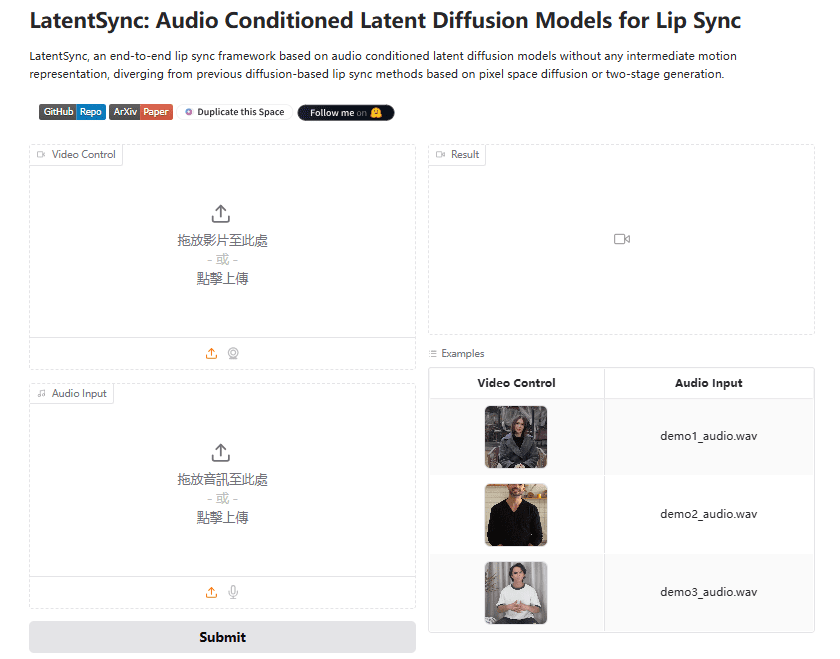
LatentSync is an open source tool developed by ByteDance and hosted on GitHub. It drives the lip movements of the characters in the video directly through the audio, so that the mouth shape matches the voice precisely. The project is based on Stable Diffusion's latent diffusio...

Twin AI is a simple and useful tool that helps users quickly turn photos or videos into personalized AI videos. It was developed by Alias Technologies for content creators, business users or anyone who wants to try their hand at AI video production. Users can upload photos to generate creative videos, or upload...

Instant Dream AI is a one-stop AI creation platform designed to provide users with versatile and powerful creation tools. Whether it's image generation, smart canvas, video generation or music generation, Instant Dream AI can help users easily realize their creativity. The platform supports a variety of creation modes, including AI drawing, AI video, AI sound...
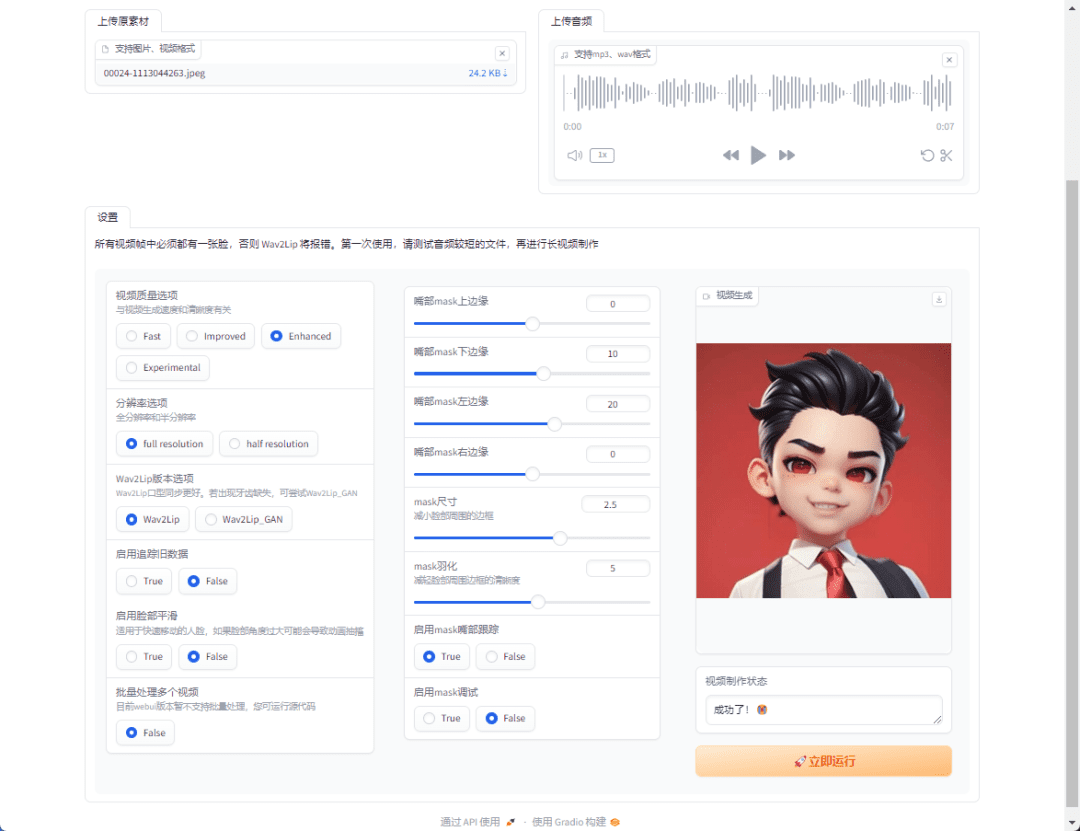
Easy-Wav2Lip is an improved tool based on Wav2Lip designed to simplify the process of video lip synchronization. The tool offers simpler setup and implementation, supports Google Colab and local installation. By optimizing the algorithm, Easy-Wav2Lip significantly improves the processing speed and fixes...

Lipdub is an innovative AI video translation app designed to help users translate and lip sync video content into multiple languages. With Lipdub, users can easily record videos and translate them into 27 different languages in real time. The app utilizes advanced technology to make the translated video...
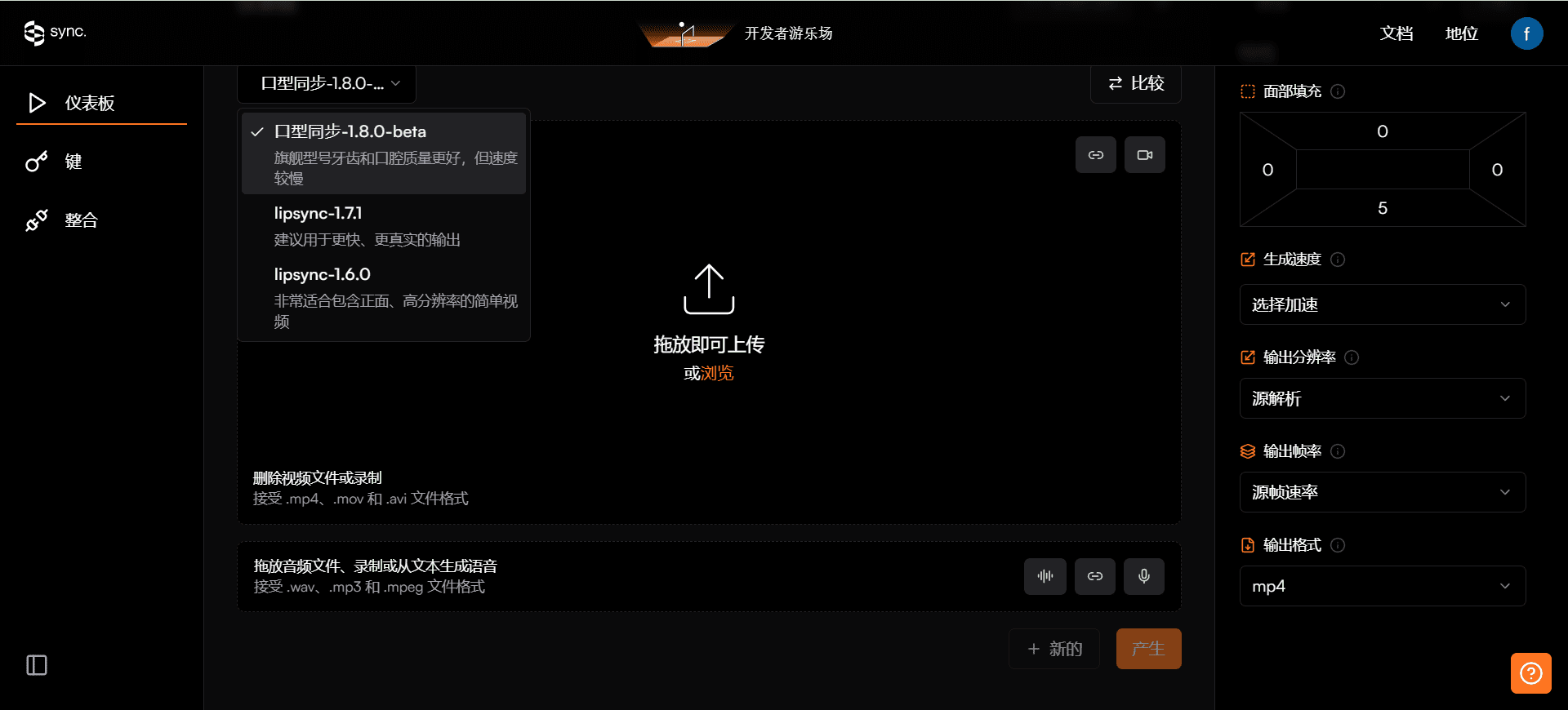
General Introduction Sync is an efficient AI video lip sync tool (closed source Wav2Lip) by Synchronicity Labs, designed to accurately synchronize any audio with the lip sync in the video, ensuring that the character's lip sync in the video is perfectly synchronized with the voice. Designed for content creators, podcasters and faceless YouTube frequency...

SadTalker is an open source tool that combines a single still portrait photo with an audio file to create realistic talking avatar videos for a wide range of scenarios such as personalized messages, educational content, and more. Revolutionary use of 3D modeling technologies such as ExpNet and PoseVAE excel in capturing subtle facial expressions and...
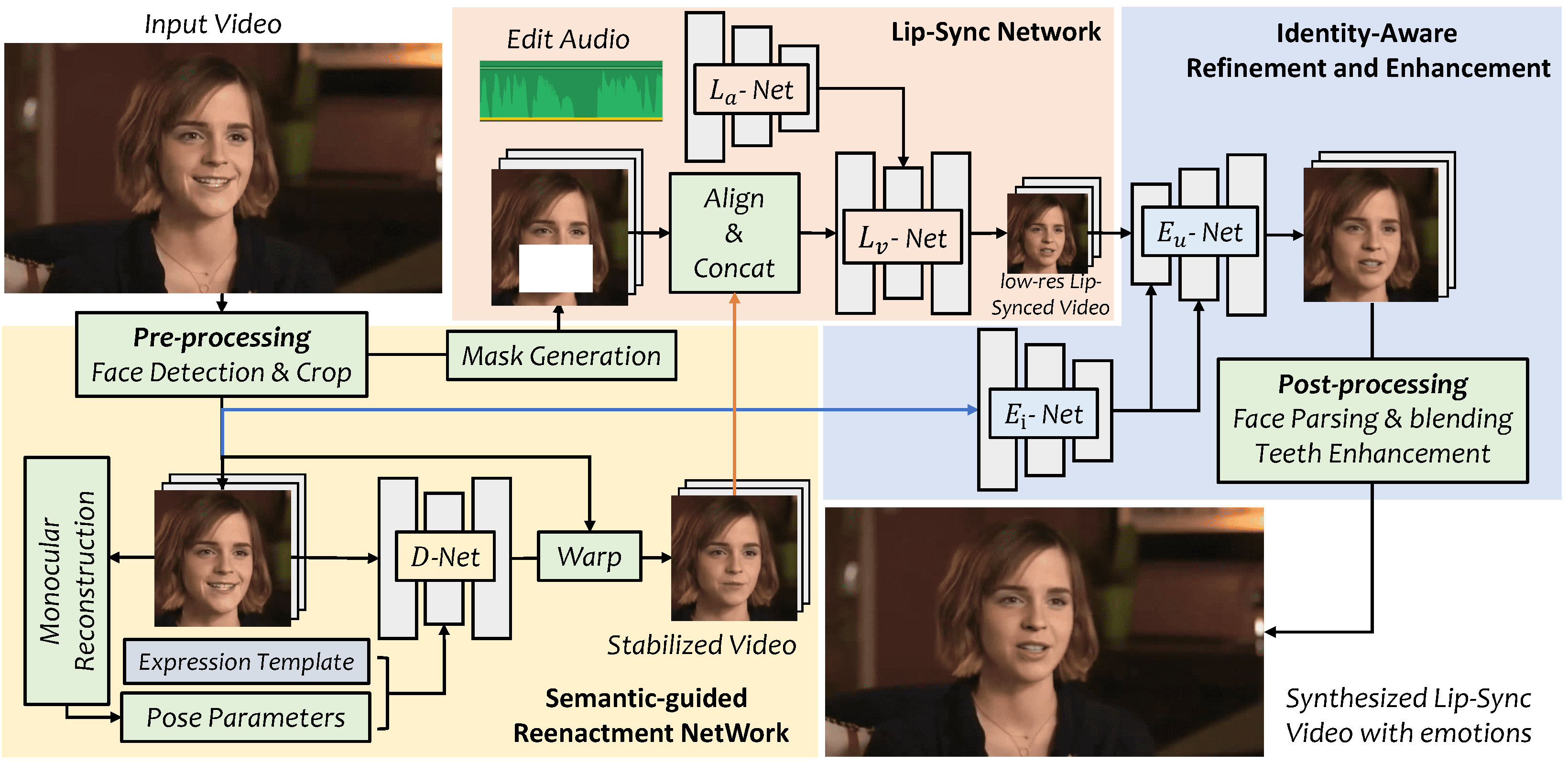
VideoReTalking is an innovative system that allows users to generate lip-synchronized facial videos based on input audio, producing high-quality and lip-synchronized output videos even with different emotions. The system breaks down this goal into three successive tasks: facial video generation with typical expressions, audio...

MuseV is a public project on GitHub that aims to enable the generation of avatar videos of unlimited length and high fidelity. It is based on diffusion technology and offers Image2Video, Text2Image2Video, Video2Video and many other features. A model structure, use cases, quick start guide are provided...
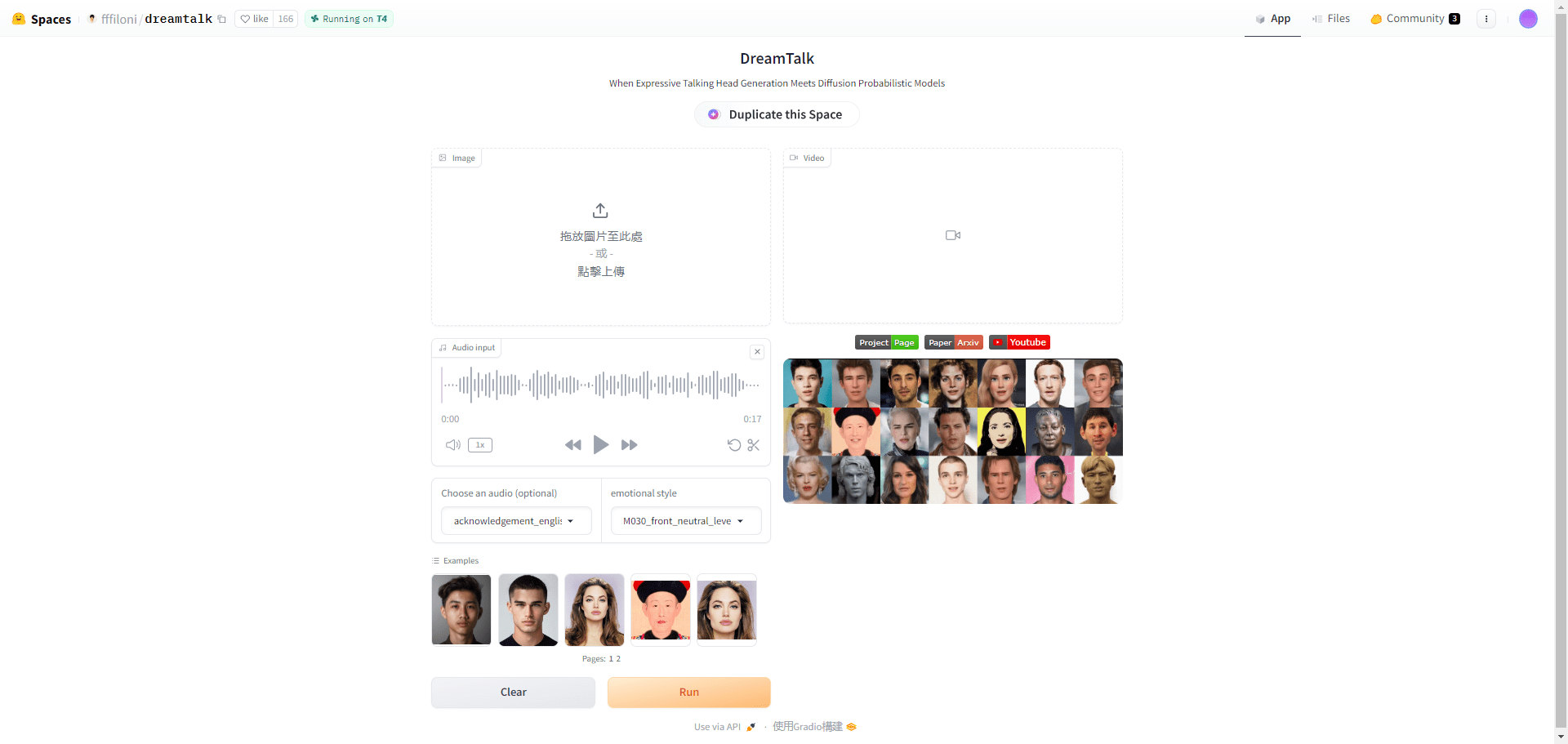
DreamTalk Comprehensive Introduction DreamTalk is a diffusion model-driven expression talking head generation framework, jointly developed by Tsinghua University, Alibaba Group and Huazhong University of Science and Technology. It is mainly composed of three parts: a noise reduction network, a style-aware lip expert and a style predictor, and is able to generate a variety of audio input based on...
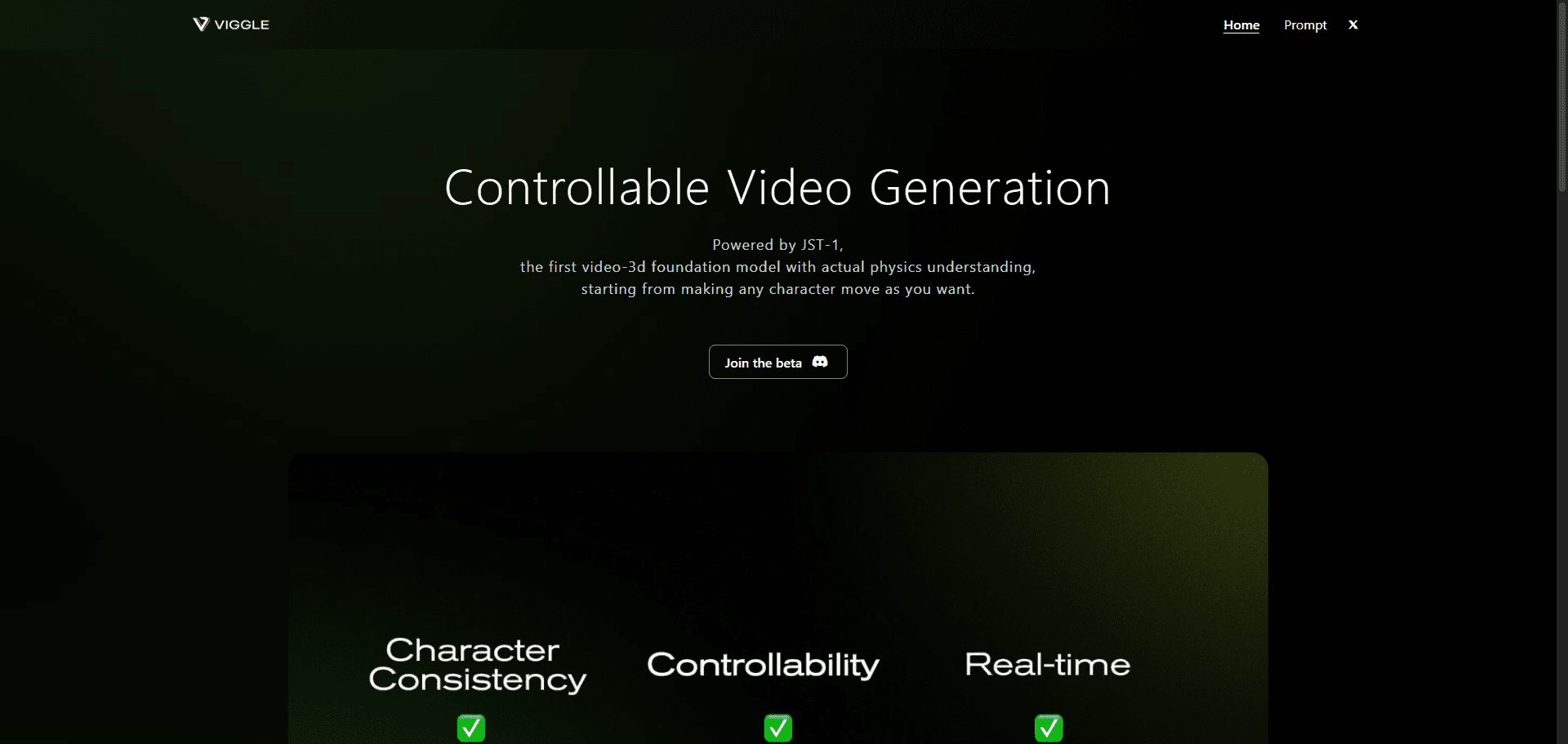
Viggle is a JST-1 model-driven video generation service platform focused on character video generation. Users are able to control the movement of any character with text prompts, mix still characters with action videos, or create videos entirely out of text. Currently, Viggle is in beta and has creators...

General Introduction Wav2Lip is an open source high-precision lip sync generation tool designed to accurately synchronize arbitrary audio with lip sync in video. The tool, released by Rudrabha Mukhopadhyay et al. at ACM Multimedia 2020, utilizes advanced AI techniques to be able to...

