
Versatile OCR Program is an open source Optical Character Recognition (OCR) tool designed specifically for processing complex academic and educational documents. It can extract text, tables, mathematical formulas, diagrams and schematics from PDF, images and other documents and generate structured data suitable for machine learning training. Support...
It automatically analyzes the layout of PDF documents, identifies text, titles, images, tables, formulas and other elements in the page, and determines their correct order. The tool supports OCR functionality , you can convert scanned PDF to searchable text . It runs on Docker and provides two models: visual model (Vision Grid ...
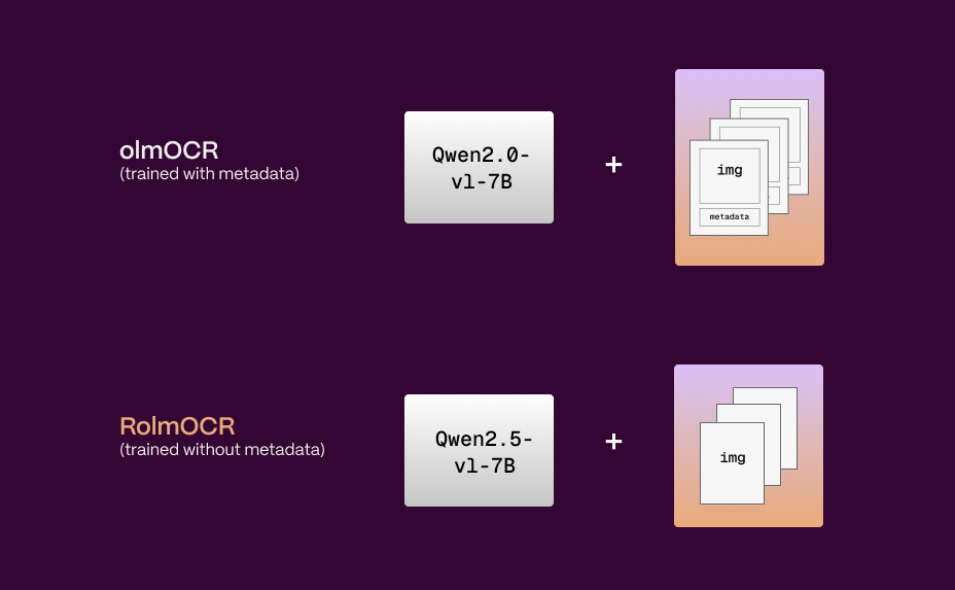
RolmOCR is an open source Optical Character Recognition (OCR) tool developed by Reducto AI team, based on Qwen2.5-VL-7B visual language model. It can extract text from images and PDF files faster than similar tools olmOCR, lower memory footprint.RolmOCR...
uniOCR is an open source text recognition tool developed by the mediar-ai team. It is based on the Rust language and supports macOS, Windows and Linux. It supports macOS, Windows and Linux systems. It allows users to extract text from images, and is easy and free to use. uniOCR's core feature is cross-platform support...

PDF Craft is an open source tool designed for scanning PDFs of books and converting them to Markdown format. It is developed by oomol-lab and hosted on GitHub for users who like to organize their eBooks. The tool runs through a local AI model without the need for an Internet connection, which protects privacy and facilitates operation. ....

SmolDocling is a Visual Language Model (VLM) developed by ds4sd team in collaboration with IBM, based on SmolVLM-256M, hosted on Hugging Face platform. SmolDocling is a visual language model (VLM) based on SmolVLM-256M, hosted on the Hugging Face platform, which is the world's smallest VLM with only 256M parameters.

In the long history of human civilization, every leap in the way information is acquired and parsed has profoundly driven social progress. From the ancient hieroglyphics, to the portable papyrus, to the later emergence of the printing press and today's wave of digitization, each technological innovation has greatly expanded the transmission of human knowledge...
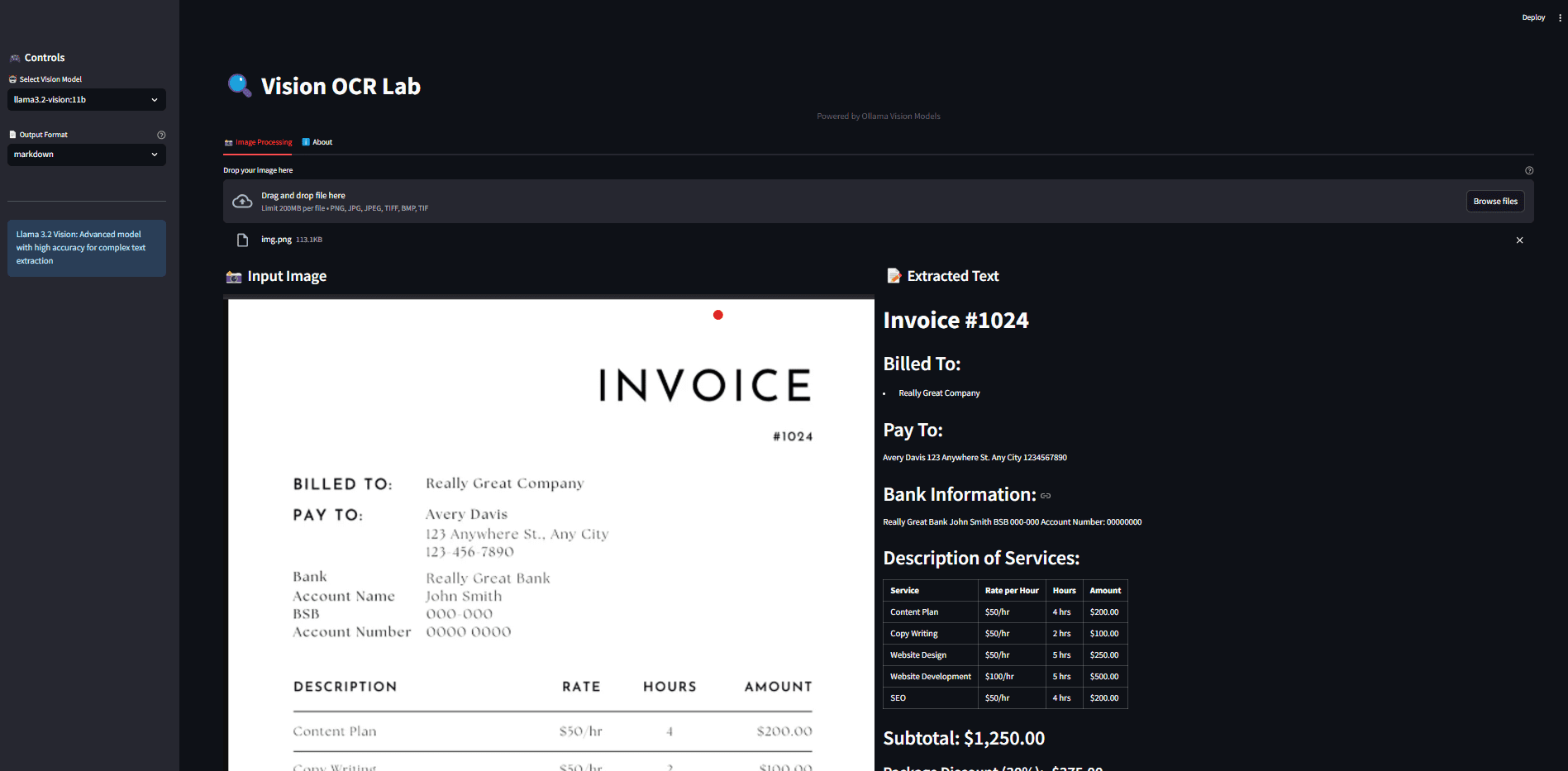
Ollama OCR is a powerful Optical Character Recognition (OCR) toolkit that utilizes the state-of-the-art visual language model provided by the Ollama platform to extract text from images. The project is available both as a Python package and provides a user-friendly Streamlit web application interface. It supports a wide range of visual models...

STranslate is a ready-to-use translation and OCR tool developed by WPF. The tool is designed to provide efficient and convenient translation and Optical Character Recognition (OCR) functionality for a wide range of languages and text types.STranslate is an open source project that is free for users to download and use, and also accepts...
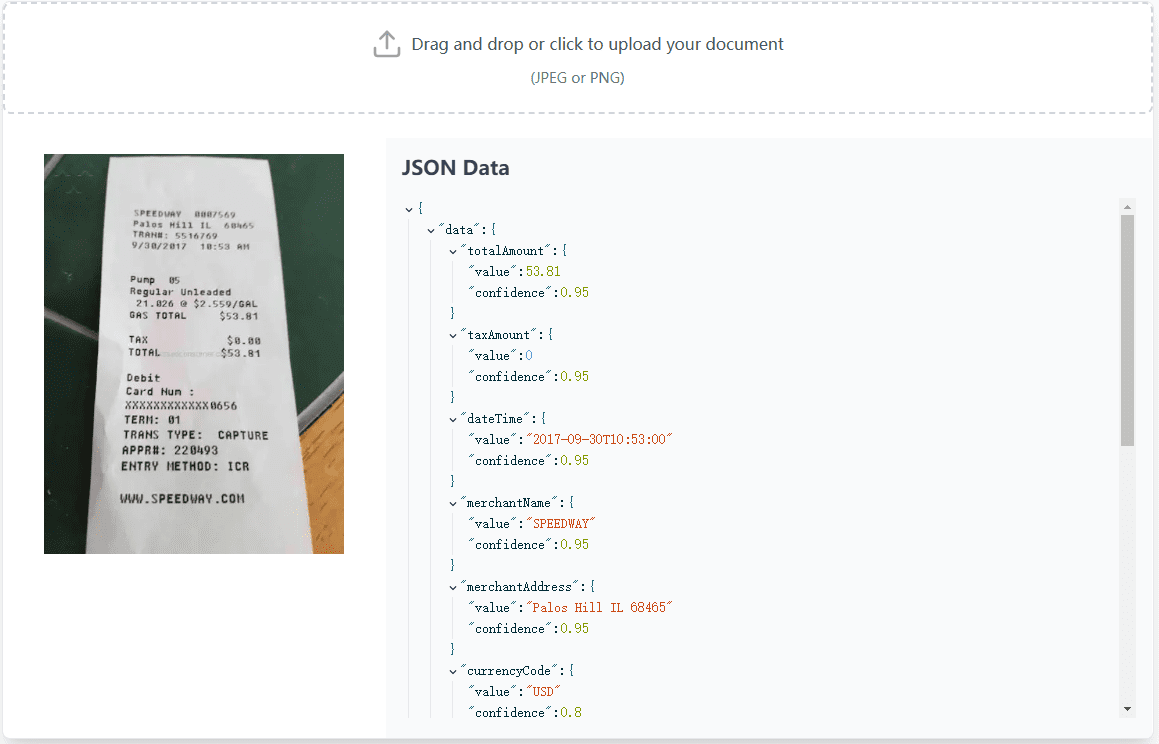
VisionParser is an OCR (Optical Character Recognition) tool designed for processing receipts and invoices. With advanced generative AI technology, VisionParser is able to quickly and accurately convert all kinds of receipts and invoices into structured data for a wide range of business scenarios, such as retail, food and beverage, and B2B services....
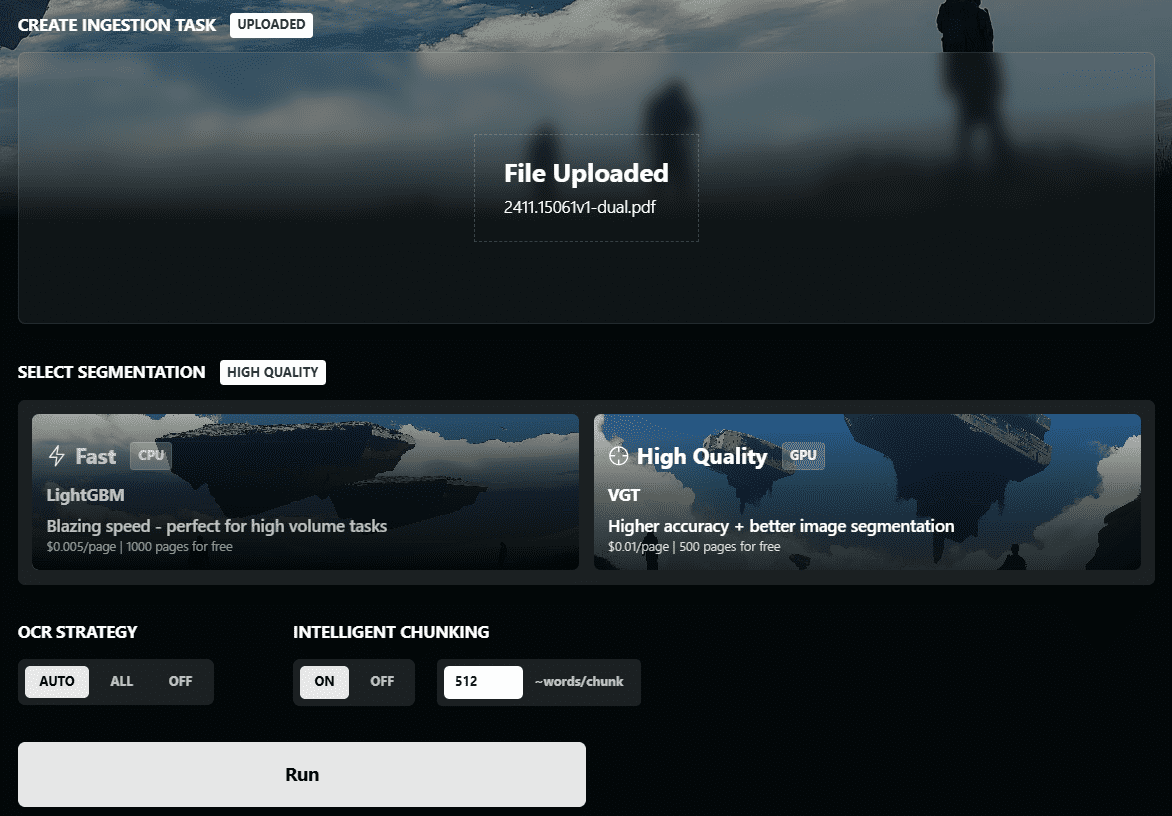
Chunkr is a self-hosted API specialized in converting PDF, PPTX, DOCX, and Excel files into data suitable for use in RAG (Retrieval Augmented Generation) and LLM (Large Language Modeling). It was developed by Lumina AI Inc. and utilizes advanced visual models for document...
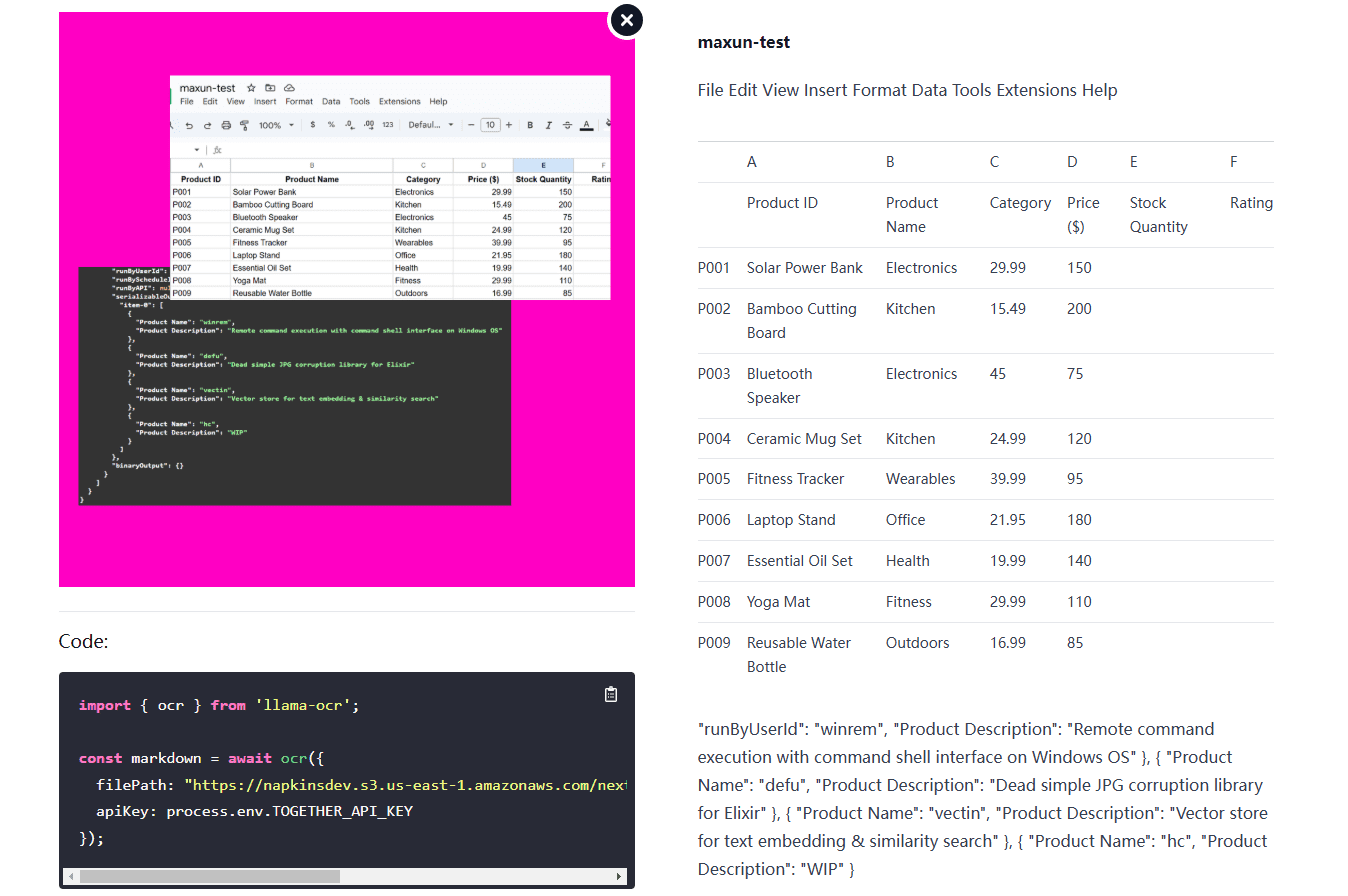
Llama OCR is an OCR (Optical Character Recognition) library based on Llama 3.2 Vision that converts documents to Markdown format. The library was developed by Nutlope and uses the free Llama 3.2 interface provided by Together AI for graph...

Docling is a powerful document parsing and exporting tool that supports a wide range of document formats including PDF, DOCX, PPTX, XLSX, Image, HTML, AsciiDoc, and Markdown.It parses and exports these documents to HTML, Markdown, and JSON formats....
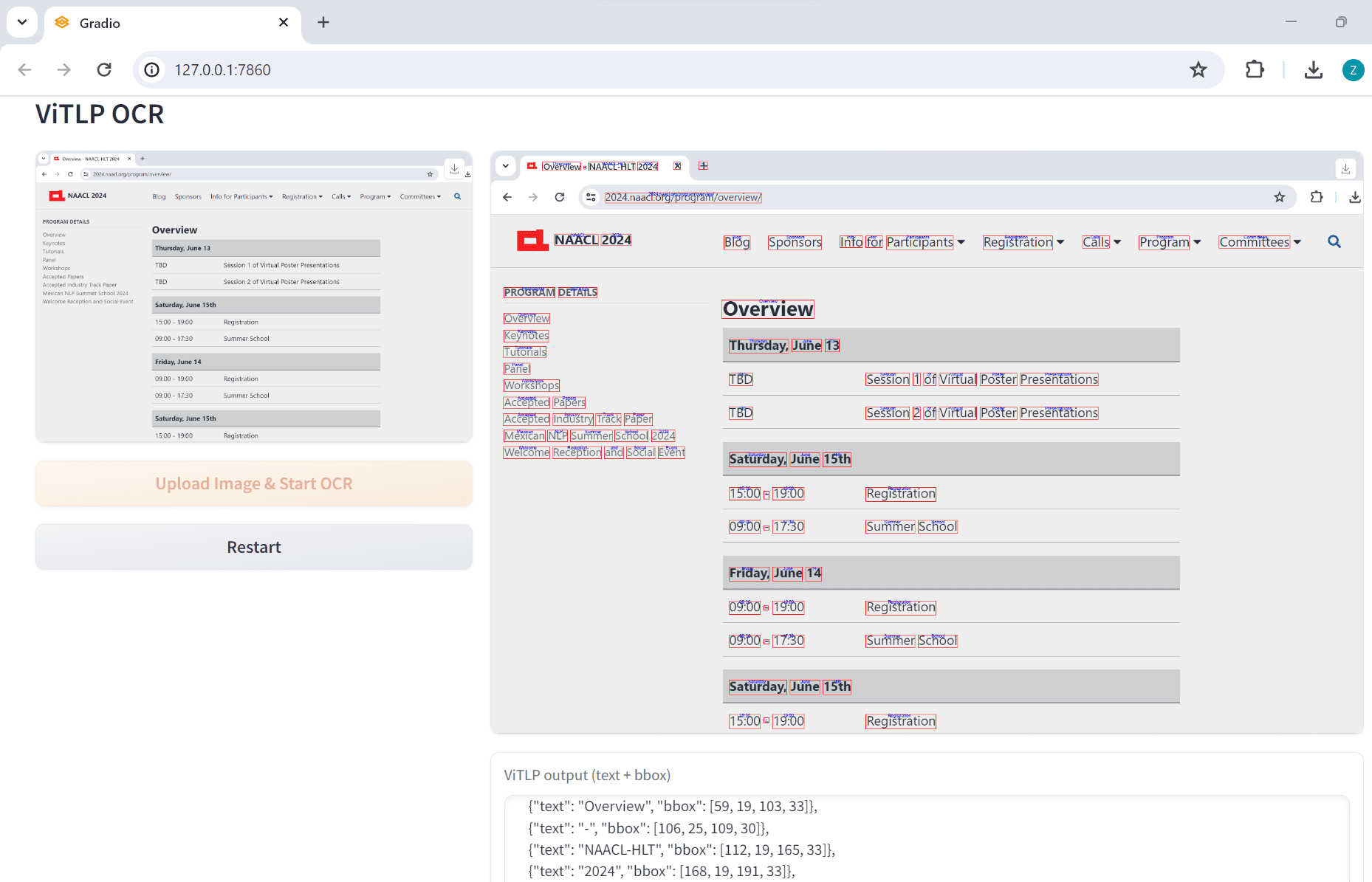
ViTLP (Visually Guided Generative Text-Layout Pre-training for Document Intelligence) is an open source project that aims to enhance document intelligence processing through visually guided generative text-layout pre-training model...

ScreenPipe is an AI assistant developed by mediar-ai that specializes in recording screen content, capturing screenshots and audio 24/7. It combines the technologies of rewind.ai and cursor.com to store recorded data in a local database and supports Chinese...
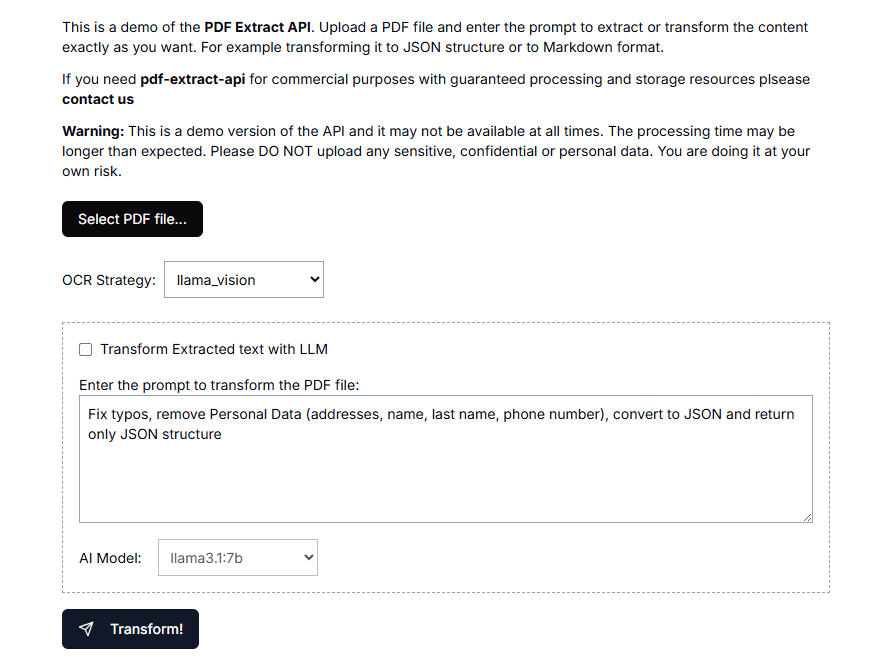
The Text Extraction API (text-extract-api) is a powerful tool designed to extract and parse content from a variety of document formats (e.g. PDF, Word, PPTX, etc.). The API utilizes state-of-the-art Optical Character Recognition (OCR) technology and Ollama-supported models to convert any document or image into a knot ....
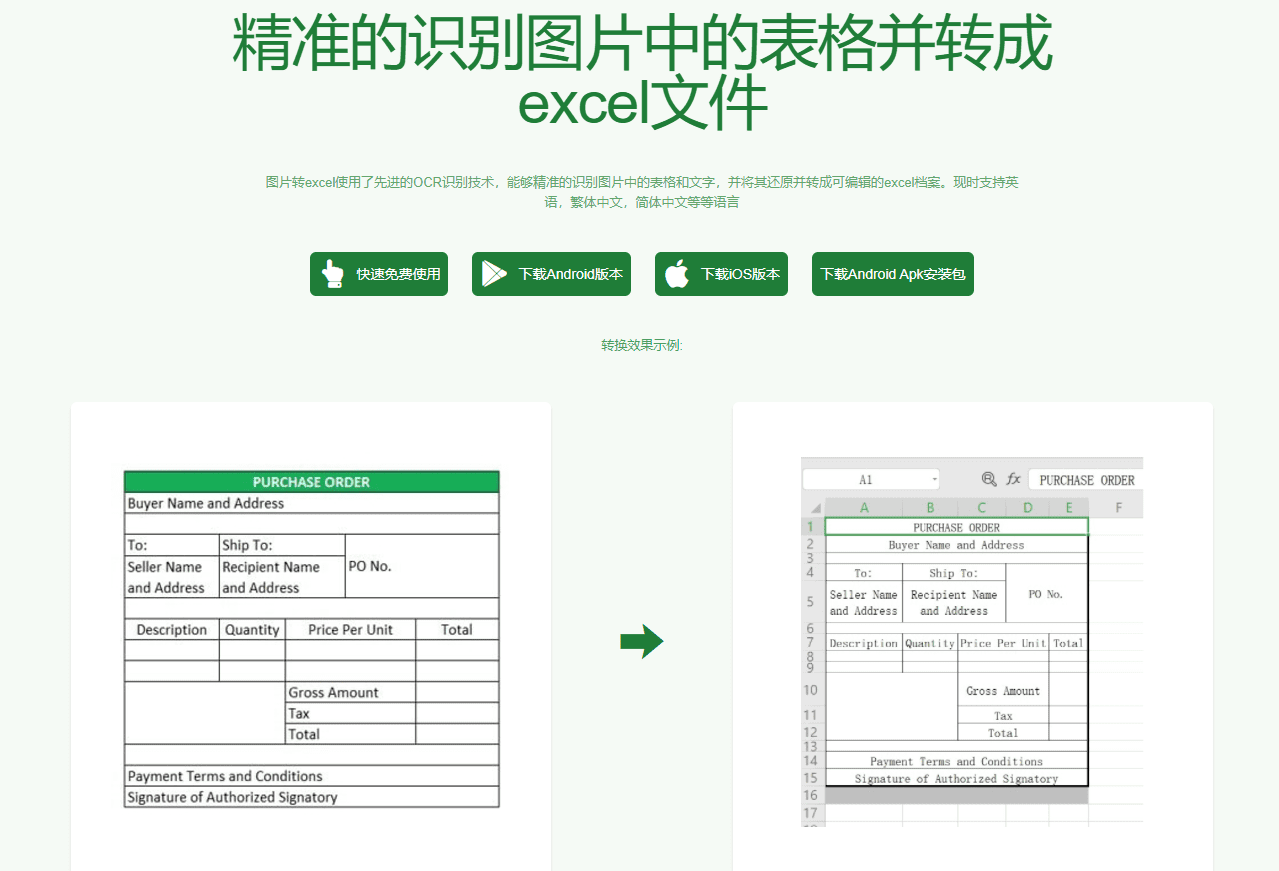
Picture to Excel Free Tool is an efficient online tool that quickly and accurately recognizes and converts tabular data from pictures to Excel files. The tool supports a wide range of image formats, such as JPG and PNG, and can be used on web pages, iOS apps and Android apps. With advanced AI technology, the worker...

Datalab offers a range of advanced AI models focused on OCR, layout analysis, PDF to Markdown, and more. These models are not only high performing, but also easy to use and open source. The Marker model on the platform can quickly and accurately convert PDF to Markdown, including tables and formulas.Su...
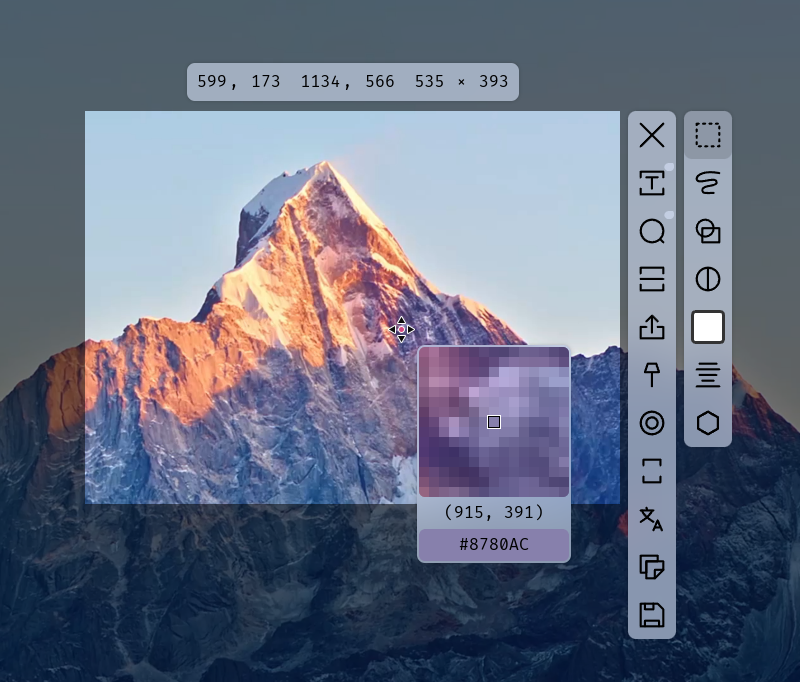
eSearch is an open source cross-platform screenshot tool developed by xushengfeng for Windows, macOS and Linux. eSearch integrates a variety of features including OCR recognition, search, translation, mapping, image search and screen recording. It integrates a variety of features including screenshot, OCR recognition, search, translation, mapping, image search and screen recording. eSearch uses Elec...

