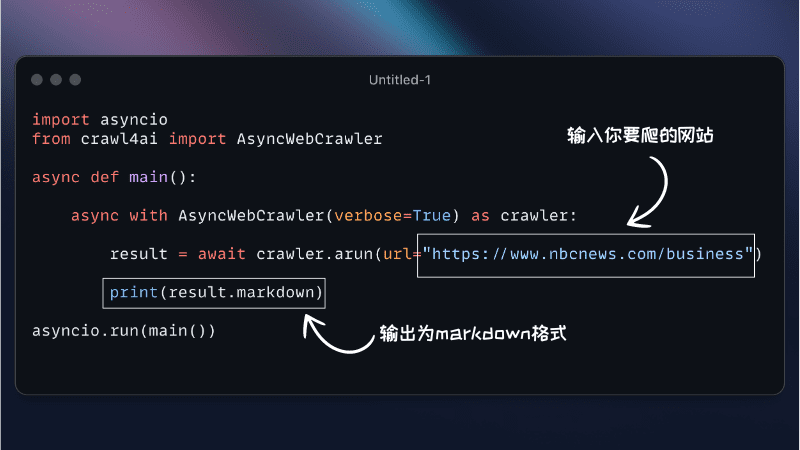
処理するドキュメント(テキスト、JSON、PDF、またはMarkdown形式がサポートされています)をdata/カタログ。このプロジェクトは、参照可能なサンプルデータを提供するdata/ディレクトリにある - 抽出プロセスを実行する
OntoCastはコマンドラインツールとREST APIの両方を提供している:- コマンドライン方式
CLIツールを使って文書を処理する:uv run ontocast process --input data/sample.md --output output.ttlこれによって
sample.mdファイルはRDFトリプルに処理され、次のように出力される。output.ttlファイル(タートル形式)。 - REST APIメソッド
サービス開始後/processエンドポイントcurl -X POST http://localhost:8999/process -H "Content-Type: application/json" -d '{"input": "data/sample.md"}'レスポンスは、抽出された三項データとオントロジーデータを返す。
- コマンドライン方式
- 結果を見る
処理後、結果は三項ストア(Fusekiなど)に保存されます。結果は3元ストア(例:Fuseki)に保存され、FusekiのWebインターフェース(デフォルト)からアクセスできます。http://localhost:3032)ナレッジグラフに問い合わせるか、SPARQLクエリ言語を使用してデータを取得する。 - オントロジーの最適化
OntoCast はオントロジーの自動最適化をサポートしています。オントロジーを手動で調整する必要がある場合はdata/ontologies/ディレクトリのオントロジーファイルの抽出を再実行する。 - GraphRAGの使用
OntoCastは知識グラフベースの検索拡張生成(GraphRAG)をサポートしている。処理が完了すると、生成された知識グラフを使って意味検索が実行される:uv run ontocast search --query "特定关键词" --graph output.ttlこれはキーワードに関連する3項結果を返す。
注目の機能操作
- セマンティックチャンキングOntoCast は、長い文書を意味的に類似したチャンクに自動的に分割し、より正確なトリプルの抽出を保証します。ユーザーが手動でチャンキングパラメータを設定する必要はなく、システムが意味的類似度に応じて自動的に処理します。
- 身体的差別OntoCastは、複数のドキュメントや長いドキュメントを扱う際に、エンティティ参照を識別し、統一します。例えば、"Apple "は異なる文脈で会社や果物を指すことがありますが、OntoCastは文脈に応じてそれらを正しく分類します。
- マルチフォーマット対応ユーザーはPDFやMarkdownファイルを直接アップロードすることができ、OntoCastは追加の前処理なしに自動的に内部処理フォーマットに変換します。
- MCPの互換性スルー
/processエンドポイントであるOntoCastは、他のシステムとの統合を容易にするモデル制御プロトコルをサポートしています。
ほら
- 抽出結果が保存されません。
- 大きな文書を処理する場合は、次のように設定することをお勧めします。
RECURSION_LIMIT歌で応えるESTIMATED_CHUNKSパラメータを使用することで、パフォーマンスの問題を回避することができます。 - プロジェクトのドキュメントは以下にある。
docs/カタログでは、詳細なユーザーガイドとAPIリファレンスを提供しています。
アプリケーションシナリオ
- 学術研究
研究者はOntoCastを使って学術論文から重要な概念や関係を抽出し、ドメイン知識グラフを構築することができる。例えば、生物学の論文を扱う場合、遺伝子、タンパク質、それらの相互作用を抽出し、クエリ可能な知識ベースを生成することができる。 - エンタープライズ・ドキュメント管理
企業は、社内文書(技術マニュアルや契約書など)をナレッジグラフ化することで、迅速な検索や分析が可能になります。例えば、契約書から条件や金額、関係者情報を抽出することで、情報管理の効率化を図ることができます。 - セマンティック検索の最適化
ウェブ開発者は、非構造化コンテンツから構造化データを抽出し、検索結果の精度を向上させるセマンティック検索機能を構築するために、OntoCastを使用することができます。 - インテリジェント質疑応答システム(Q&A)
OntoCastは、Q&Aシステムのナレッジグラフサポートを提供することができる。例えば、企業のFAQドキュメントからトリプルを抽出し、製品やサービスに関するユーザー固有の質問に回答する。
品質保証
- OntoCastはどのようなファイル形式に対応していますか?
テキスト、JSON、PDF、Markdown形式をサポートしています。将来的にはさらに多くのフォーマットが拡張される可能性があります。 - 三元ストレージの選び方
Neo4jよりもシンプルな構成と優れたパフォーマンスを持つFusekiを推奨する。docker/fuseki/.env.exampleコンフィギュレーション。 - 定義済みのオントロジーは必要ですか?
OntoCastは自動的にオントロジーを生成・最適化し、ユーザーが提供するカスタムオントロジーもサポートします。 - 大容量の文書はどのように扱っていますか?
追加提案ESTIMATED_CHUNKSパラメータ(例えば50に設定)を設定し、ハードウェア・リソースが十分であることを確認する。セマンティック・チャンキングは自動的に最適化されます。 - どのような言語モデルに対応していますか?
OpenAIをサポートするモデル(例.gpt-4o-mini)およびローカルモデル(例えばOllamaを通じて実行されるもの)。