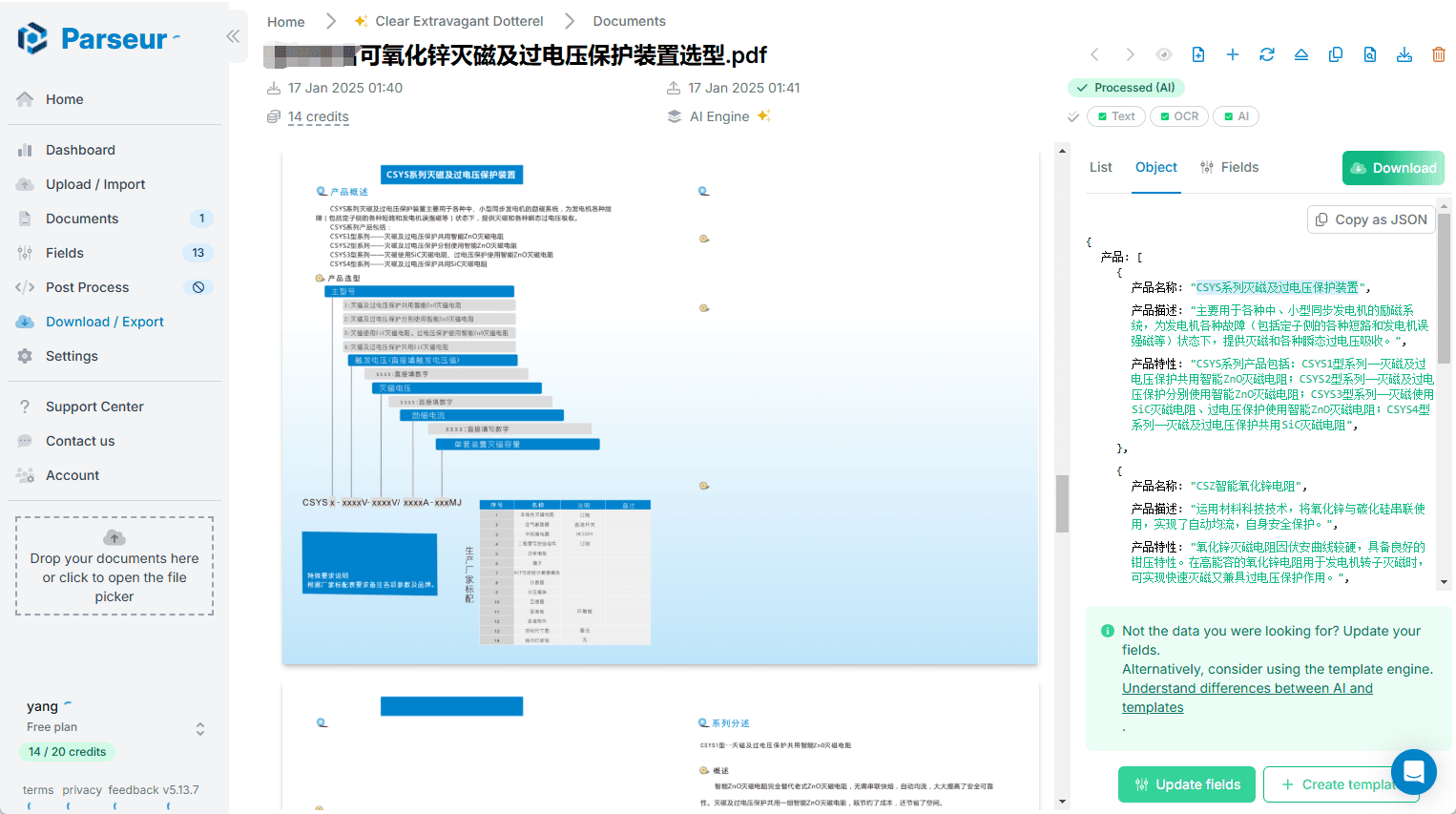
ExtractThinker is a flexible document intelligence tool that utilizes Large Language Models (LLMs) to extract and classify structured data from documents, providing a seamless ORM-like document processing workflow. It supports a variety of document loaders, including Tesseract OCR, Azure Form Recognizer, AWS Textract, and Google Document AI, among others. Users can define custom extraction contracts using Pydantic models for accurate data extraction. The tool also supports asynchronous processing, multi-format document processing (e.g., PDF, images, spreadsheets, etc.), and integrates with a variety of LLM providers (e.g., OpenAI, Anthropic, Cohere, etc.).

Function List
- Flexible Document Loader: Support for multiple document loaders, including Tesseract OCR, Azure Form Recognizer, AWS Textract, and Google Document AI.
- Customized withdrawal contracts: Define custom extraction contracts using Pydantic models for accurate data extraction.
- Advanced Classification: Classify documents or document sections using custom classifications and policies.
- asynchronous processing: Efficient processing of large documents using asynchronous processing.
- Multi-format support: Seamlessly handle a variety of document formats such as PDF, images, spreadsheets, and more.
- ORM style interactions: Interacts with documentation and LLMs in ORM style for easy development.
- segmentation strategy: Implement lazy or eager segmentation strategies to process documents by page or as a whole.
- Integration with LLM: Easily integrate with different LLM providers (e.g. OpenAI, Anthropic, Cohere, etc.).
Using Help
Installation process
- Install ExtractThinker: Install ExtractThinker using pip:
pip install extract_thinker
Guidelines for use
Basic Extraction Example
The following example demonstrates how to use PyPdf to load a document and extract specific fields defined in a contract:
import os
from dotenv import load_dotenv
from extract_thinker import Extractor, DocumentLoaderPyPdf, Contract
load_dotenv()
class InvoiceContract(Contract):
invoice_number: str
invoice_date: str
# 设置 Tesseract 可执行文件的路径
test_file_path = os.path.join("path_to_your_files", "invoice.pdf")
# 初始化提取器
extractor = Extractor()
extractor.load_document_loader(DocumentLoaderPyPdf())
extractor.load_llm("gpt-4o-mini") # 或任何其他支持的模型
# 从文档中提取数据
result = extractor.extract(test_file_path, InvoiceContract)
print("Invoice Number:", result.invoice_number)
print("Invoice Date:", result.invoice_date)
Categorization Example
ExtractThinker allows to categorize documents or document sections using custom classifications:
import os
from dotenv import load_dotenv
from extract_thinker import Extractor, Classification, Process, ClassificationStrategy
load_dotenv()
class CustomClassification(Classification):
category: str
# 初始化提取器
extractor = Extractor()
extractor.load_classification_strategy(ClassificationStrategy.CUSTOM)
# 定义分类策略
classification = CustomClassification(category="Invoice")
# 从文档中分类数据
result = extractor.classify(test_file_path, classification)
print("Category:", result.category)
Detailed function operation flow
- Loading Documents: Load documents using supported document loaders (e.g. PyPdf, Tesseract OCR, etc.).
- Definition of withdrawal contracts: Define a custom extraction contract using the Pydantic model, specifying the fields to be extracted.
- Initialize the extractor: Create an Extractor instance and load the document loader and LLM model.
- Extract data: Call
extractmethod extracts data from the document and returns results based on contractually defined fields. - Category Documents: To classify a document or part of a document using a custom classification policy, call the
classifymethod to get the classification results.
With the above steps, users can efficiently extract and classify data from documents of various formats and optimize the document processing flow.