

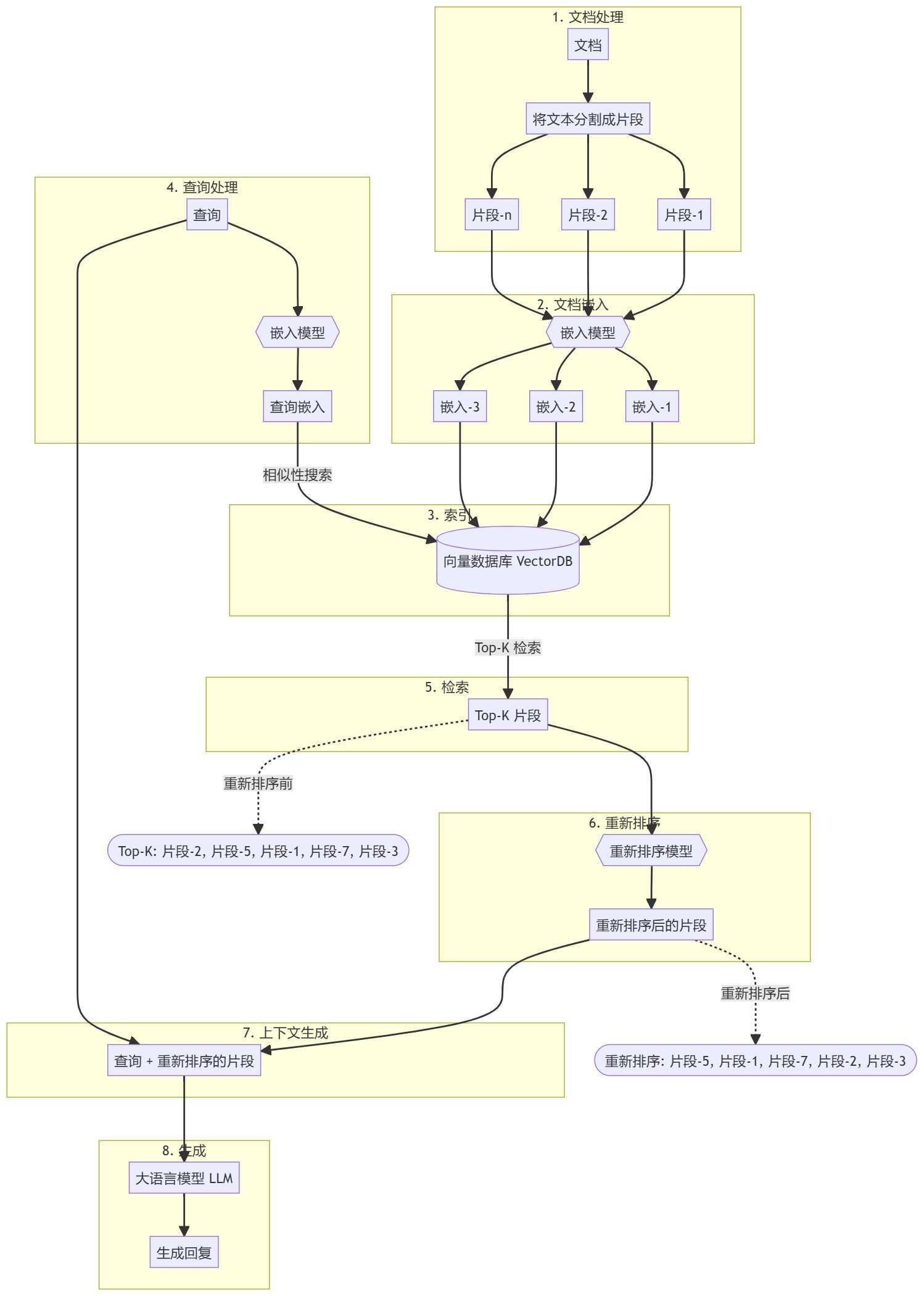
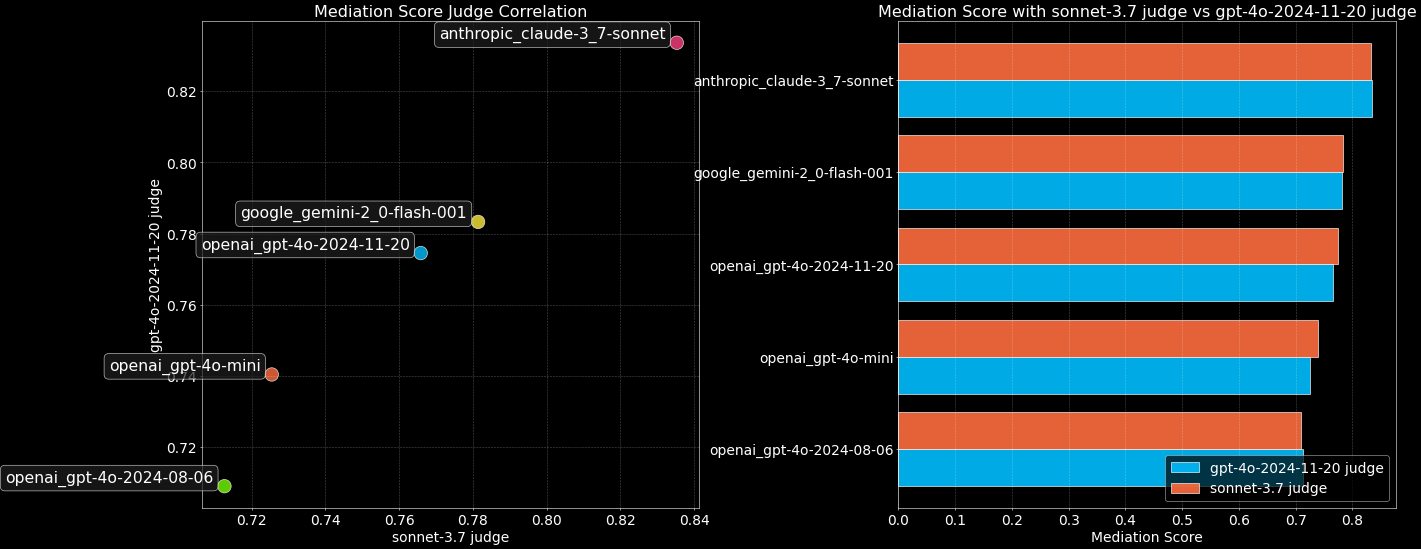
並べ替えモデルは、候補文書のリストをユーザーの質問に対する意味的一致度に基づいて並べ替えることで、意味的ランキングの結果を改善する。
よく使われるbge-reranker-v2-m3またはcohere
無断転載を禁じます:AI生産性ツール " AIエンジニアリング・アカデミー:2.7 ReRanker RAG(並び替え)
並べ替えモデルは、候補文書のリストをユーザーの質問に対する意味的一致度に基づいて並べ替えることで、意味的ランキングの結果を改善する。
よく使われるbge-reranker-v2-m3またはcohere

大規模な言語モデリング技術の急速な発展と広範な応用に伴い、その潜在的なセキュリティリスクはますます業界の注目の的となっている。このような課題に対処するため、世界トップクラスのテクノロジー企業、標準化団体、研究機関の多くが、独自のセキュリティフレームワークを構築し、公開している。本稿では、そのうちの9つを分析する。
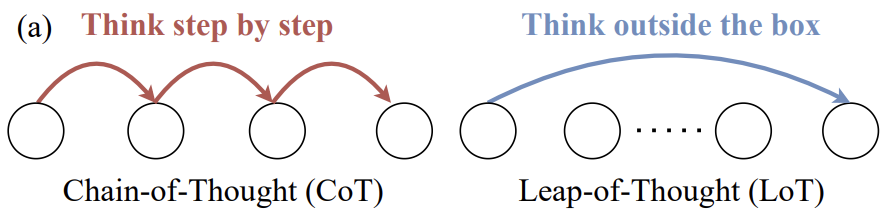
大規模言語モデリング(LLM)研究の分野では、モデルの思考飛躍能力、すなわち創造性は、思考連鎖(Chain-of-Thought)に代表される論理的推論能力に劣らず重要である。しかし、LLMの創造性についての詳細な議論や有効な評価方法は、まだ相対的に不足している。
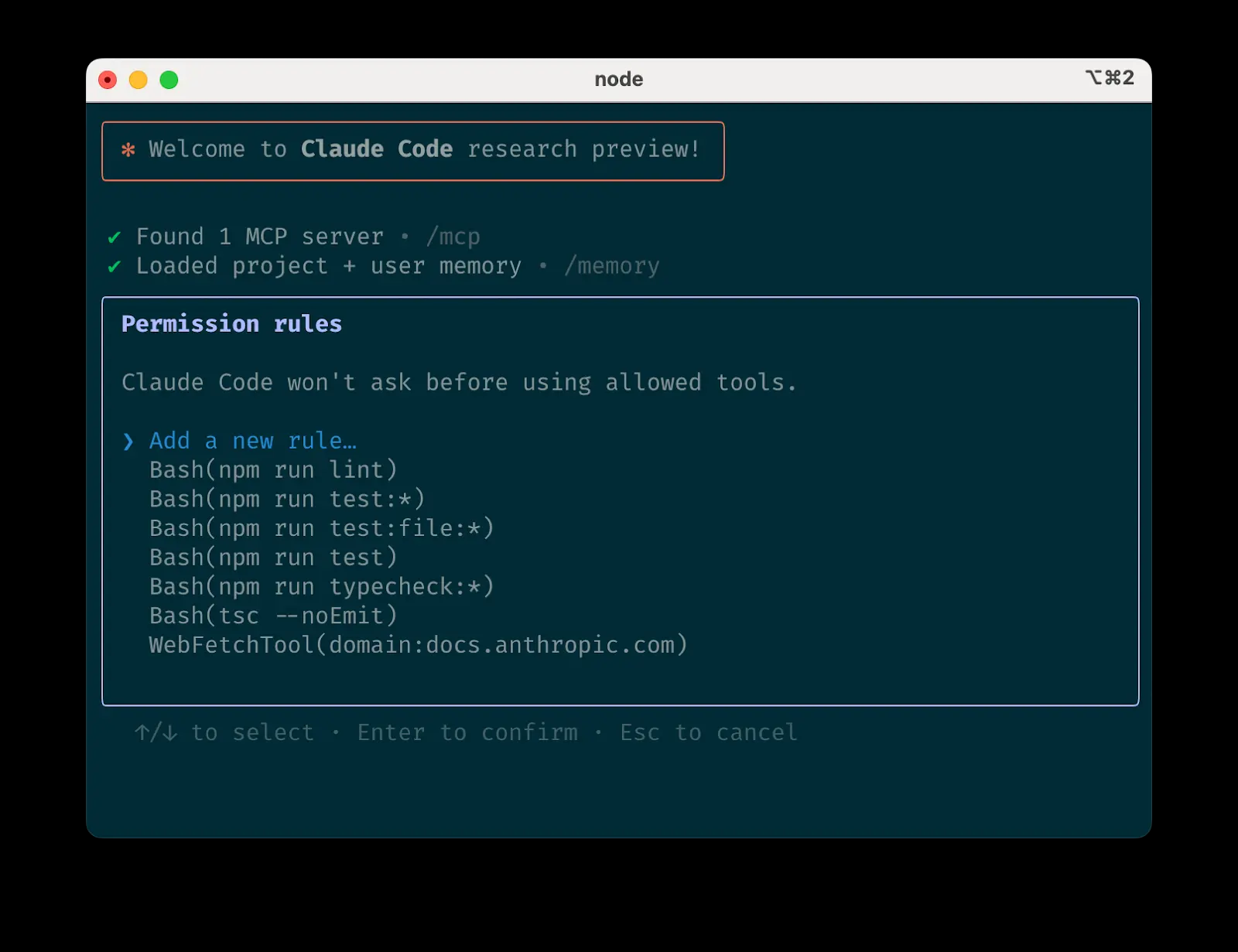
クロード・コードを使いこなす:最前線からのハンズオン・エージェント・コーディングのヒント クロード・コードは、エージェント・コーディングのためのコマンドライン・ツールです。Agentic Codingとは、AIにある程度の自律性を与え、タスクを理解し、ステップを計画し、アクション(...

GPT-4.1ファミリーは、GPT-4oと比較して、コーディング、命令順守、長いコンテキストの処理能力が大幅に向上しています。具体的には、コード生成と修復タスクでより優れた性能を発揮し、複雑な命令をより正確に理解して実行し、長い入力テキストを効率的に処理できる。このヒントとなる作業...
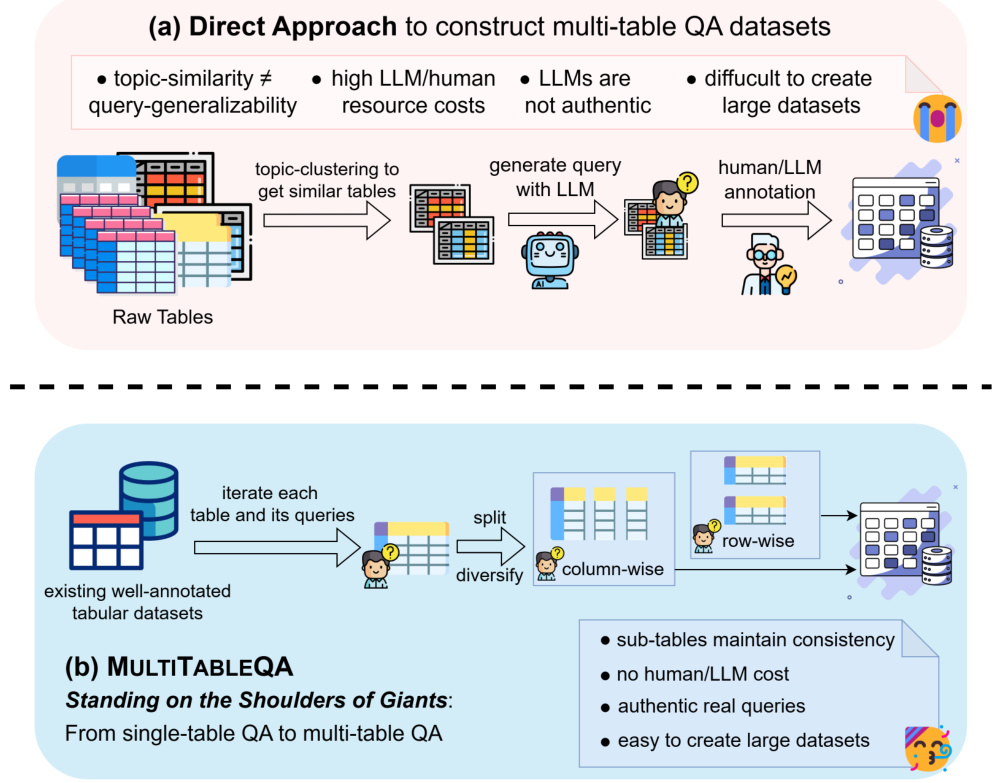
1.はじめに 今日の情報爆発では、大量の知識がウェブページ、ウィキペディア、リレーショナ ルデータベースのテーブルの形で保存されている。しかし、従来の質問応答システムは、複数のテーブルにまたがる複雑なクエリを処理するのに苦労することが多く、人工知能の分野では大きな課題となっている。この課題に対処するため、研究者たちは...
ラージ・ランゲージ・モデル(LLM)の能力が急速に進化する中、MMLUのような従来のベンチマークテストでは、トップモデルの識別に限界があることが徐々に明らかになりつつある。知識クイズや標準化されたテストだけに頼っていては、感情的知性や創造性など、実世界の相互作用において重要なモデルの微妙な能力を総合的に測定することは難しくなっています。

大規模言語モデル(LLM)の開発は急速に変化しており、その推論能力は知能レベルを示す重要な指標となっている。特に、OpenAIのo1、DeepSeek-R1、QwQ-32B、Kimi K1.5のような長い推論能力を持つモデルは、複合問題を解くことによって人間の深い思考プロセスをシミュレートする...
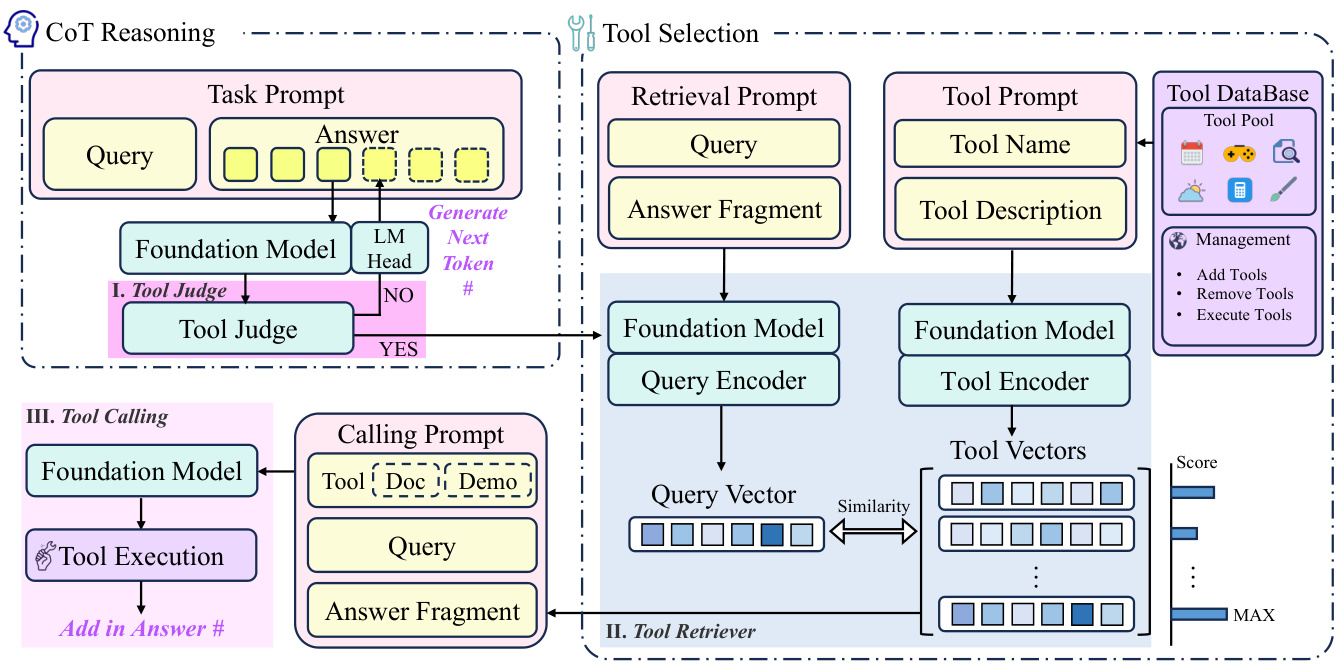
はじめに 近年、大規模言語モデル(Large Language Models: LLM)は人工知能(Artificial Intelligence: AI)の分野で目覚ましい進歩を遂げ、その強力な言語理解・生成能力により、様々な領域で幅広い応用が行われている。しかし、外部ツールの起動を必要とする複雑なタスクを扱う場合、LLMは依然として多くの課題に直面している。例えば、...

Llamao:携帯電話上でオフラインかつプライベートで動作するAIチャットボット

Blackbox:統合マルチモデル・インテリジェント・ボディ・ダイアローグ、専用Blackboxモデル・プログラミング・アシスタント

Fullmoon:ネイティブの多言語モデルチャット用iOSアプリ

LibreChat: ChatGPTインターフェイスを模倣したAI対話オープンソースプロジェクト

Groq:AI大規模モデル推論アクセラレーションソリューションプロバイダー、高速無料大規模モデルインターフェース

白川ビッグモデル:白小穎インテリジェントQ&Aプラットフォーム

ネモトロン:ラマ3.1ベースのネモトロン70Bモデル(無料)によるAIチャットツールの強化

ChatGPT: OPENAIが無料の人工知能チャットツールをリリース




WeChatスキャンコード共有
