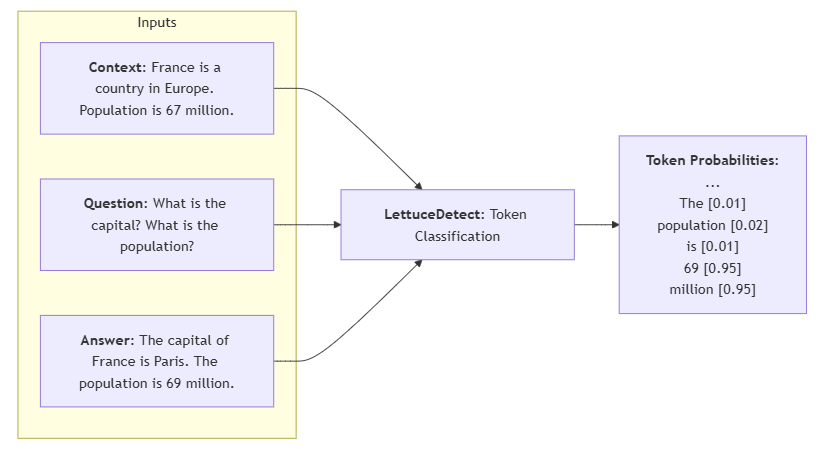
Kyutai Labs'delayed-streams-modelingProject is an open source speech-to-text conversion framework , the core is based on delayed stream modeling (DSM) technology . It supports real-time speech-to-text (STT) and text-to-speech (TTS) functions , suitable for building efficient voice interaction applications. The project provides multiple implementations in PyTorch, Rust and MLX to meet the needs of research, development and production environments. The model supports English and French with latency as low as 0.5 seconds, suitable for real-time dialog, voice assistant and translation scenarios. The project code is hosted on GitHub, with clear documentation and easy to get started.
Function List
- Real-time speech-to-text (STT): Supports English and French with latency as low as 0.5 seconds with semantic voice activity detection (VAD).
- Real-time text-to-speech (TTS): Generate natural speech with a delay of about 220 milliseconds and support long text generation.
- voice cloning: Only 10 seconds of audio is needed to clone a voice (feature not fully open-sourced).
- Multi-language support: English and French models are available, with partial support for experimental features in other languages.
- Efficient batch processing: The Rust server supports high concurrency, with up to 64 real-time audio streams on the L40S GPU.
- Cross-platform deployment: Support for PyTorch (research), Rust (production), MLX (Apple devices).
- timestamp output: The STT model returns word-level timestamps for easy caption generation or interactive control.
Using Help
Installation process
delayed-streams-modelingThe project supports a variety of deployment methods, depending on the usage scenario. The following is a detailed installation and usage guide:
1. PyTorch (research and experimentation)
Ideal for researchers and developers to test models locally.
- environmental preparation::
- Make sure to install Python 3.8+ and PyTorch (GPU version recommended).
- Cloning Warehouse:
git clone https://github.com/kyutai-labs/delayed-streams-modeling.git cd delayed-streams-modeling - Install the dependencies:
pip install -r requirements.txt
- Run the STT model::
- Download pre-trained models such as
kyutai/stt-1b-en_fr(Hugging Face Warehouse) - Run the reasoning example:
python -m moshi_mlx.run_inference --hf-repo kyutai/stt-2.6b-en-mlx audio/sample.wav --temp 0 - The result will output transcribed text and a timestamp.
- Download pre-trained models such as
- Run the TTS model::
- Use a similar command to invoke the TTS model and input a text file to generate audio.
2. Rust (production environment)
Suitable for highly concurrent production environments with superior performance.
- environmental preparation::
- Install Rust (via
rustup). - clone (loanword)
moshiWarehouse:git clone https://github.com/kyutai-labs/moshi.git cd moshi - mounting
moshi-server::cargo install moshi-server
- Install Rust (via
- Configuration Server::
- Edit the configuration file (located in the
moshi/config), set the batch size (64 is recommended for L40S GPUs). - Start the server:
cargo run --release -- --config config.toml - The server provides streaming access via WebSocket and supports multi-user concurrency.
- Edit the configuration file (located in the
- Usage::
- Send audio streams via WebSocket client, receive transcribed text or generate speech.
3. MLX (Apple devices)
Suitable for running on iPhone or Mac, optimized for hardware acceleration.
- environmental preparation::
- Install the MLX framework (Apple's official machine learning framework).
- Clone the repository and install it
moshi-mlx::pip install moshi-mlx
- running inference::
- Microphone transcription in real time:
python -m moshi_mlx.run_inference --hf-repo kyutai/stt-1b-en_fr-mlx --mic - Document transcription:
python -m moshi_mlx.run_inference --hf-repo kyutai/stt-2.6b-en-mlx audio/sample.mp3 --temp 0 - The 1B model runs smoothly on the iPhone 16 Pro.
- Microphone transcription in real time:
Functional operation flow
Real-time speech-to-text (STT)
- Input Audio: Supports real-time microphone input or upload of audio files (e.g. WAV, MP3).
- Model Selection::
kyutai/stt-1b-en_fr: Suitable for English and French, low latency (0.5 seconds), with semantic VAD.kyutai/stt-2.6b-en: English-specific, 2.5-second delay, higher accuracy.
- Semantic VAD: Automatically detects whether the user has finished talking and dynamically adjusts the pause time to avoid misjudgment.
- output result: Returns transcribed text and word-level timestamps that can be used for word Subtitle generation or interaction control.
- Optimize LatencyUsing the "flush trick" technique, which accelerates processing when the end of speech is detected, latency is reduced from 500 ms to 125 ms.
Real-time text-to-speech (TTS)
- input text: Supports sentence-by-sentence or streaming input, suitable for real-time conversations.
- Generate Audio: The model generates natural speech in 220 milliseconds and supports long text (over 30 seconds).
- voice cloning: Input 10 seconds of reference audio to generate similar speech (additional configuration required, not fully open source).
- output format: Generate audio in WAV format for direct playback or saving.
Production environment deployment
- Rust server: Supporting high concurrency, the H100 GPU can handle up to 400 real-time audio streams.
- Batch optimization: Efficient batch processing without additional code through DSM architecture.
- WebSocket interface: The client sends audio or text via WebSocket and the server returns the result in real time.
caveat
- Model Selection: Select the appropriate model according to the hardware and requirements (1B parameter for lightweight devices, 2.6B parameter for high-precision scenarios).
- network requirement: Production environments require stable networks to support WebSocket streaming.
- documentation reference: see the GitHub repository for detailed configuration and API documentation
README.mdThe
application scenario
- Voice assistant development
- Scene Description: Developers use STT and TTS models to build intelligent voice assistants that support real-time dialog. Semantic VAD ensures accurate detection of user intent and is suitable for customer service robots or smart home devices.
- Real-time subtitle generation
- Scene Description: The STT model generates real-time captioning for videoconferencing or live streaming, with word-level timestamps for easy and precise alignment, for the education, conferencing, and media industries.
- voice translation
- Scene Description: Combine with Hibiki model to realize real-time speech translation, suitable for cross-language conference or travel scenarios, supporting streaming output of translation results.
- Voice Interaction for Mobile Devices
- Scene Description: MLX enables iPhone users to operate applications by voice, such as voice notes or real-time transcription, suitable for mobile offices and personal assistants.
QA
- How to choose the right model implementation?
- PyTorch for research and testing, Rust for high concurrency in production environments, and MLX for Apple devices. Refer to hardware and scenario selection.
- Is the voice cloning feature completely open source?
- At present, the voice cloning function is not fully open source, additional configuration is required, the official recommendation to refer to the Hugging Face documentation.
- How to optimize server performance?
- Adjust the batch size (e.g. 64) in the Rust server configuration file to ensure that the GPU memory is sufficient. the H100 GPU can support higher concurrency.
- What languages are supported?
- Mainly support English and French, experimental support for other languages, need to refer to the official documentation to test.
- What are the advantages of delayed stream modeling (DSM)?
- DSM reduces latency through time-aligned audio and text streams and supports efficient batch processing, outperforming traditional models such as Whisper.