vLLM is a high-throughput and memory-efficient reasoning and service engine designed for Large Language Modeling (LLM). Originally developed by the Sky Computing Lab at UC Berkeley, it is now a community project driven by both academia and industry. vLLM aims to provide fast, easy-to-use and cost-effective LLM reasoning services with support for a wide range of hardware platforms including CUDA, ROCm, TPUs, and more. Its key features include optimized execution loops, zero-overhead prefix caching, and enhanced multimodal support.

Function List
- High Throughput Reasoning: supports massively parallel reasoning, significantly improving reasoning speed.
- Memory Efficient: Reduce memory usage and improve model operation efficiency by optimizing memory management.
- Multi-hardware support: Compatible with CUDA, ROCm, TPU and other hardware platforms for flexible deployment.
- Zero-overhead prefix caching: Reduce duplicate computation and improve inference efficiency.
- Multi-modal support: Supports multiple input types such as text, image, etc. to extend the application scenarios.
- Open source community: maintained by academia and industry, continuously updated and optimized.
Using Help
Installation process
- Clone the vLLM project repository:
git clone https://github.com/vllm-project/vllm.git
cd vllm
- Install the dependencies:
pip install -r requirements.txt
- Choose the appropriate Dockerfile for your build based on your hardware platform:
docker build -f Dockerfile.cuda -t vllm:cuda .
Guidelines for use
- Start the vLLM service:
python -m vllm.serve --model <模型路径>
- Sends a reasoning request:
import requests
response = requests.post("http://localhost:8000/infer", json={"input": "你好,世界!"})
print(response.json())
Detailed Function Operation
- High Throughput Reasoning: By parallelizing the reasoning task, vLLM is able to process a large number of requests in a short period of time for highly concurrent scenarios.
- Memory Efficient: vLLM uses an optimized memory management strategy to reduce memory footprint and is suitable for running in resource-constrained environments.
- Multi-Hardware Support: Users can choose the right Dockerfile to build according to their hardware configuration and flexibly deploy on different platforms.
- Zero-overhead prefix caching: By caching the results of prefix computation, vLLM reduces repetitive computation and improves inference efficiency.
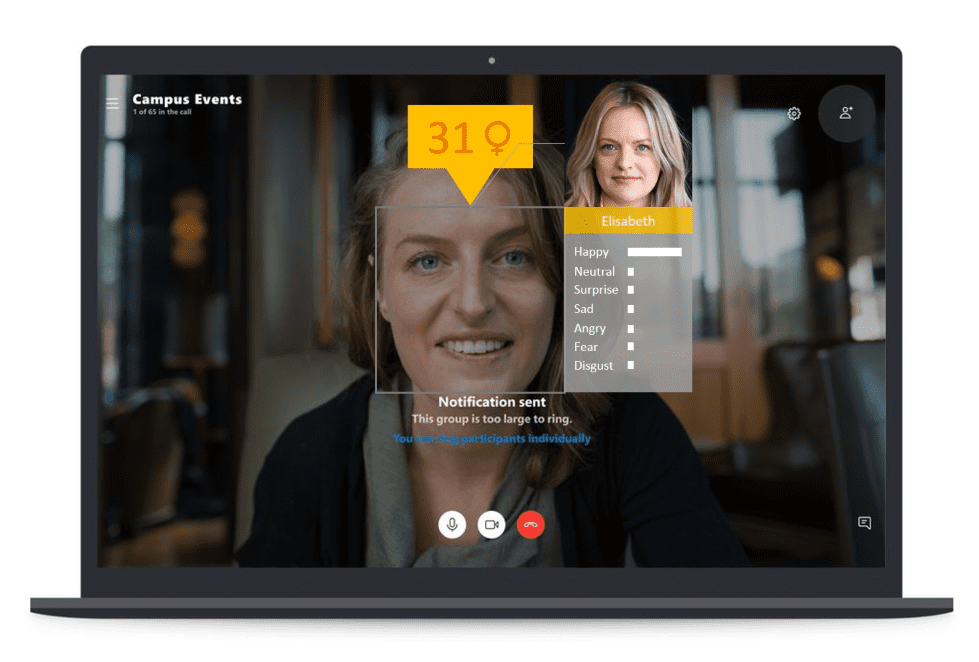
- multimodal support: vLLM not only supports text input, but also handles a variety of input types such as images, expanding the application scenarios.