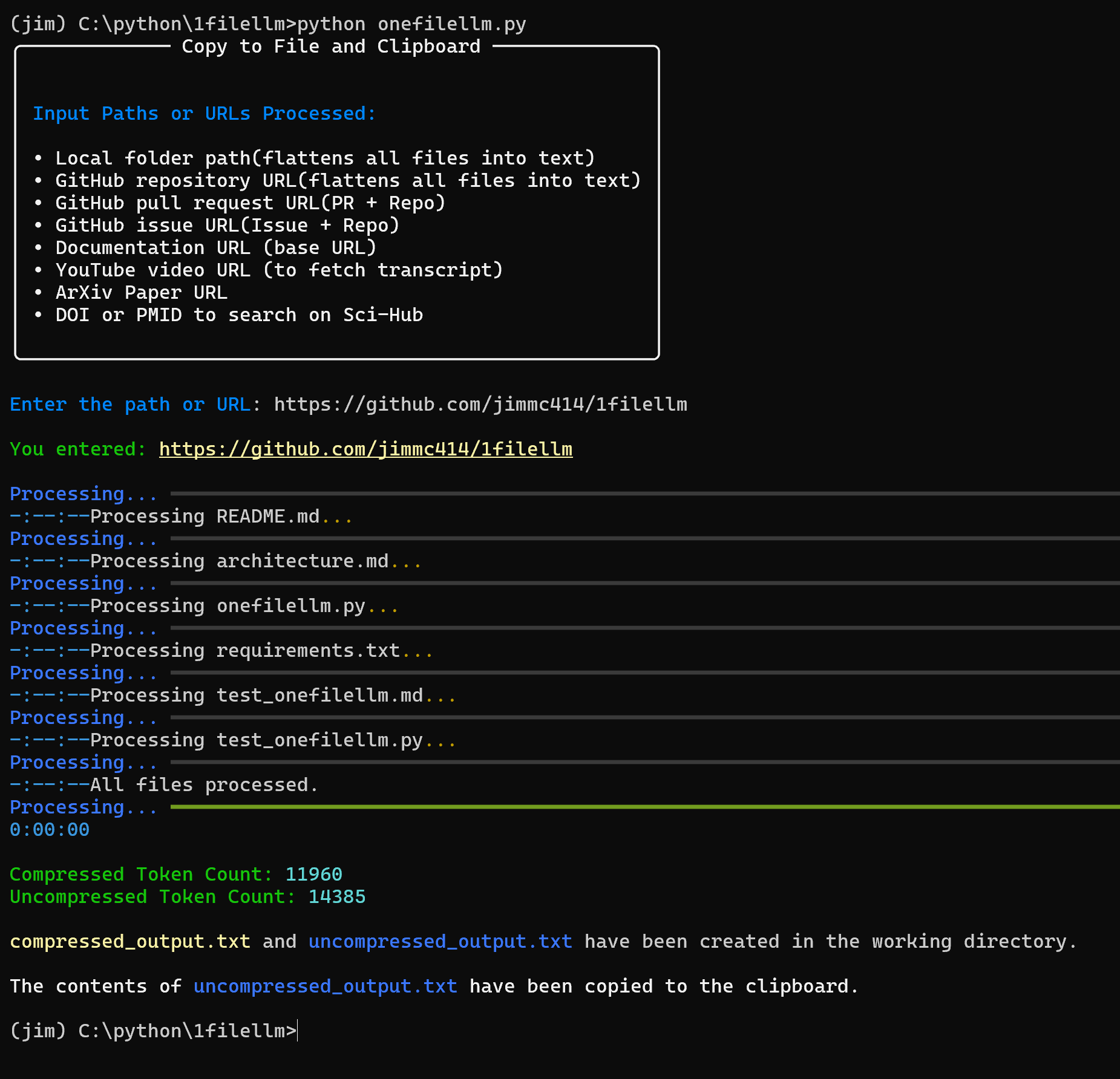
OneFileLLM is an open source command line tool designed to consolidate multiple data sources into a single text file for easy input into Large Language Models (LLMs). It supports processing GitHub repositories, ArXiv papers, YouTube video transcriptions, web content, Sci-Hub papers and local files, automatically generating the structure...
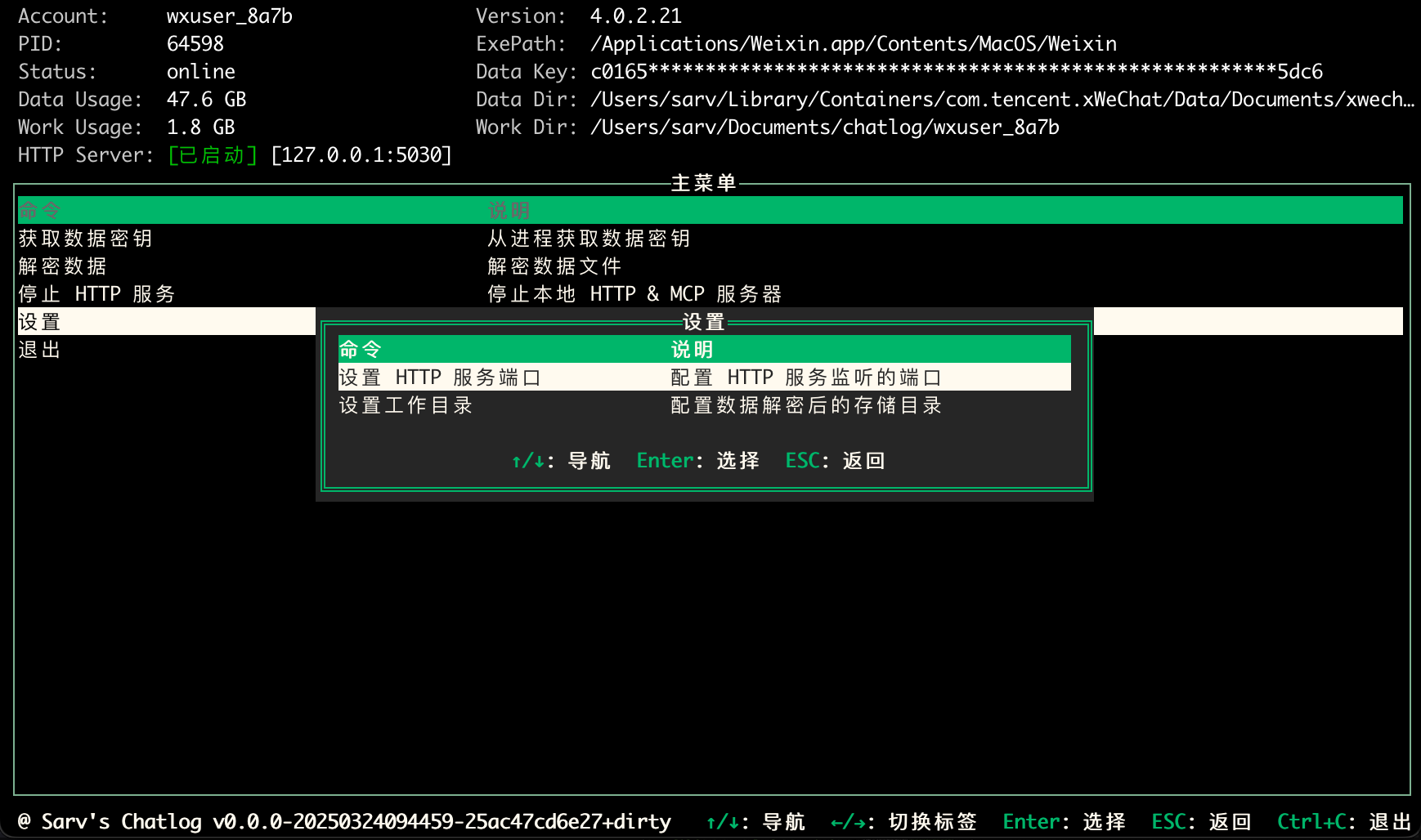
Chatlog is an open source tool that focuses on extracting and querying chat logs from WeChat's local database. It supports WeChat versions 3.x and 4.0, covering Windows and macOS systems. Users can operate from the command line, terminal interface or HTTP API to view chat logs, contacts, group chats and...

Versatile OCR Program is an open source Optical Character Recognition (OCR) tool designed specifically for processing complex academic and educational documents. It can extract text, tables, mathematical formulas, diagrams and schematics from PDF, images and other documents and generate structured data suitable for machine learning training. Support...
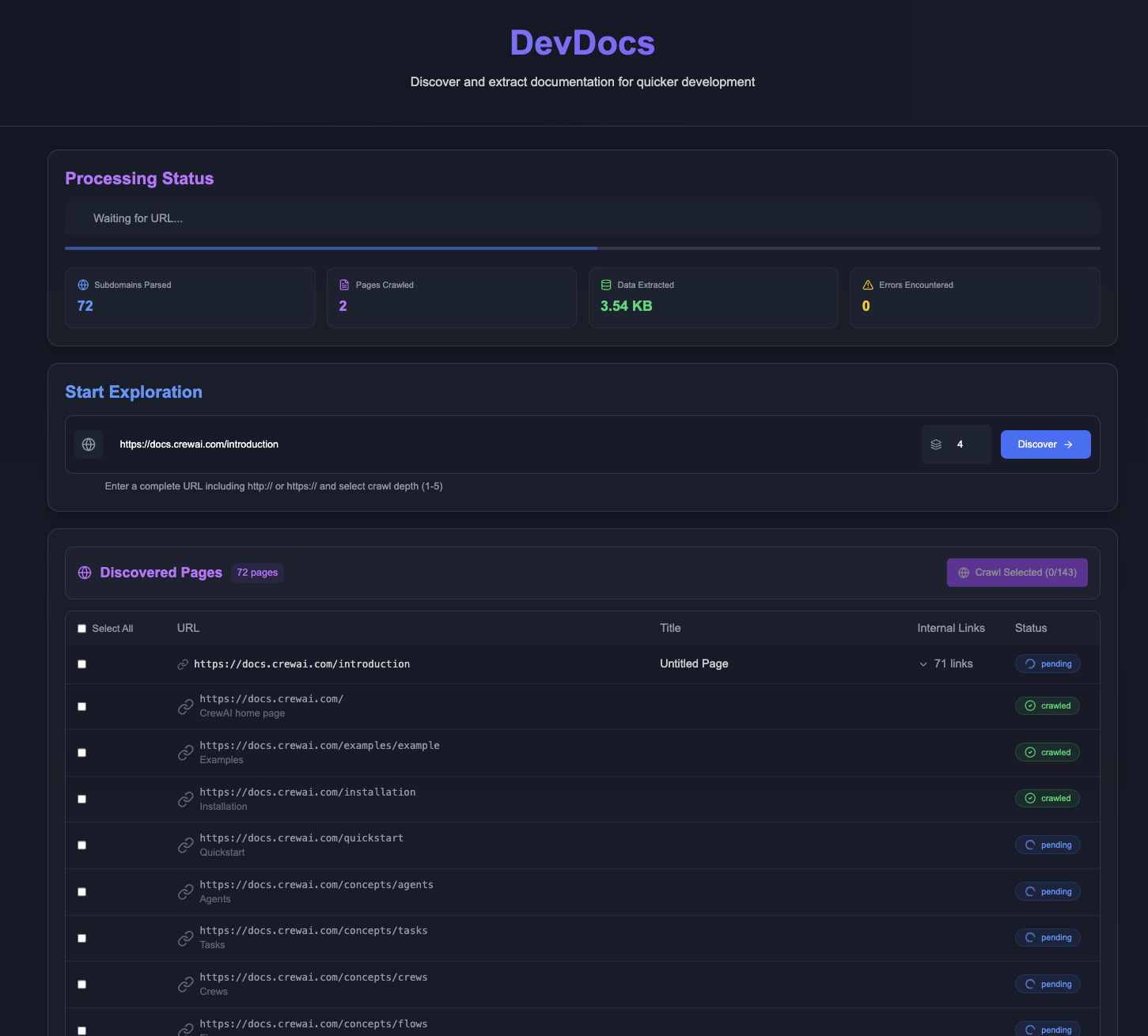
DevDocs is a completely free and open source tool developed by the CyberAGI team and hosted on GitHub. It is designed for programmers and software developers to start from the URL of the technical documentation, automatically crawl the relevant pages and organize them into concise Markdown or JSON files. It has a built-in MCP ...
It automatically analyzes the layout of PDF documents, identifies text, titles, images, tables, formulas and other elements in the page, and determines their correct order. The tool supports OCR functionality , you can convert scanned PDF to searchable text . It runs on Docker and provides two models: visual model (Vision Grid ...

serverless-markdown-convertor is a free open source tool based on Cloudflare Worker and Workers AI that converts a wide range of files to Markdown format. It supports PDF, images, Office documents ...
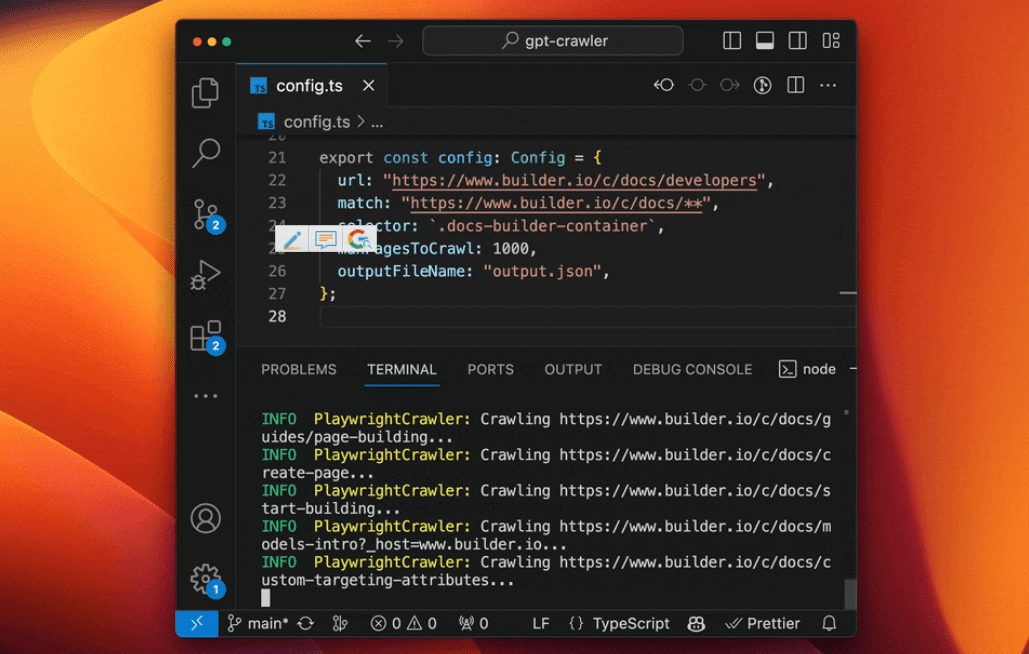
GPT-Crawler is an open source tool developed by the BuilderIO team and hosted on GitHub. It crawls page content by entering one or more website URLs, generating a structured knowledge file (output.json) that can be used to create a custom GPT or AI assistant. Users...
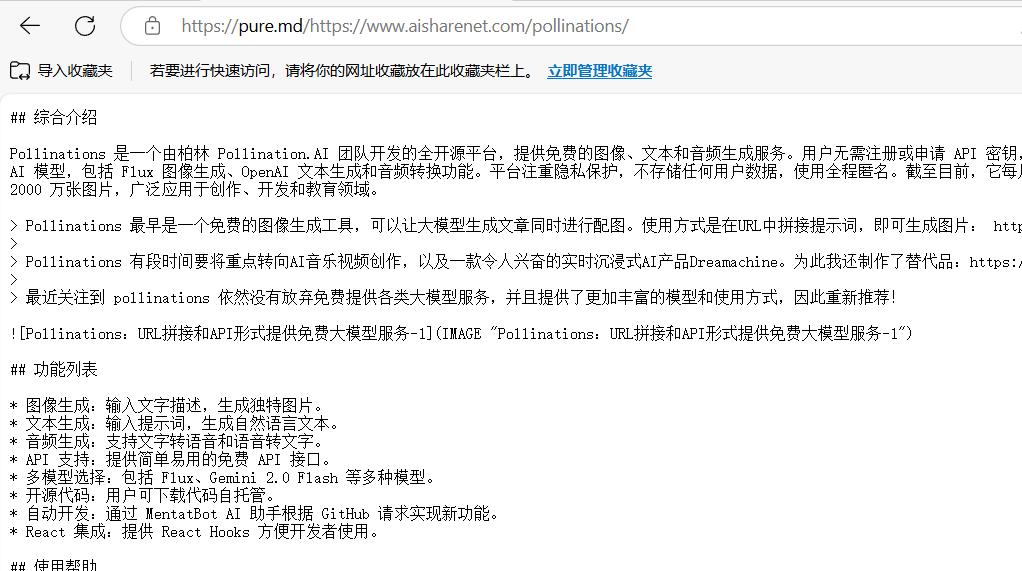
pure.md is a tool designed for AI agents and developers that focuses on quickly converting web content or files to Markdown format. It bypasses anti-crawler restrictions through proxy services, extracts the core data of a web page, and outputs a clean Markdown file. Whether it's a dynamic web page, PDF file or social...
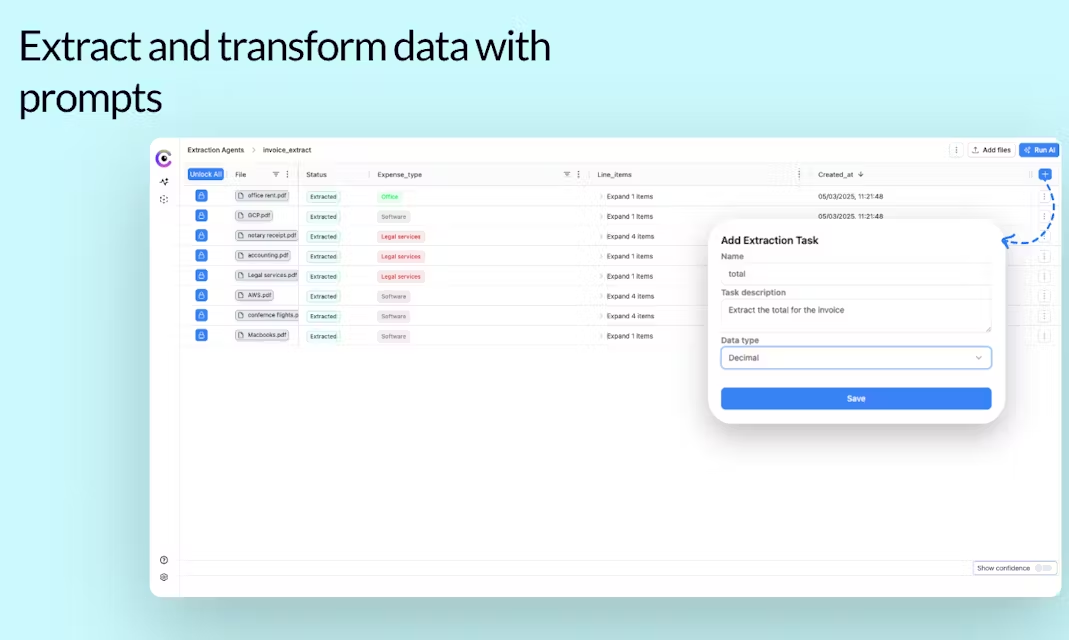
Cloudsquid is a 2023 Berlin, Germany-based company focused on simplifying document processing with artificial intelligence. Its core product is an online data extraction platform that allows users to upload PDFs, images, audio, video, and other files, and simply state the data to be extracted, such as "Find out the name and g...

PDF Craft is an open source tool designed for scanning PDFs of books and converting them to Markdown format. It is developed by oomol-lab and hosted on GitHub for users who like to organize their eBooks. The tool runs through a local AI model without the need for an Internet connection, which protects privacy and facilitates operation. ....
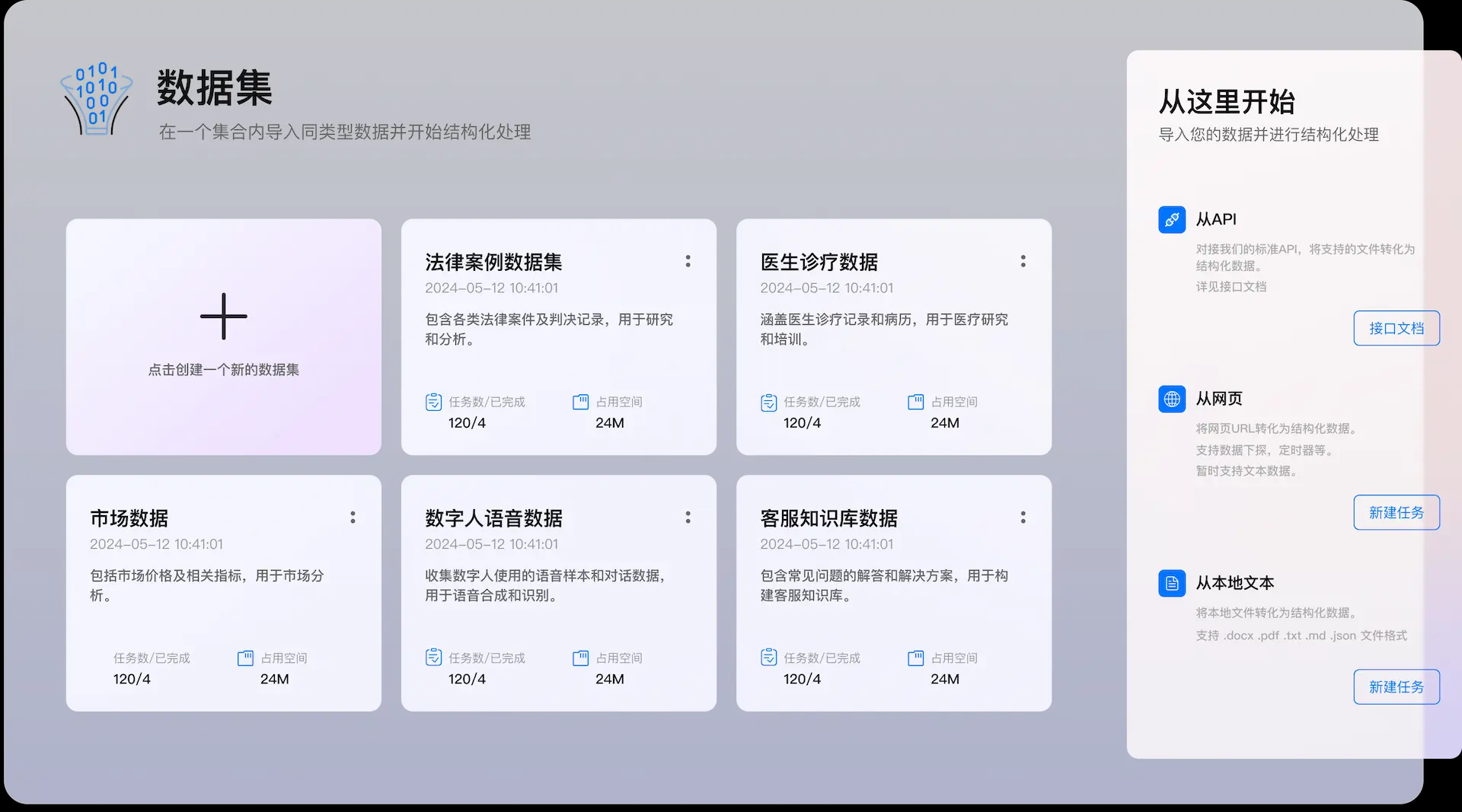
Supametas.AI is a data processing platform that specializes in organizing web pages, documents, audio and video, and other clutter into structured data that AI can use. It supports collecting data from multiple sources, including web links, APIs, local files, etc., and then exporting it to JSON or Markdown format. The platform requires no programming...

MarkPDFDown is an open source tool. It utilizes a multimodal large language model to convert PDF files into Markdown format. Developed by GitHub user jorben, this tool has a simple goal: to make PDF documents easier to edit and share. It recognizes headings, lists,...

SmolDocling is a Visual Language Model (VLM) developed by ds4sd team in collaboration with IBM, based on SmolVLM-256M, hosted on Hugging Face platform. SmolDocling is a visual language model (VLM) based on SmolVLM-256M, hosted on the Hugging Face platform, which is the world's smallest VLM with only 256M parameters.

The goal of table recognition is to parse tables in images, accurately identify table structures and cell locations, and reduce them to structured table formats (e.g., HTML). In today's information age, a large amount of important tabular data still exists in an unstructured state (e.g., pictures of information statistics in scanned documents, pd...

In the long history of human civilization, every leap in the way information is acquired and parsed has profoundly driven social progress. From the ancient hieroglyphics, to the portable papyrus, to the later emergence of the printing press and today's wave of digitization, each technological innovation has greatly expanded the transmission of human knowledge...

Firecrawl MCP Server is an open source tool developed by MendableAI , based on the Model Context Protocol (MCP) protocol implementation , integrated with the Firecrawl API to provide powerful web crawling and data extraction . It specializes in ...
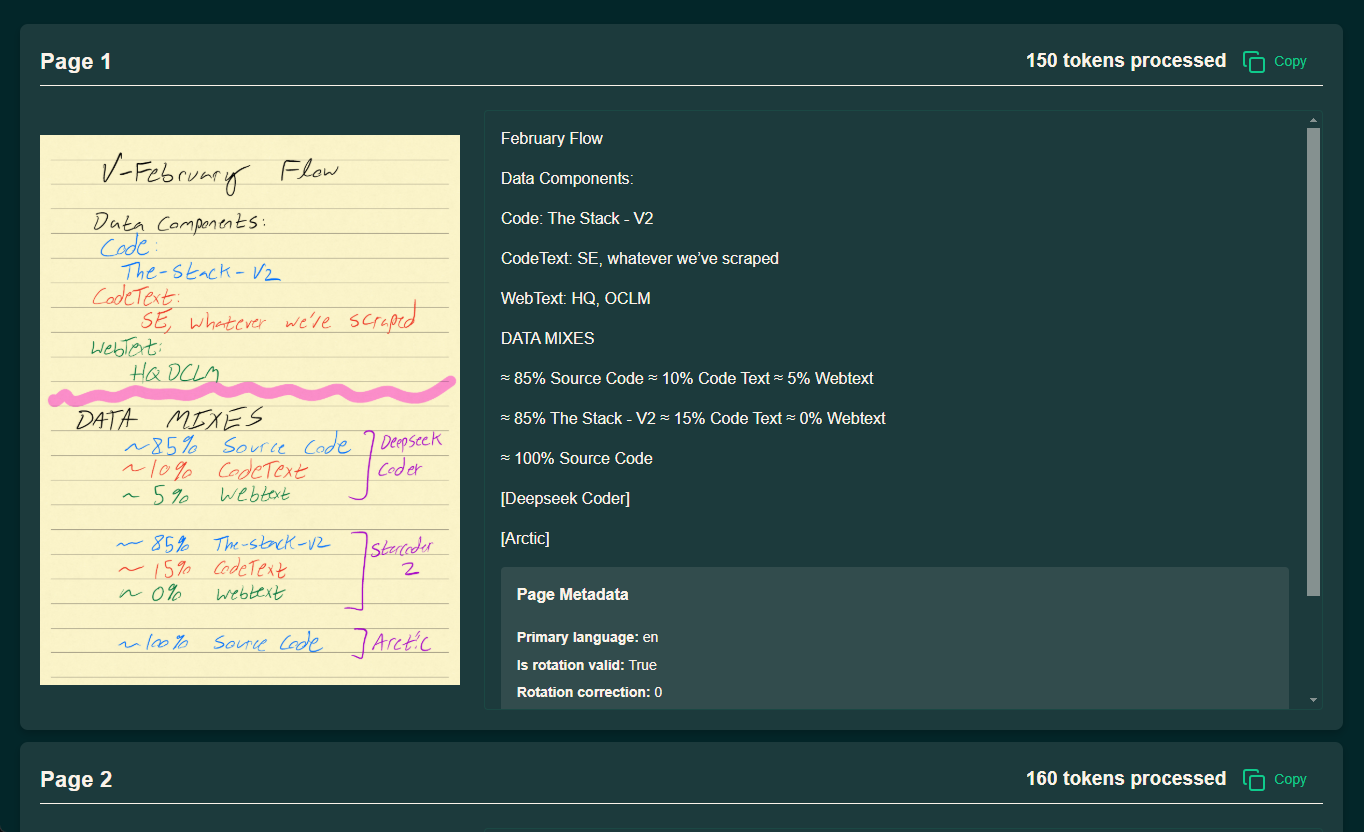
olmOCR is an open source tool developed by the AllenNLP team at the Allen Institute for Artificial Intelligence (AI2) that focuses on converting PDF files to linearized text, and is particularly well suited for use in large-scale language models (LL...
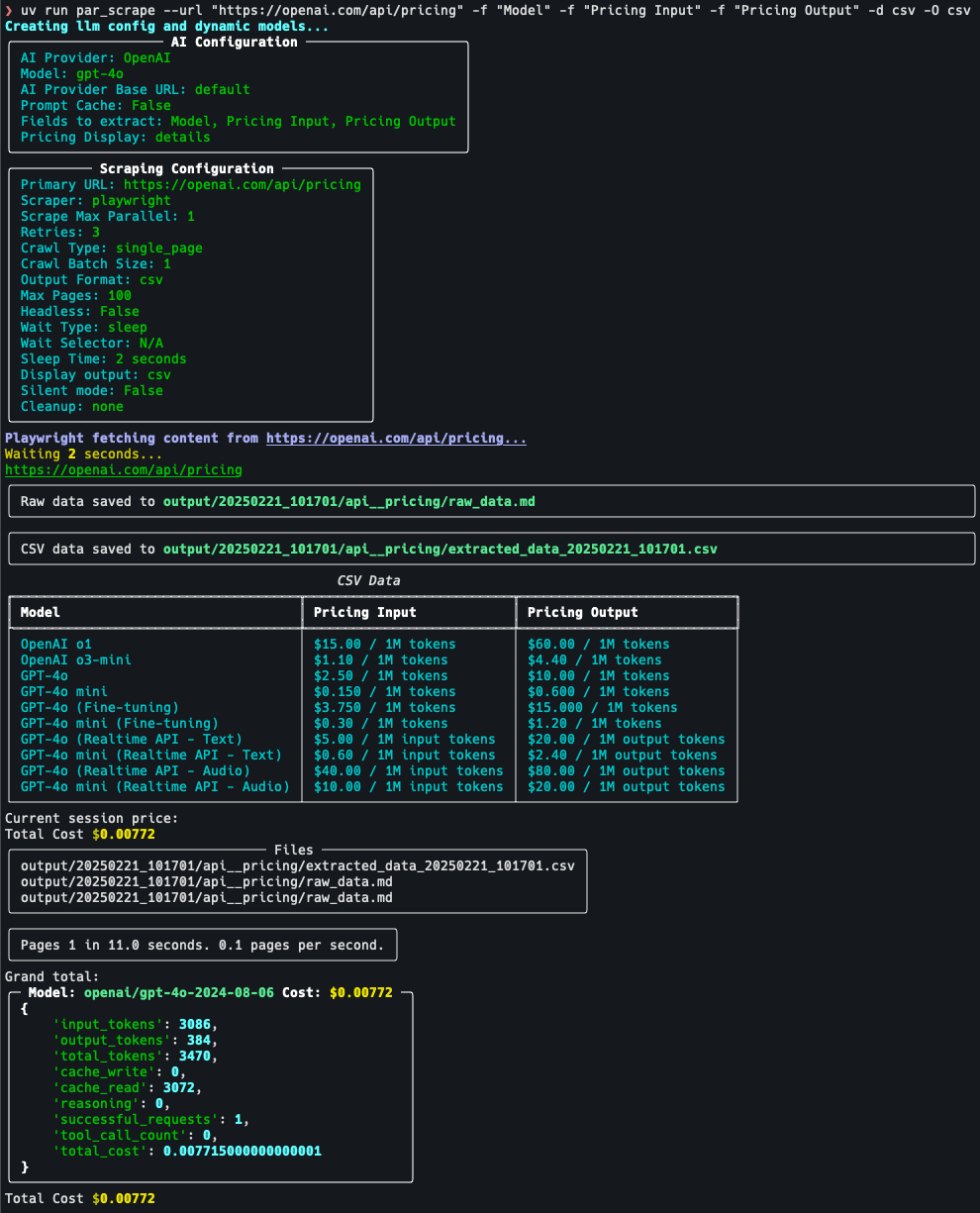
par_scrape is a Python-based open source web crawler tool, launched on GitHub by developer Paul Robello, designed to help users intelligently extract data from web pages. It integrates Selenium and Playwright, two powerful browser automation...

PDF-Extract-Kit is an open source project developed by the OpenDataLab team , focusing on the efficient extraction of high-quality content from complex and diverse PDF documents . It integrates advanced document parsing technology , support for layout detection , formula recognition , table extraction and OCR and other functions , applicable to academic papers , .....

