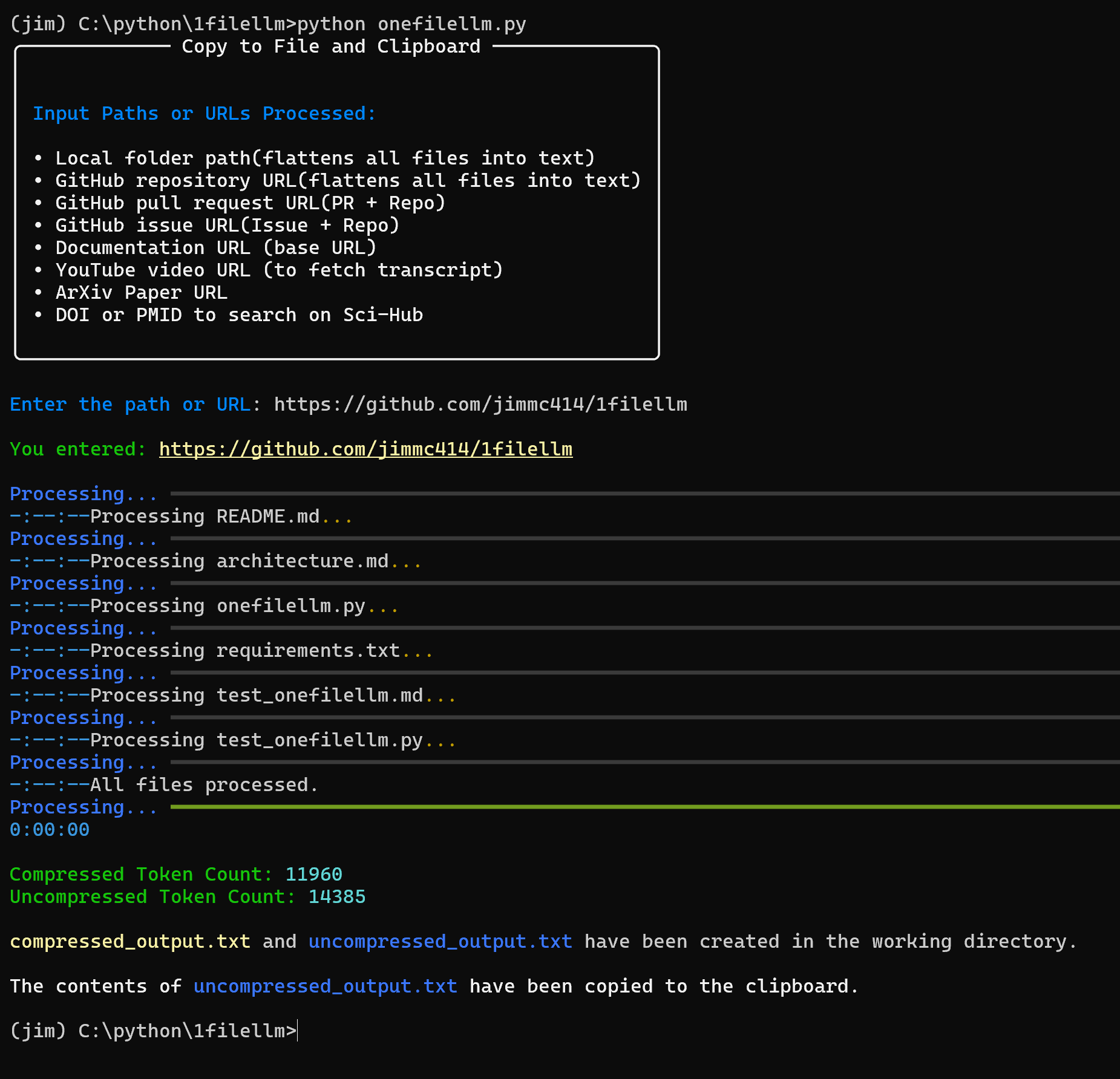
OneFileLLMは、複数のデータソースを単一のテキストファイルに統合し、大規模言語モデル(LLM)を簡単に入力できるように設計されたオープンソースのコマンドラインツールです。GitHubリポジトリ、ArXiv論文、YouTube動画トランスクリプト、ウェブコンテンツ、Sci-Hub論文、ローカルファイルの処理をサポートし、自動的に構造を生成します。
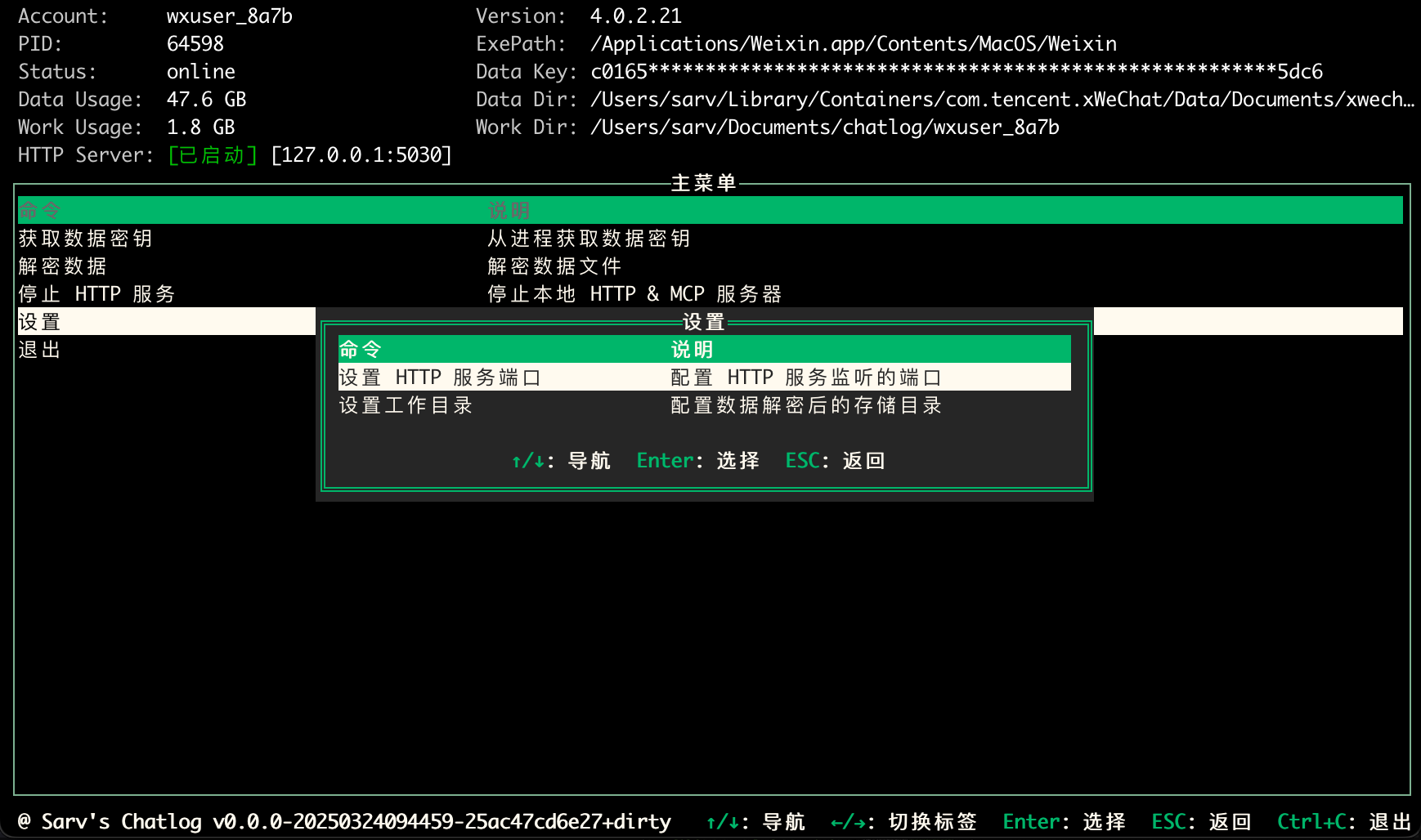
Chatlogは、WeChatのローカルデータベースからチャットログを抽出してクエリすることに特化したオープンソースツールです。WeChatのバージョン3.xと4.0をサポートし、WindowsとmacOSシステムをカバーしています。ユーザーはコマンドライン、ターミナルインターフェース、HTTP APIから操作して、チャットログ、連絡先、グループチャット、...

Versatile OCR Programは、複雑な学術・教育文書を処理するために設計されたオープンソースの光学式文字認識(OCR)ツールです。PDF、画像、その他の文書からテキスト、表、数式、図、回路図を抽出し、機械学習の学習に適した構造化データを生成することができます。サポート...
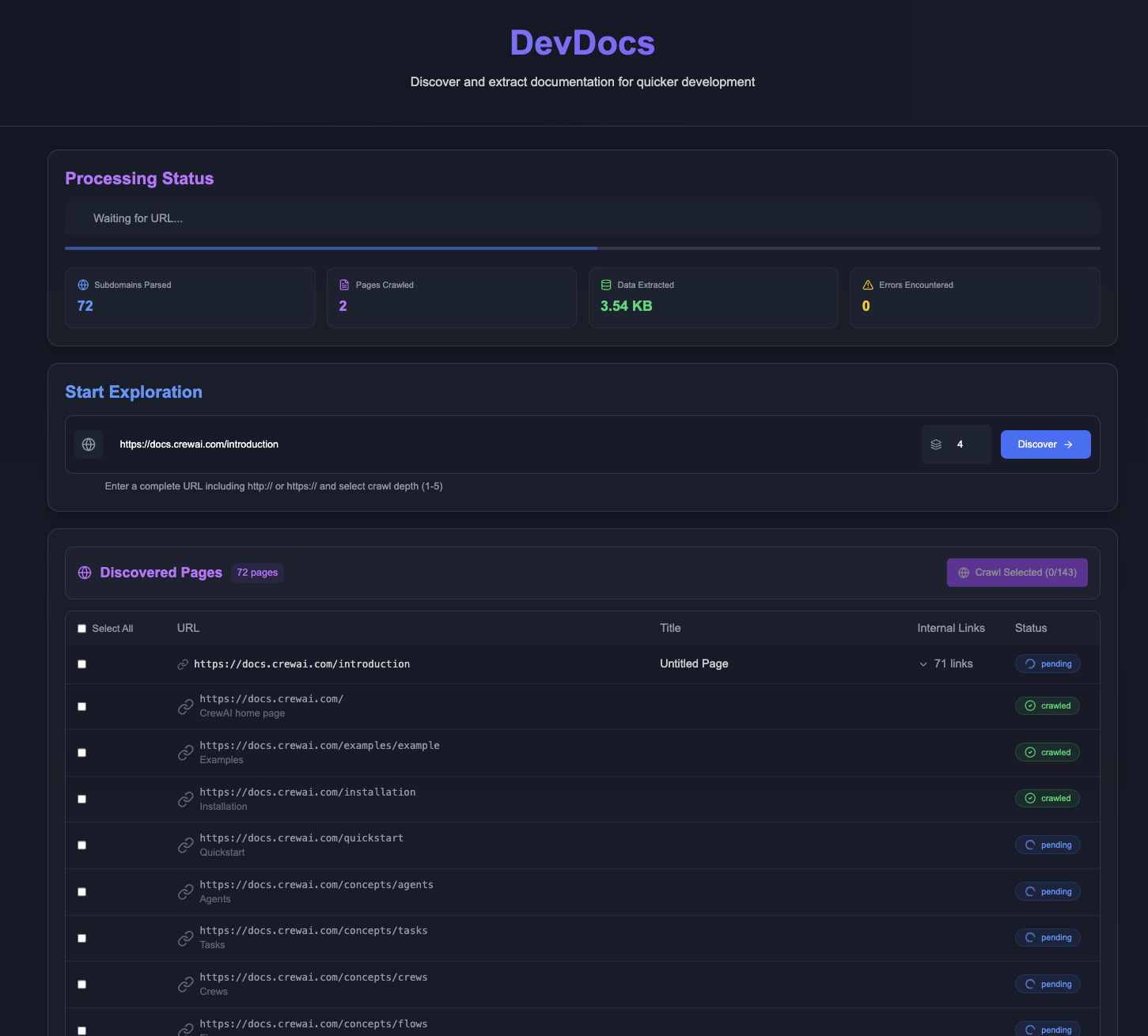
DevDocsは、CyberAGIチームによって開発され、GitHubでホストされている完全に無料のオープンソースツールです。プログラマーやソフトウェア開発者のために設計されており、技術文書のURLから開始し、関連するページを自動的にクロールし、簡潔なMarkdownまたはJSONファイルに整理します。MCP ...
それは自動的にPDF文書のレイアウトを分析し、ページ内のテキスト、タイトル、画像、表、数式やその他の要素を識別し、それらの正しい順序を決定します。このツールはOCR機能をサポートしており、スキャンしたPDFを検索可能なテキストに変換することができます。Docker上で動作し、2つのモデルを提供します:ビジュアルモデル(Vision Grid ...

serverless-markdown-convertorは、Cloudflare WorkerとWorkers AIをベースにした無料のオープンソースツールで、さまざまなファイルをMarkdown形式に変換します。PDF、画像、Officeドキュメント...
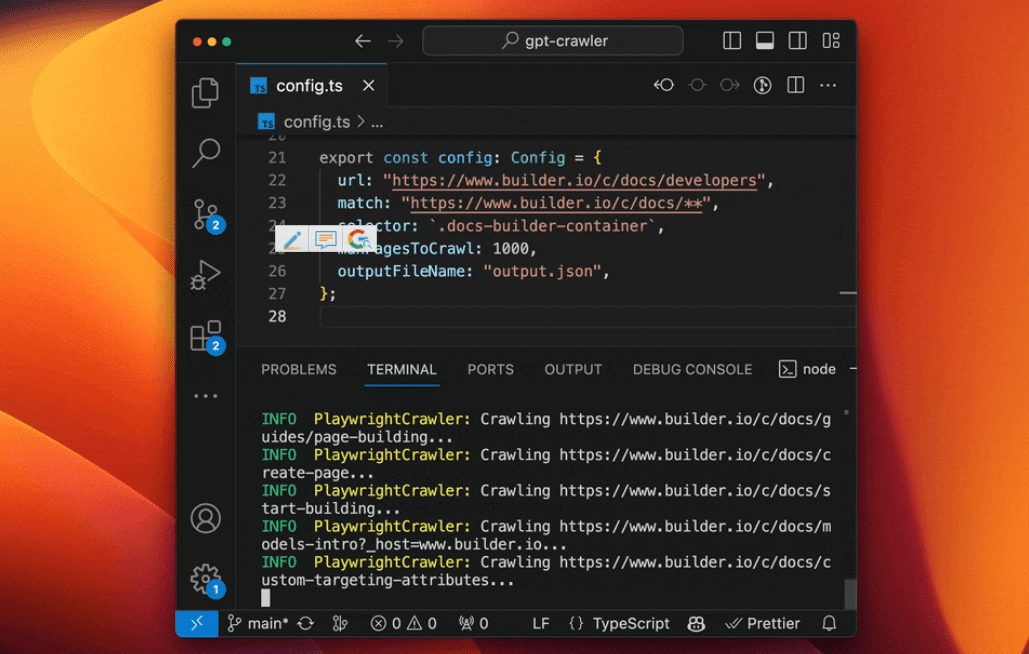
GPT-Crawlerは、BuilderIOチームによって開発され、GitHubでホストされているオープンソースツールです。1つ以上のウェブサイトのURLを入力することで、ページのコンテンツをクロールし、カスタムGPTまたはAIアシスタントを作成するために使用できる構造化ナレッジファイル(output.json)を生成します。ユーザー...
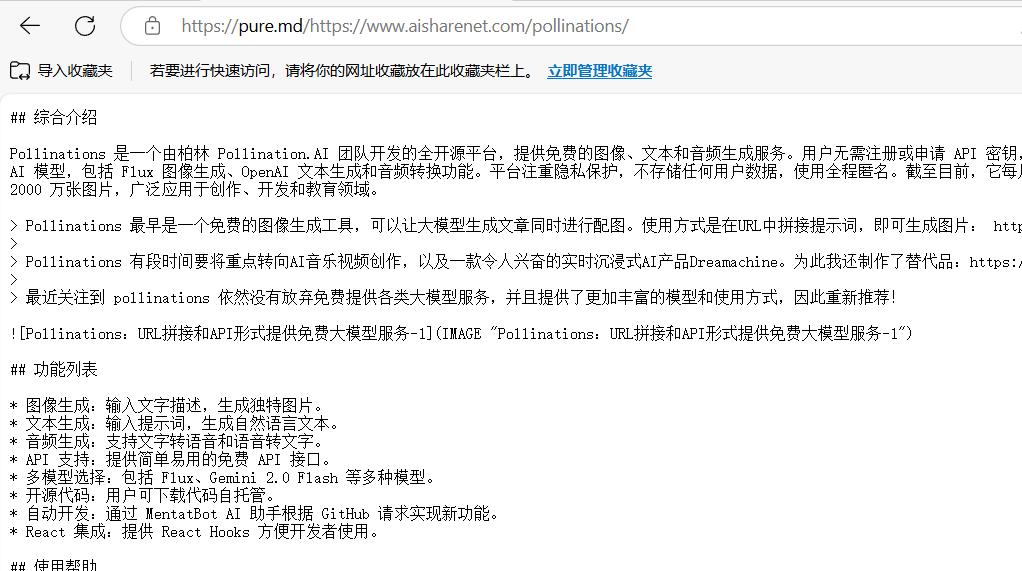
pure.mdは、AIエージェントや開発者のために設計されたツールで、ウェブコンテンツやファイルを素早くMarkdown形式に変換することに重点を置いています。プロキシサービスによるクローラー対策の制限を回避し、ウェブページのコアデータを抽出し、クリーンなMarkdownファイルを出力します。動的なウェブページ、PDFファイル、ソーシャル...
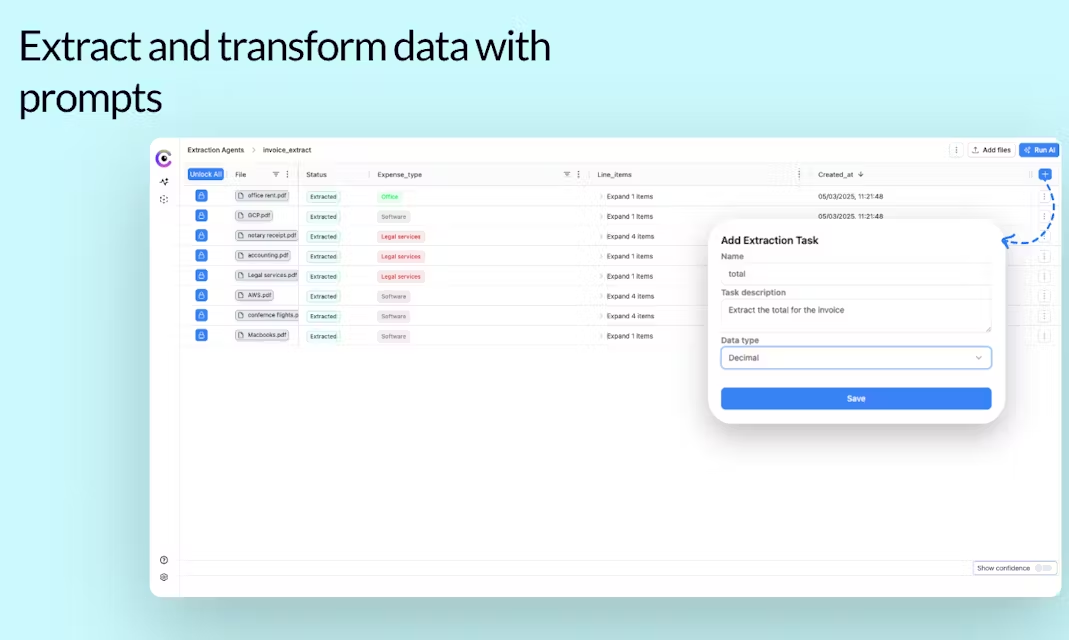
Cloudsquidは2023年にドイツ・ベルリンで設立された企業で、人工知能による文書処理の簡素化に注力している。主力製品はオンラインデータ抽出プラットフォームで、ユーザーはPDF、画像、音声、動画などをアップロードし、「名前と住所を調べる」など、抽出したいデータを指定するだけで、そのデータを抽出することができる。

PDF Craftは、書籍のPDFをスキャンしてMarkdown形式に変換するために設計されたオープンソースのツールです。oomol-labによって開発され、GitHubでホストされている。このツールはローカルのAIモデルで動作し、インターネット接続を必要としないため、プライバシーを保護し、操作を容易にします。
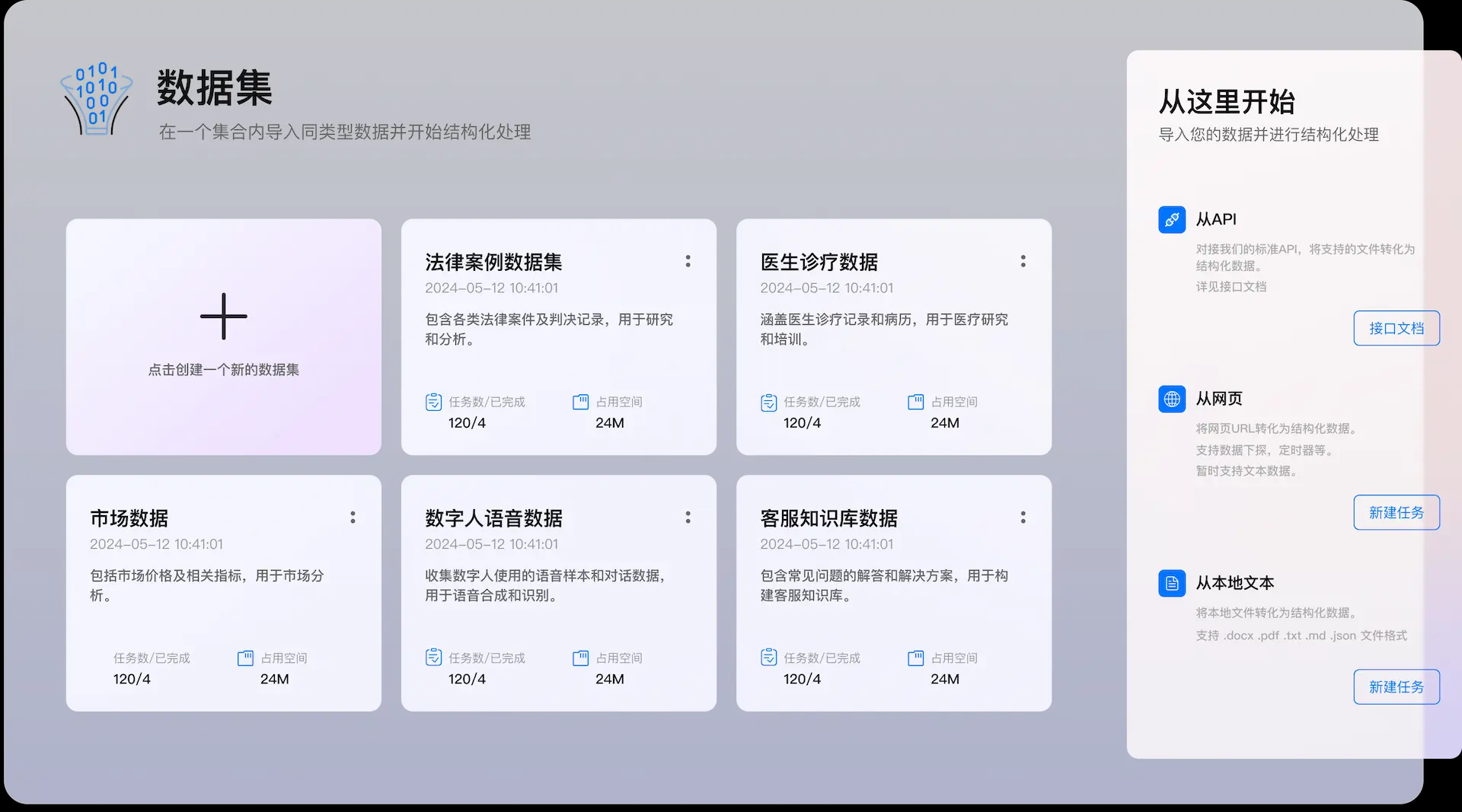
Supametas.AIは、ウェブページ、ドキュメント、オーディオ、ビデオの乱雑なデータを、AIが使用できる構造化データに整理することに特化したデータ処理プラットフォームである。ウェブリンク、API、ローカルファイルなど複数のソースからデータを収集し、JSONまたはMarkdown形式でエクスポートすることができる。このプラットフォームはプログラミングを必要としない。

MarkPDFDownはオープンソースのツールです。マルチモーダルな大きな言語モデルを使ってPDFファイルをMarkdown形式に変換する。GitHubユーザーのjorben氏によって開発されたこのツールの目的はシンプルで、PDFドキュメントを編集・共有しやすくすることです。このツールは、見出し、リスト、...

SmolDoclingは、ds4sdチームがIBMと共同で開発した視覚言語モデル(VLM)で、SmolVLM-256Mをベースにしており、Hugging Faceプラットフォームでホストされています。SmolDoclingは、わずか256Mのパラメータを持つ世界最小のVLMで、そのコア機能は...

表認識の目的は、画像中の表を解析し、表の構造やセルの位置を正確に特定し、構造化された表形式(HTMLなど)に変換することである。今日の情報化時代において、大量の重要な表データが、構造化されていない状態で存在している。

人類の文明の長い歴史の中で、情報の取得と解析の方法が飛躍的に進歩するたびに、社会は大きく発展してきた。古代の象形文字から、持ち運び可能なパピルス、その後の印刷機の出現、そして今日のデジタルの波に至るまで、技術革新のたびに人類の知識の伝達は大きく拡大してきた。

Firecrawl MCP Serverは、MendableAIによって開発されたオープンソースツールで、モデルコンテキストプロトコル(MCP)プロトコル実装に基づき、Firecrawl APIと統合され、強力なウェブクローリングとデータ抽出を提供します。このツールは、...
olmOCRは、アレン人工知能研究所(AI2)のAllenNLPチームによって開発されたオープンソースツールで、PDFファイルを線形化されたテキストに変換することに重点を置いており、特に大規模言語モデル(LL...
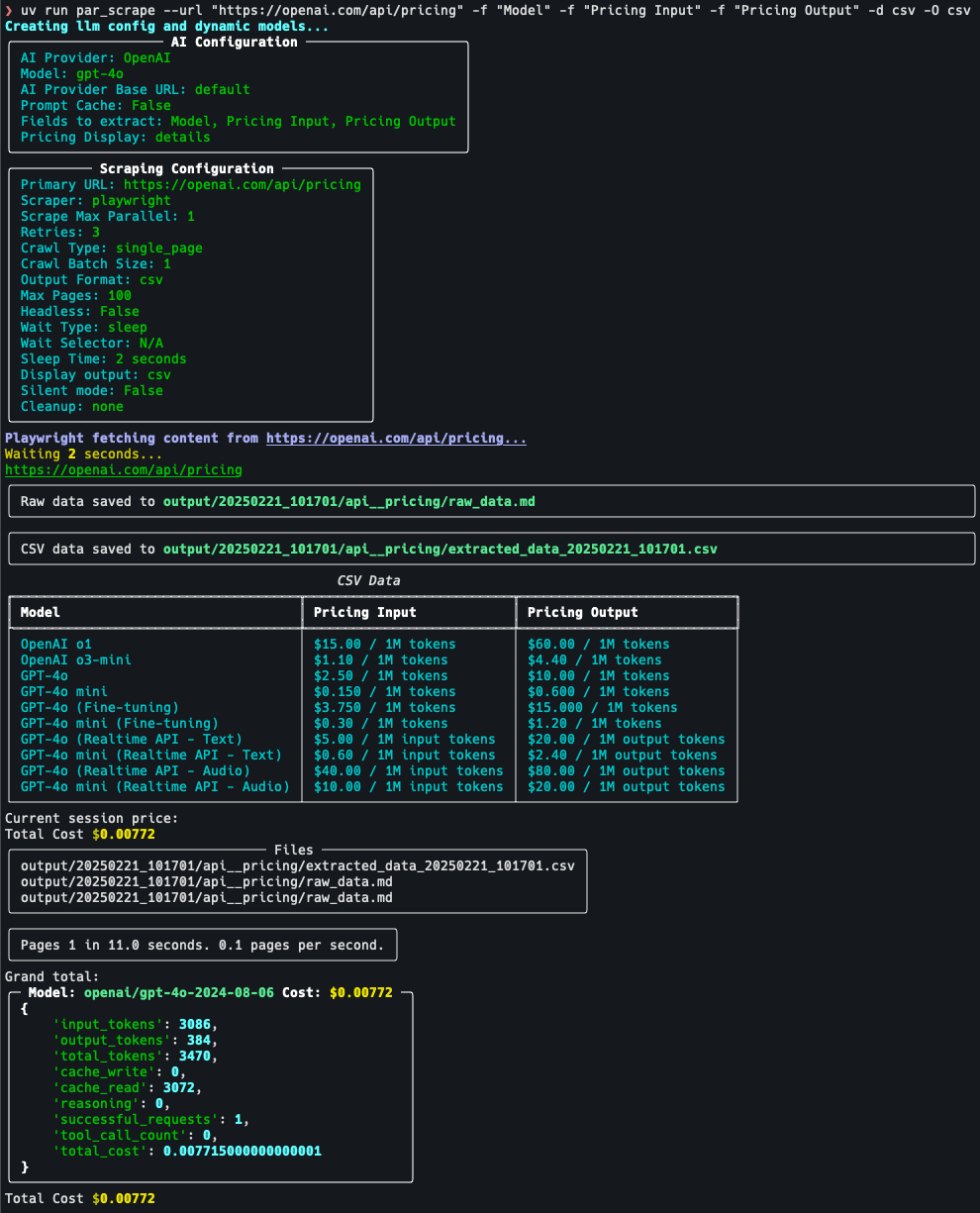
par_scrapeはPythonベースのオープンソースWebクローラーツールで、開発者のPaul RobelloによってGitHubで公開された。SeleniumとPlaywrightという2つの強力なブラウザ自動化ツールを統合している。

PDF-Extract-Kitは、OpenDataLabチームによって開発されたオープンソースプロジェクトで、複雑で多様なPDF文書から高品質なコンテンツを効率的に抽出することに焦点を当てています。先進的な文書解析技術、レイアウト検出、数式認識、表抽出、OCRなどの機能を統合しており、学術論文や......に適用できます。

