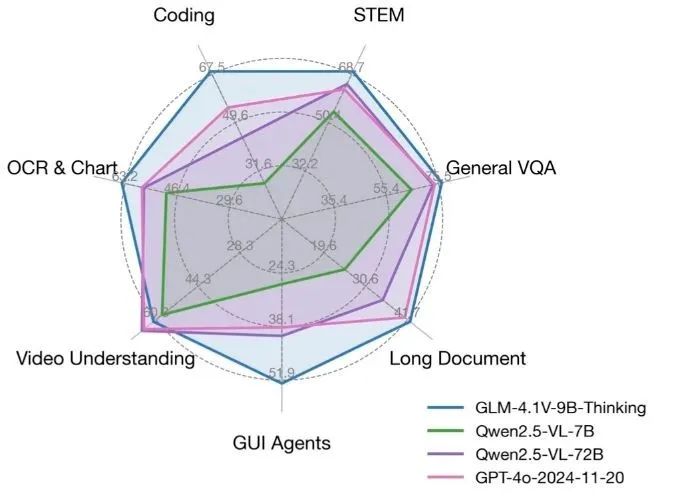
GLM-4.1V-Thinking 是一个由清华大学 KEG 实验室(THUDM)开发的开源视觉语言模型,专注于多模态推理能力。基于 GLM-4-9B-0414 基础模型,GLM-4.1V-Thinking 通过强化学习和“思维链”推理机制,显著提升了复杂任务的处理能力。它支持 64k 超长上下文、4K 高分辨率图像处理,并兼容任意图像宽高比,同时支持中英文双语。该模型在数学、代码、长文档理解和视频推理等任务中表现出色,部分评测甚至超越了 GPT-4o。代码和模型已在 GitHub 上开放,采用 MIT 许可证,允许免费商用,适合开发者、研究人员和企业使用。
功能列表
- 支持 64k 超长上下文,处理长文档或复杂对话。
- 处理 4K 高分辨率图像,支持任意宽高比。
- 提供中英文双语支持,适合多语言场景。
- 集成“思维链”推理机制,提升数学、代码和逻辑任务的准确性。
- 支持视频推理,可分析视频内容并回答相关问题。
- 开源代码和模型,基于 MIT 许可证,允许免费商用。
- 提供 Hugging Face 和 ModelScope 在线演示,快速体验模型能力。
- 支持单张 3090 显卡运行,适合资源有限的开发环境。
使用帮助
安装与部署
GLM-4.1V-Thinking 提供完整的代码和模型文件,部署过程简单,适合开发者在本地或服务器上运行。以下是详细的安装和使用步骤:
1. 环境准备
需要在支持 GPU 的环境中运行,推荐使用 NVIDIA 显卡(如 RTX 3090)。确保已安装 Python 3.8 或以上版本,以及 PyTorch。以下是安装依赖的步骤:
pip install git+https://github.com/huggingface/transformers.git
pip install torch torchvision torchaudio
pip install -r requirements.txt
如果需要进行模型微调,可参考 finetune/README.md 文件,使用 LLaMA-Factory 工具包。微调时建议使用 Zero3 策略以确保训练稳定性,避免 Zero2 可能导致的零损失问题。
2. 下载模型
GLM-4.1V-Thinking 模型可从 Hugging Face 或 GitHub 仓库下载。运行以下代码加载模型:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
模型支持 bfloat16 格式,降低内存占用,适合单 GPU 运行。
3. 单张图像推理
GLM-4.1V-Thinking 支持图像输入的推理任务。以下是一个简单的图像描述示例:
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/sample_image.png"},
{"type": "text", "text": "描述这张图片"}
]
}
]
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
将 sample_image.png 替换为实际图像 URL 或本地路径。模型会分析图像并生成详细描述。
4. 视频推理
GLM-4.1V-Thinking 支持视频内容分析。用户可通过 GitHub 仓库中的示例代码或在线演示平台(如 Hugging Face)上传视频文件,模型将解析视频并回答相关问题。例如,上传一段会议视频,询问“视频中讨论了哪些主题”,模型会提取关键信息并生成准确回答。
5. 长文档理解
模型支持 64k 超长上下文,适合处理长篇文档。用户可将文本输入模型,询问文档中的具体内容或总结关键点。例如,输入一篇 50 页的学术论文,询问“论文的主要结论是什么”,模型会快速提取并总结。
6. 在线演示
无需本地部署,可通过 Hugging Face 或 ModelScope 提供的在线演示直接体验。访问以下链接:
- Hugging Face 演示:
https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking - ModelScope 演示:
https://modelscope.cn/models/THUDM/GLM-4.1V-9B-Thinking
用户可上传图像、视频或输入文本,快速测试模型的推理能力。
7. 微调模型
开发者可使用 LLaMA-Factory 工具包对模型进行微调,以适配特定任务。微调配置文件位于 configs/lora.yaml,运行以下命令开始微调:
cd finetune
python finetune.py data/YourDataset/ THUDM/GLM-4-9B-0414 configs/lora.yaml
确保数据集格式正确,推荐使用 JSON 格式。微调后,模型可更好地适配特定领域的任务,如医疗图像分析或法律文档处理。
特色功能操作
- 思维链推理:模型通过“思维链”机制分解复杂问题。例如,在数学任务中,模型会逐步推导答案,确保结果准确。用户输入“求解二次方程 x² + 2x – 3 = 0”,模型会输出详细的解题步骤。
- 多模态支持:用户可同时输入图像和文本。例如,上传一张电路图并询问“电路的工作原理是什么”,模型会结合图像和问题生成详细解释。
- 中英文双语:模型支持中英文混合输入,适合跨语言场景。例如,输入中文问题和英文图像描述,模型会以指定语言回答。
注意事项
- 确保 GPU 内存充足,推荐至少 24GB 显存。
- 长上下文处理时,启用 YaRN 配置以优化性能,配置文件为
config.json中的"rope_scaling": {"type": "yarn", "factor": 4.0}。 - 模型推理速度依赖硬件,3090 显卡可实现实时响应。
应用场景
- 学术研究
研究人员可使用 GLM-4.1V-Thinking 分析长篇学术论文,提取关键结论或总结内容。模型还能处理实验图像,辅助分析数据图表。 - 教育支持
学生可上传数学题目或科学实验图片,模型会提供详细解题步骤或实验解释,适合自学或教学辅助。 - 内容创作
创作者可输入视频或图像素材,生成描述性文本或创意脚本。例如,输入旅游视频,生成景点介绍。 - 企业应用
企业可将模型用于文档自动化处理,如分析合同条款或生成报告。支持中英文双语,适合跨国企业。
QA
- GLM-4.1V-Thinking 支持哪些输入类型?
模型支持图像、视频、文本输入,兼容 4K 图像和 64k 上下文,适合多模态任务。 - 是否需要高性能硬件?
单张 RTX 3090 显卡即可运行,推荐 24GB 显存以确保流畅推理。 - 如何进行模型微调?
使用 LLaMA-Factory 工具包,参考 GitHub 仓库中的finetune/README.md文件,配置lora.yaml进行微调。 - 模型是否免费?
是的,模型基于 MIT 许可证开源,允许免费商用。 - 如何体验模型?
可通过 Hugging Face 或 ModelScope 的在线演示上传图像或文本,快速测试模型功能。