
General Introduction Trackers is an open source Python tool library focused on multi-object tracking in video. It integrates several leading tracking algorithms such as SORT and DeepSORT, allowing users to combine different object detection models (e.g. YOLO, RT-DETR) for flexible video analysis. Users ...

General Introduction Describe Anything is an open source project developed by NVIDIA and several universities, with the Describe Anything Model (DAM) at its core. This tool generates a detailed image or video based on the areas (such as dots, boxes, doodles, or masks) that the user marks in the...
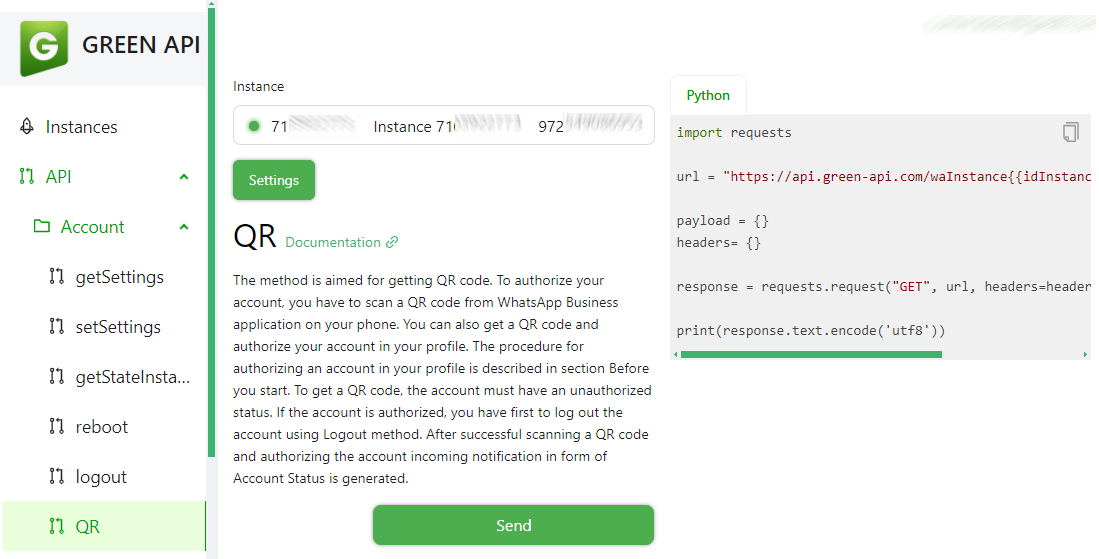
综合介绍 Find My Kids 是一个开源项目,托管在 GitHub 上,由开发者 Tomer Klein 创建。它结合了 DeepFace 人脸识别技术和 WhatsApp Green API,旨在帮助家长通过 WhatsApp 群组...
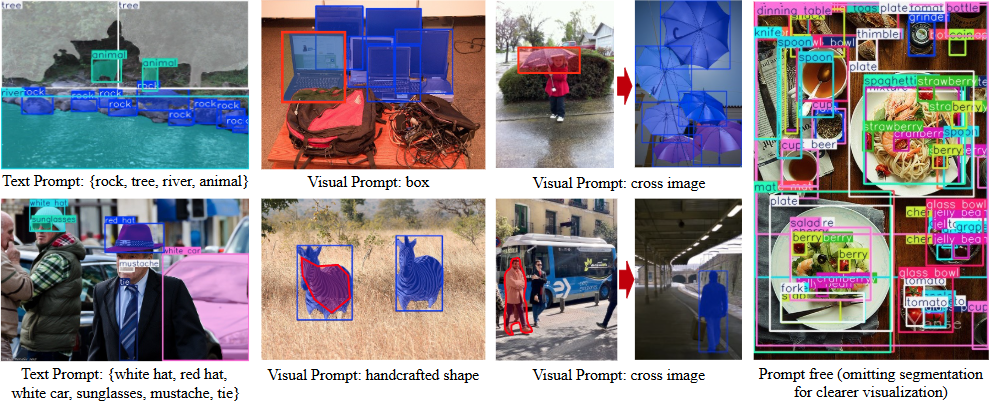
综合介绍 YOLOE 是清华大学软件学院多媒体智能组(THU-MIG)开发的一个开源项目,全称“You Only Look Once Eye”。它基于 PyTorch 框架,属于 YOLO 系列的扩展,能实时检测和分割任何物体。项目托管在 ...
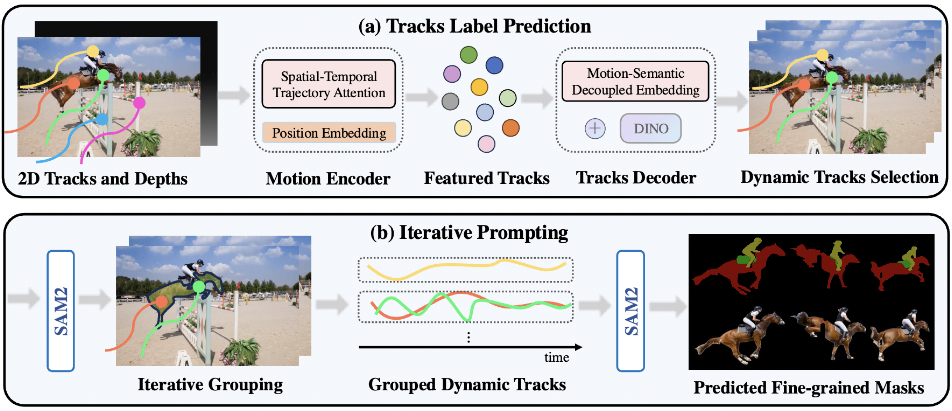
General Introduction SegAnyMo is an open source project developed by a team of researchers at UC Berkeley and Peking University, including members such as Nan Huang. This tool focuses on video processing and can automatically recognize and segment arbitrary moving objects in a video, such as people, animals or vehicles. It combines TAP...

综合介绍 RF-DETR 是 Roboflow 团队开发的一个开源对象检测模型。它基于 Transformer 架构,核心特点是实时高效。模型在微软 COCO 数据集上首次实现超过 60 AP 的实时检测,同时在 RF100-VL 基准测试...

General Introduction HumanOmni is an open source multimodal big model developed by the HumanMLLM team and hosted on GitHub. It focuses on analyzing human video and can process both picture and sound to help understand emotion, movement, and conversational content. The project used 2.4 million human-centered video clips and...

General Introduction Vision Agent is an open-source project developed by LandingAI (Enda Wu's team) and hosted on GitHub, designed to help users quickly generate code that solves computer vision tasks. It utilizes an advanced agent framework and a multimodal model to generate efficient by simple prompts...

General Introduction Make Sense is a free online image annotation tool designed to help users quickly prepare datasets for computer vision projects. It requires no complicated installation, just open a browser access to use it, supports multiple operating systems, and is perfect for small deep learning projects. Users can use it to...

综合介绍 YOLOv12 是由 GitHub 用户 sunsmarterjie 开发的一个开源项目,专注于实时目标检测技术。该项目基于 YOLO(You Only Look Once)系列框架,引入注意力机制优化传统卷积神经网络(CNN)的...
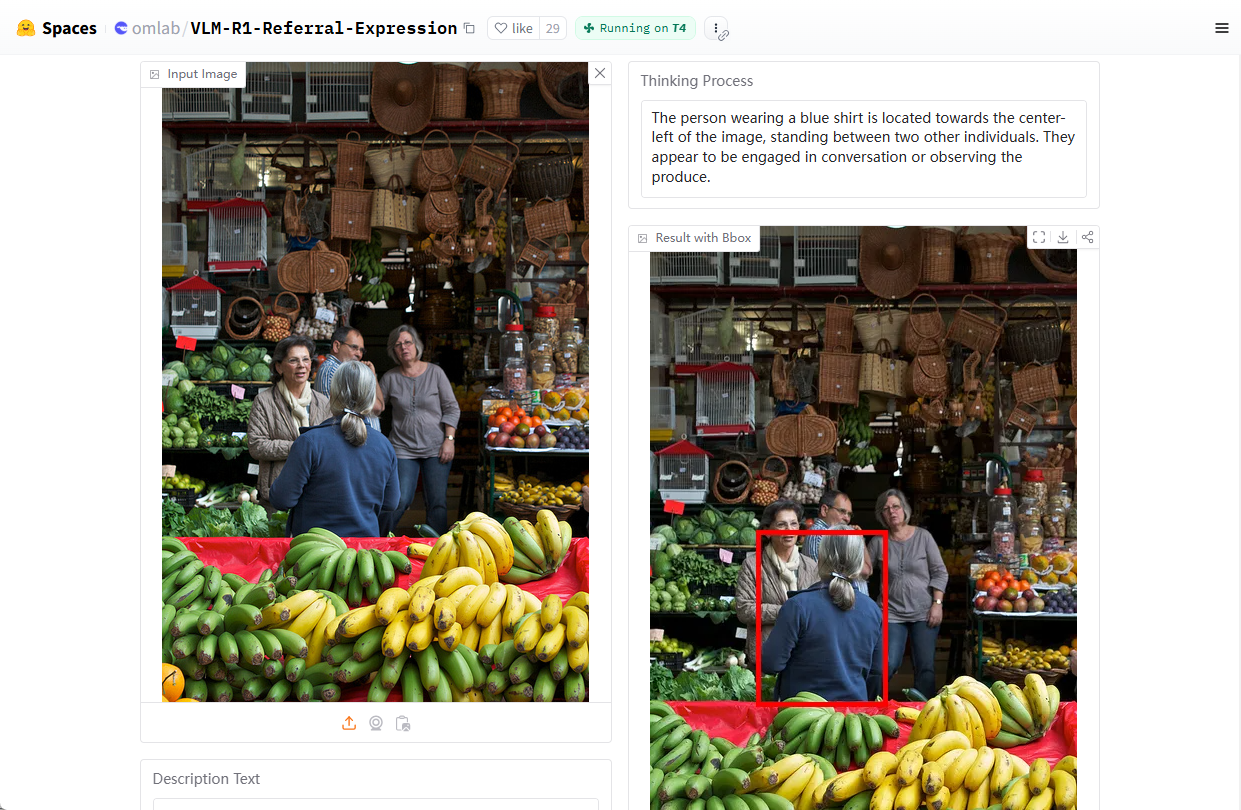
综合介绍 VLM-R1 是由 Om AI Lab 开发的一个开源视觉语言模型项目,托管在 GitHub 上。该项目基于 DeepSeek 的 R1 方法,结合 Qwen2.5-VL 模型,通过强化学习(R1)和监督微调(SFT)技术,显著提...
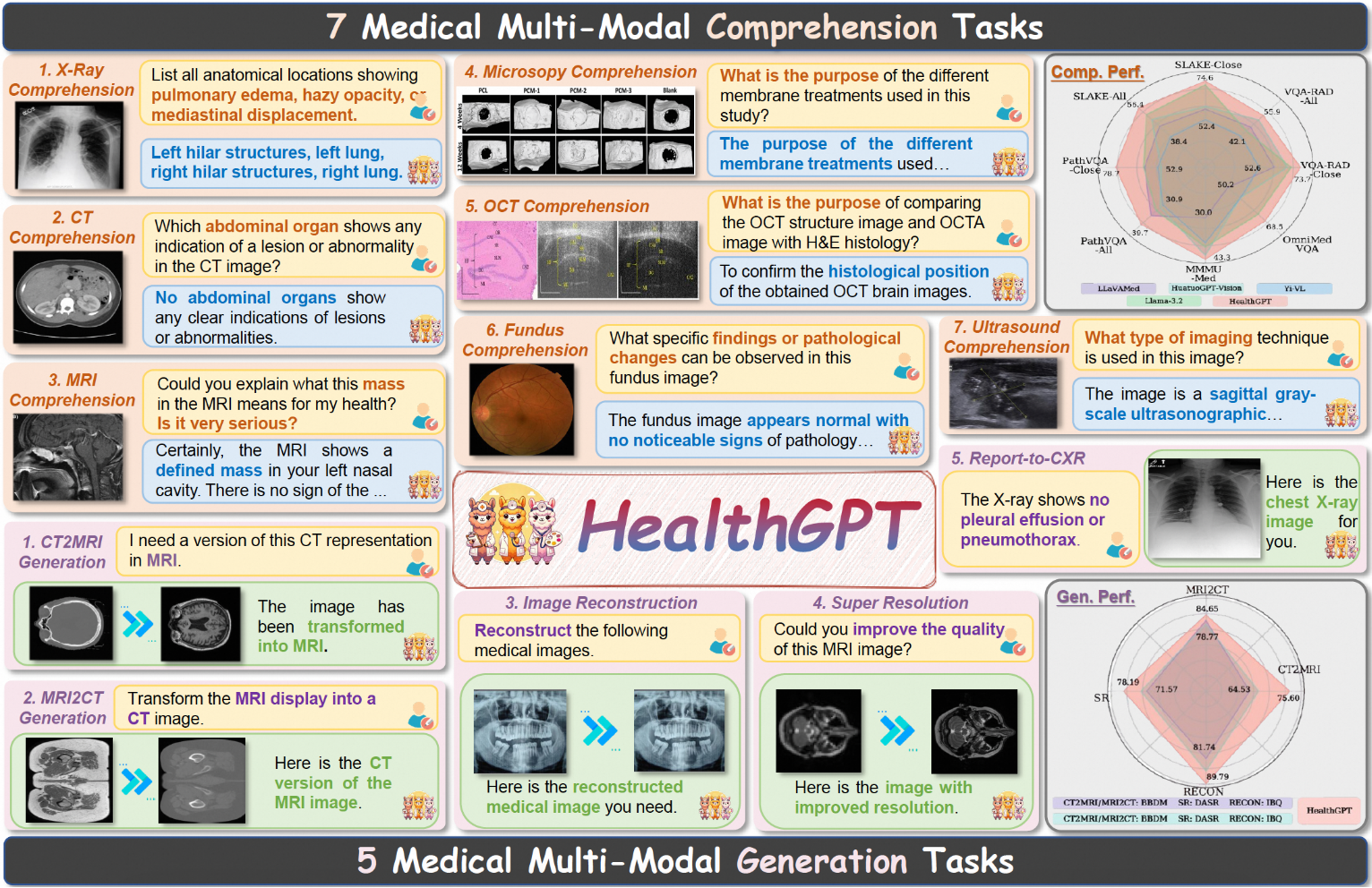
Comprehensive Introduction HealthGPT is a state-of-the-art medical grand visual language model designed to enable unified medical visual understanding and generation capabilities through heterogeneous knowledge adaptation. The goal of the project is to integrate medical vision understanding and generation capabilities into a unified autoregressive framework, significantly enhancing the medical image processing...
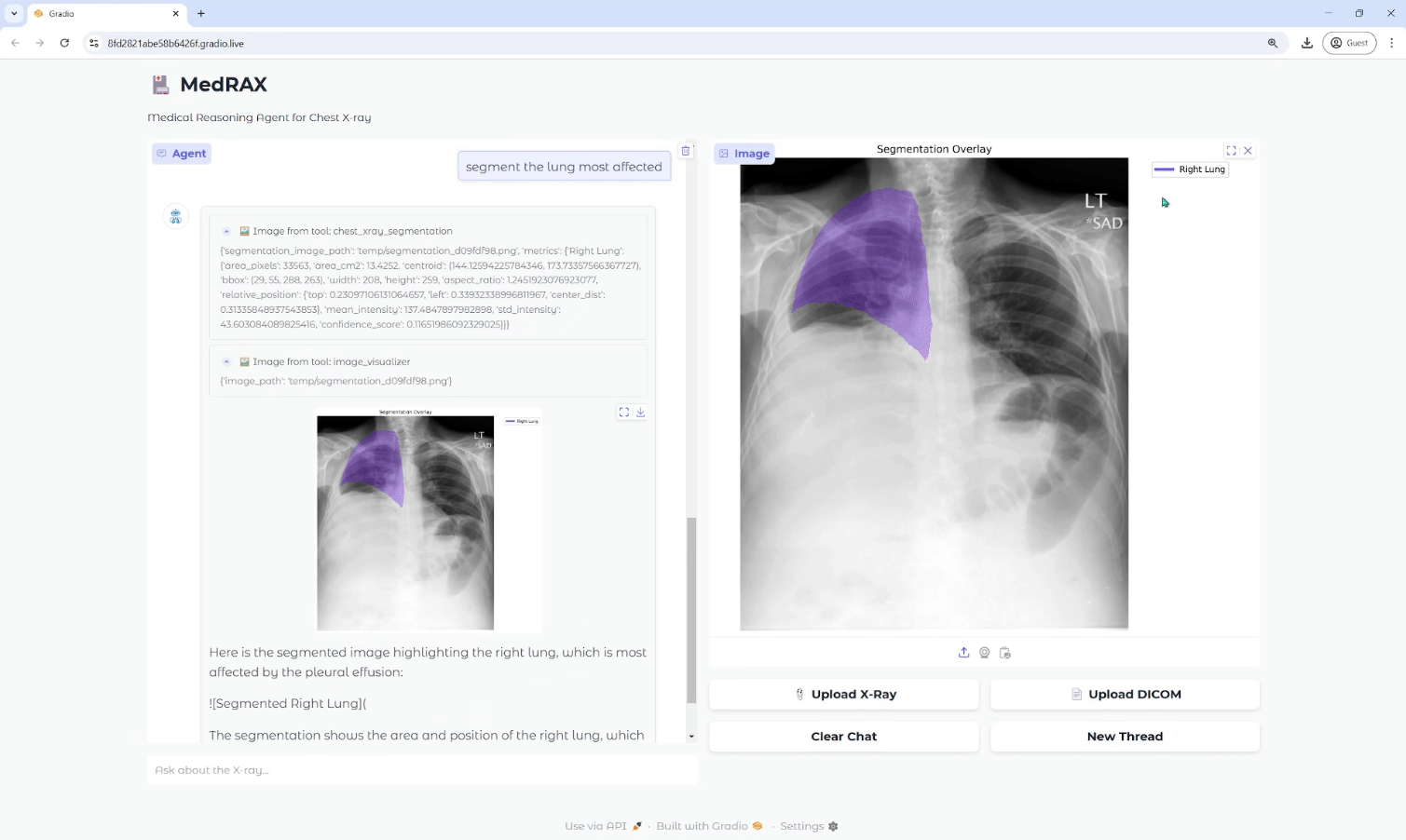
Comprehensive Introduction MedRAX is a state-of-the-art AI intelligence designed specifically for Chest X-ray (CXR) analysis. It integrates state-of-the-art CXR analysis tools and a multimodal large language model to dynamically process complex medical queries without additional training.MedRAX, through its modular design and strong technological base,...
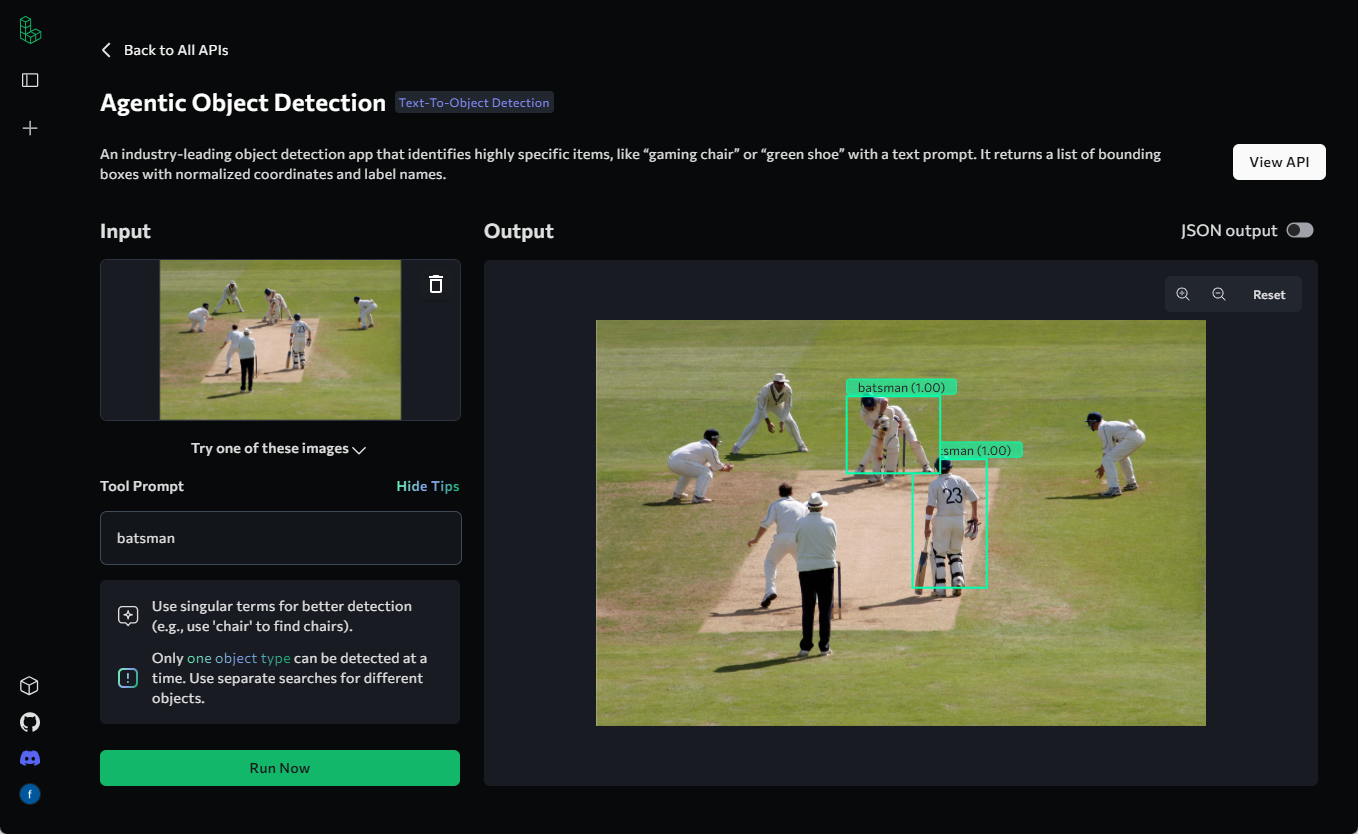
综合介绍 Agentic Object Detection 是由 Landing AI 推出的先进目标检测工具。该工具通过文本提示进行检测,无需进行数据标注和模型训练,极大地简化了传统目标检测的流程。用户只需上传图像并输入检测提示,AI ....

General Introduction CogVLM2 is an open source multimodal model developed by the Tsinghua University Data Mining Research Group (THUDM), based on the Llama3-8B architecture, and designed to provide performance comparable to or even better than GPT-4V. The model supports image understanding, multi-round dialog, and video understanding, and is capable of handling content up to 8K long...
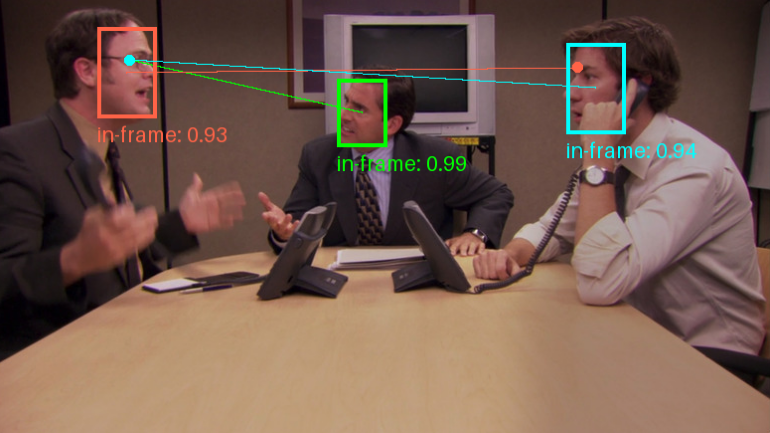
综合介绍 Gaze-LLE是一款基于大规模学习编码器的注视目标预测工具。该项目由Fiona Ryan、Ajay Bati、Sangmin Lee、Daniel Bolya、Judy Hoffman和James M. Rehg开发,旨在通过预...
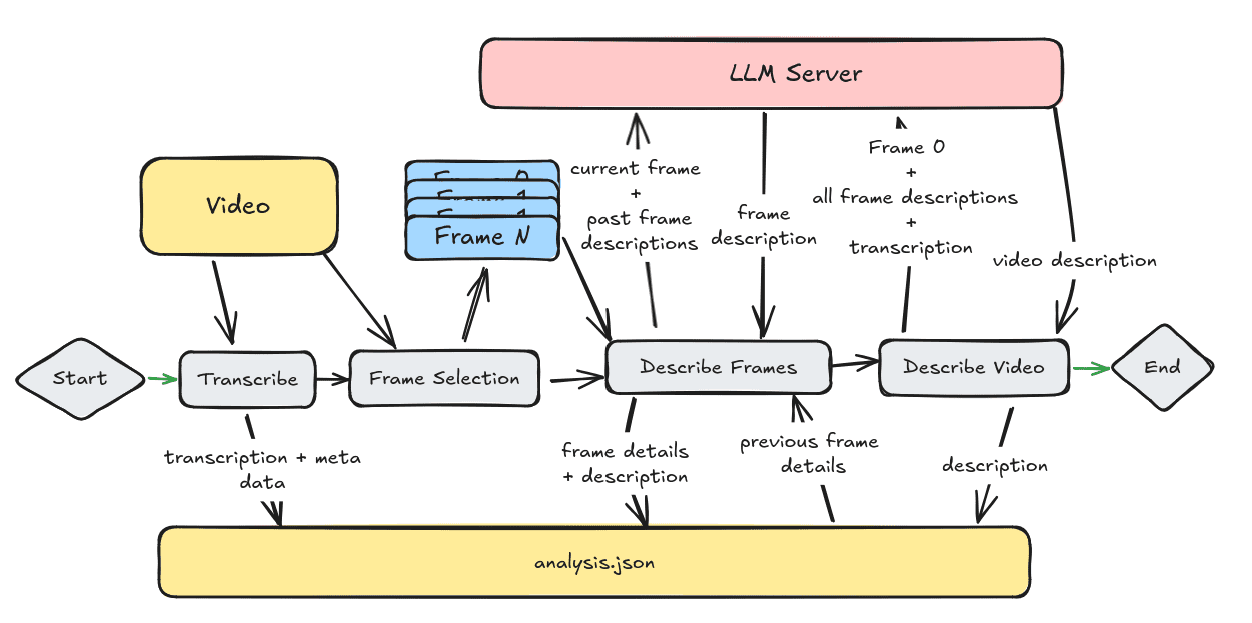
Comprehensive Introduction Video Analyzer is a comprehensive video analysis tool that combines computer vision, audio transcription, and natural language processing techniques to generate detailed video content descriptions. The tool does this by extracting key frames from the video, transcribing audio content, and generating natural language...
General Introduction Twelve Labs is a multimodal AI company focused on video understanding, dedicated to helping users understand and process large amounts of video content through advanced AI technologies. Its core technologies include video search, generation, and embedding that can extract key features from video such as actions, objects, on-screen text,...


