The development of multimodal large models is entering a new stage, moving from simple image recognition ("seeing") to complex logical reasoning and deep understanding ("seeing and thinking"). Recently, Smart Spectrum AI released and open-sourced the GLM-4.1V-Thinking in the series GLM-4.1V-9B-Thinking modeling, demonstrating new advances in its higher-order cognitive capabilities for visual language modeling.
The central innovation of the model is the introduction of a method called Reinforcement Learning with Curriculum Sampling (RLCS, Reinforcement Learning with Curriculum Sampling) The training strategy. This approach trains the model by scheduling tasks from easy to difficult, similar to the human learning process, resulting in significant progress on complex reasoning tasks.
What is most striking is its performance performance. Despite the GLM-4.1V-9B-Thinking With only 9 billion parameters, it matches or even exceeds the 72 billion parameter count in 18 authoritative benchmarks. Qwen2.5-VL-72BThis result challenges the traditional notion that "bigger models are more powerful". This result challenges the traditional notion that "the bigger the model, the more powerful it is", and highlights the great potential of advanced model architectures and efficient training strategies to improve performance and save resources.

Links to related resources:
- Dissertation. GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
- Open source code repository.
- Online Experience.
- API Documentation. Big Model Open Platform
Demonstration of model core competencies and applications
GLM-4.1V-9B-Thinking By introducing the Chain-of-Thought mechanism, it is possible to show the detailed reasoning process while outputting the answer. This not only improves the accuracy and richness of the answers, but also enhances the interpretability of the results. The model integrates extensive multimodal processing capabilities through hybrid training.
- Video and Image Understanding. The ability to parse up to two hours of video or conduct in-depth Q&A on complex image content demonstrates strong logical analysis.
- Interdisciplinary Problem Solving. Support for math, physics, biology, chemistry and other subjects to look at the map to solve the problem, and can give detailed steps to think.
- High-precision information extraction. Accurately recognizes and structures the output of text and graphical information in pictures and videos.
- Documentation and Interface Interaction. It can natively understand the content of documents in finance, government, and other fields, and can recognize GUI elements, execute commands such as click and slide, and act as a "GUI intelligent body".
- Visualization to Code Generation. Ability to automatically write front-end code based on screenshots of the interface entered.
Below are a few examples of typical applications:
Example 1: Graphical Analysis and Reasoning
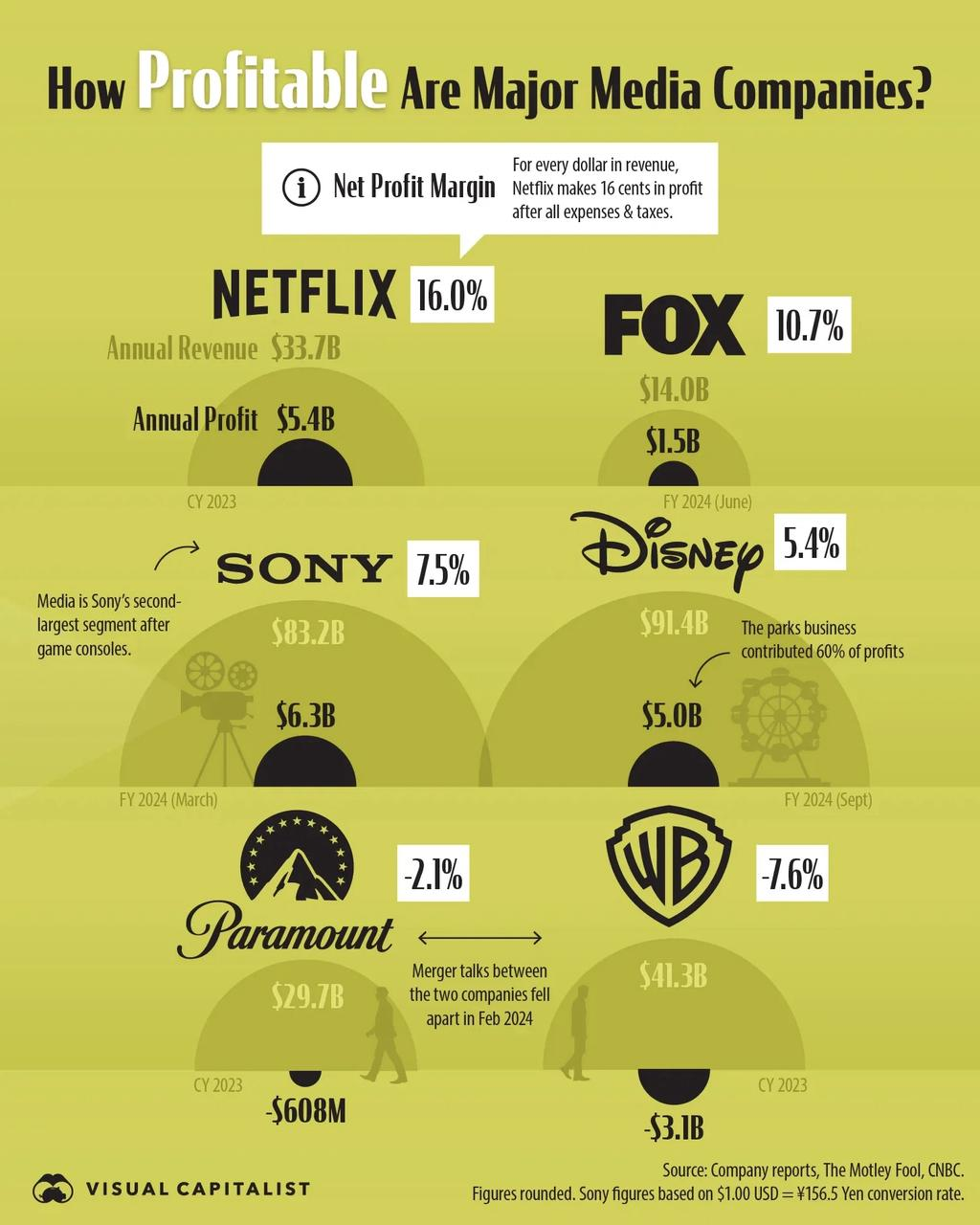
Input command.
Identify the company with the highest annual profit in this graph, and the largest division of that company?
Model output.
Sony has the highest annual profit at $6.3B. For Sony, the note states, "Media is Sony's second-largest segment after game consoles." Thus, the largest segment is game consoles. Thus, the largest segment is game consoles.
Example 2: Solving Higher Level Math Questions

Input command.
Please help me with this topic by giving detailed process and answer.
Model outputs (partial reasoning process).
- It is known that PA ⊥ the plane ABCD , so PA ⊥ AD and PA ⊥ AB.
- Since AB ⊥ AD and the intersection of PA and AB is A, AD ⊥ plane PAB.
- Since AD ⊂ plane PAD, plane PAB ⊥ plane PAD.
Example 3: Graphical User Interface (GUI) Identification and Operation

Input command.
In the APP, help me create a meeting with Dr. Smith in two weeks at 3.
Model Outputs (Operational Instructions).
Action: {"action_type": "click", "box_2d": [[27,840,122,885]]}
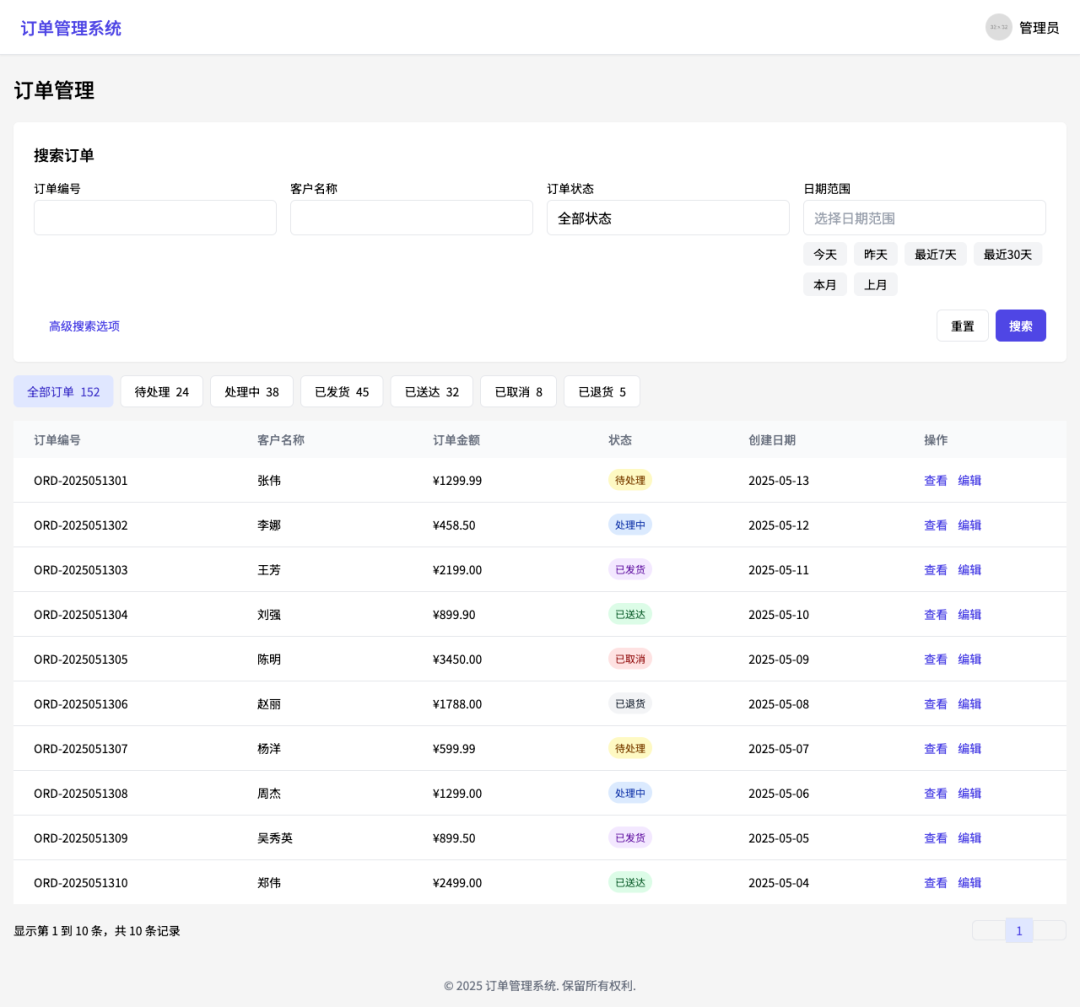
Example 4: According to the picture to generate the front-end web page code
This feature demonstrates the model's powerful ability to translate visual designs directly into usable code, greatly enhancing front-end development efficiency.
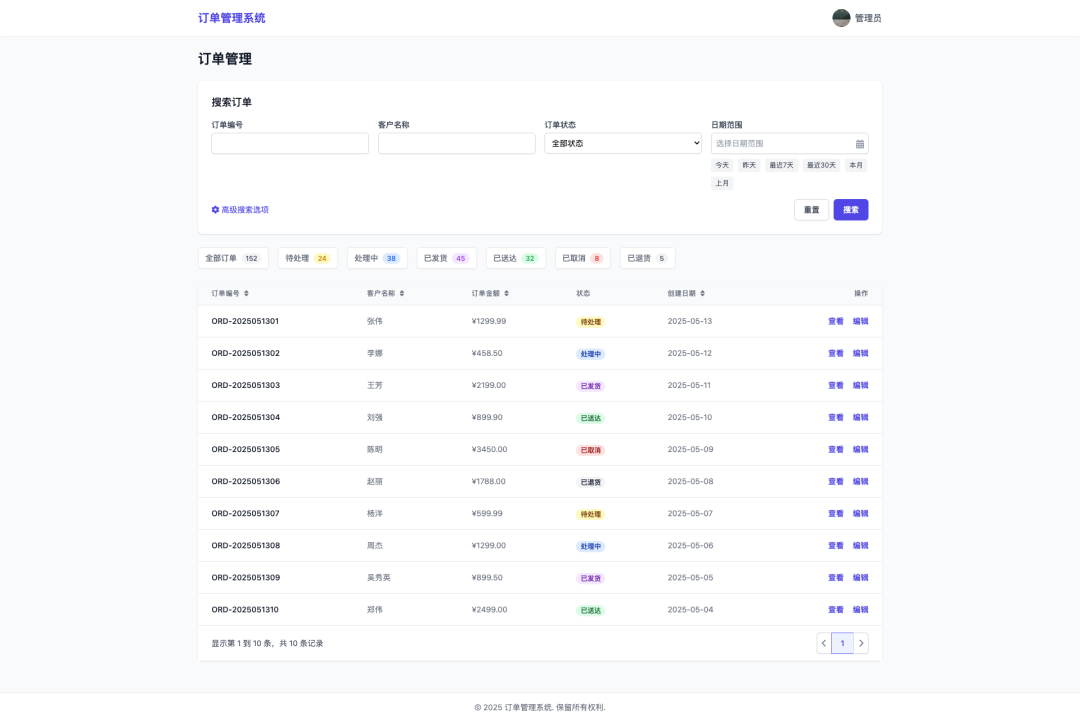
Input command.
Please build a web page similar to the input image and convert it to React code.
Model-generated React code.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>订单管理系统</title>
<script src="https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/react-dom@18.0.0/umd/react-dom.development.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@babel/standalone/babel.js"></script>
<script src="https://cdn.tailwindcss.com"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"></link>
<link href="https://fonts.geekzu.org/css2?family=Noto+Sans+SC:wght@400;500;700&display=swap" rel="stylesheet">
<style>
body {
font-family: 'Noto Sans SC', sans-serif;
background-color: #f5f5f5;
}
</style>
</head>
<body>
<div id="root"></div>
<script type="text/babel">
const Header = () => {
return (
<header className="bg-white shadow-sm py-4 px-6 flex justify-between items-center border-b">
<h1 className="text-xl font-medium text-indigo-600">订单管理系统</h1>
<div className="flex items-center">
<img src="https://placehold.co/32x32" alt="管理员头像" className="w-8 h-8 rounded-full mr-2" />
<span>管理员</span>
</div>
</header>
);
};
const SearchForm = () => {
return (
<div className="bg-white rounded-md shadow-sm p-6 mb-4">
<h2 className="text-lg font-medium mb-4">搜索订单</h2>
<div className="grid grid-cols-1 md:grid-cols-4 gap-4">
<div>
<label className="block text-sm mb-1">订单编号</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">客户名称</label>
<input type="text" className="w-full border rounded-md px-3 py-2" />
</div>
<div>
<label className="block text-sm mb-1">订单状态</label>
<select className="w-full border rounded-md px-3 py-2 appearance-none bg-white">
<option>全部状态</option>
</select>
</div>
<div>
<label className="block text-sm mb-1">日期范围</label>
<div className="relative">
<input type="text" placeholder="选择日期范围" className="w-full border rounded-md px-3 py-2" />
<div className="absolute right-2 top-2 text-gray-400">
<i className="fas fa-calendar"></i>
</div>
</div>
<div className="flex flex-wrap mt-2 gap-2">
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">今天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">昨天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近7天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">最近30天</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">本月</button>
<button className="px-3 py-1 text-sm rounded-md bg-gray-100">上月</button>
</div>
</div>
</div>
<div className="flex items-center justify-between mt-4">
<a href="#" className="text-indigo-600 flex items-center text-sm">
<i className="fas fa-cog mr-1"></i> 高级搜索选项
</a>
<div className="flex gap-2">
<button className="px-4 py-2 border rounded-md text-sm">重置</button>
<button className="px-4 py-2 bg-indigo-600 text-white rounded-md text-sm">搜索</button>
</div>
</div>
</div>
);
};
const OrderStatusFilters = () => {
const filters = [
{ name: "全部订单", count: 152, active: true },
{ name: "待处理", count: 24, active: false },
{ name: "处理中", count: 38, active: false },
{ name: "已发货", count: 45, active: false },
{ name: "已送达", count: 32, active: false },
{ name: "已取消", count: 8, active: false },
{ name: "已退货", count: 5, active: false },
];
return (
<div className="flex flex-wrap gap-2 mb-4">
{filters.map((filter, index) => (
<button
key={index}
className={`px-4 py-2 rounded-md text-sm ${
filter.active
? "bg-indigo-100 text-indigo-700"
: "bg-white border"
}`}
>
{filter.name} {filter.count > 0 && <span className="ml-1">{filter.count}</span>}
</button>
))}
</div>
);
};
const OrderTable = () => {
const orders = [
{ id: "ORD-2025051301", customer: "张伟", amount: "¥1299.99", status: "待处理", date: "2025-05-13" },
{ id: "ORD-2025051302", customer: "李娜", amount: "¥458.50", status: "处理中", date: "2025-05-12" },
{ id: "ORD-2025051303", customer: "王芳", amount: "¥2199.00", status: "已发货", date: "2025-05-11" },
{ id: "ORD-2025051304", customer: "刘强", amount: "¥899.90", status: "已送达", date: "2025-05-10" },
{ id: "ORD-2025051305", customer: "陈明", amount: "¥3450.00", status: "已取消", date: "2025-05-09" },
{ id: "ORD-2025051306", customer: "赵丽", amount: "¥1788.00", status: "已退货", date: "2025-05-08" },
{ id: "ORD-2025051307", customer: "杨洋", amount: "¥599.99", status: "待处理", date: "2025-05-07" },
{ id: "ORD-2025051308", customer: "周杰", amount: "¥1299.00", status: "处理中", date: "2025-05-06" },
{ id: "ORD-2025051309", customer: "吴秀英", amount: "¥899.50", status: "已发货", date: "2025-05-05" },
{ id: "ORD-2025051310", customer: "郑伟", amount: "¥2499.00", status: "已送达", date: "2025-05-04" },
];
const getStatusClass = (status) => {
switch(status) {
case "待处理": return "bg-yellow-100 text-yellow-800";
case "处理中": return "bg-blue-100 text-blue-800";
case "已发货": return "bg-purple-100 text-purple-800";
case "已送达": return "bg-green-100 text-green-800";
case "已取消": return "bg-red-100 text-red-800";
case "已退货": return "bg-gray-100 text-gray-800";
default: return "bg-gray-100 text-gray-800";
}
};
return (
<div className="overflow-x-auto">
<table className="min-w-full bg-white">
<thead>
<tr className="bg-gray-50 text-left text-sm">
<th className="px-6 py-3 font-medium text-gray-500">订单编号 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">客户名称 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">订单金额 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">状态 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">创建日期 <i className="fas fa-sort ml-1"></i></th>
<th className="px-6 py-3 font-medium text-gray-500">操作</th>
</tr>
</thead>
<tbody className="divide-y divide-gray-200">
{orders.map((order, index) => (
<tr key={index} className="hover:bg-gray-50">
<td className="px-6 py-4 text-sm">{order.id}</td>
<td className="px-6 py-4 text-sm">{order.customer}</td>
<td className="px-6 py-4 text-sm">{order.amount}</td>
<td className="px-6 py-4">
<span className={`px-2 py-1 rounded-full text-xs ${getStatusClass(order.status)}`}>
{order.status}
</span>
</td>
<td className="px-6 py-4 text-sm">{order.date}</td>
<td className="px-6 py-4 text-sm">
<button className="text-indigo-600 mr-3">查看</button>
<button className="text-indigo-600">编辑</button>
</td>
</tr>
))}
</tbody>
</table>
</div>
);
};
const Pagination = () => {
return (
<div className="flex items-center justify-between mt-4 text-sm">
<div>显示第 1 到 10 条,共 10 条记录</div>
<div className="flex items-center">
<button className="px-3 py-1 border rounded-l-md">
<i className="fas fa-chevron-left"></i>
</button>
<button className="px-3 py-1 border-t border-b bg-indigo-100 text-indigo-600">1</button>
<button className="px-3 py-1 border rounded-r-md">
<i className="fas fa-chevron-right"></i>
</button>
</div>
</div>
);
};
const Footer = () => {
return (
<footer className="py-4 text-center text-gray-500 text-sm">
© 2025 订单管理系统. 保留所有权利.
</footer>
);
};
const App = () => {
return (
<div className="min-h-screen flex flex-col">
<Header />
<main className="flex-1 max-w-7xl mx-auto w-full px-4 py-6">
<h1 className="text-2xl font-medium mb-6">订单管理</h1>
<SearchForm />
<OrderStatusFilters />
<OrderTable />
<Pagination />
</main>
<Footer />
</div>
);
};
ReactDOM.render(<App />, document.getElementById('root'));
</script>
</body>
</html>
Example 5: Principle Analysis of a Physical Phenomenon
Input command.
What is the reason for this phenomenon to occur? Why is there water in the center water glass?
Model output.
This phenomenon is due to the **capillary phenomenon (or capillary action)**. Specifically: Tissue paper is a porous material and the gaps between its fibers are similar to "capillaries". When the left and right cups containing different colored liquids are connected to the empty cup in the middle with a paper towel, the paper towel will make use of its own water absorption and capillary action between the fibers to transport the red liquid on the left and the blue liquid on the right through the fiber gaps to the empty cup in the middle. As this transportation process proceeds, the empty cup in the middle is gradually filled with liquid, resulting in the phenomenon of "water in the middle cup".
Technical architecture and training methodology
GLM-4.1V-Thinking The efficient performance stems from its refined model architecture and staged training process.
model architecture
The model architecture consists of three parts: a visual encoder (ViT Encoder), an adapter (MLP Projector) and a language decoder.
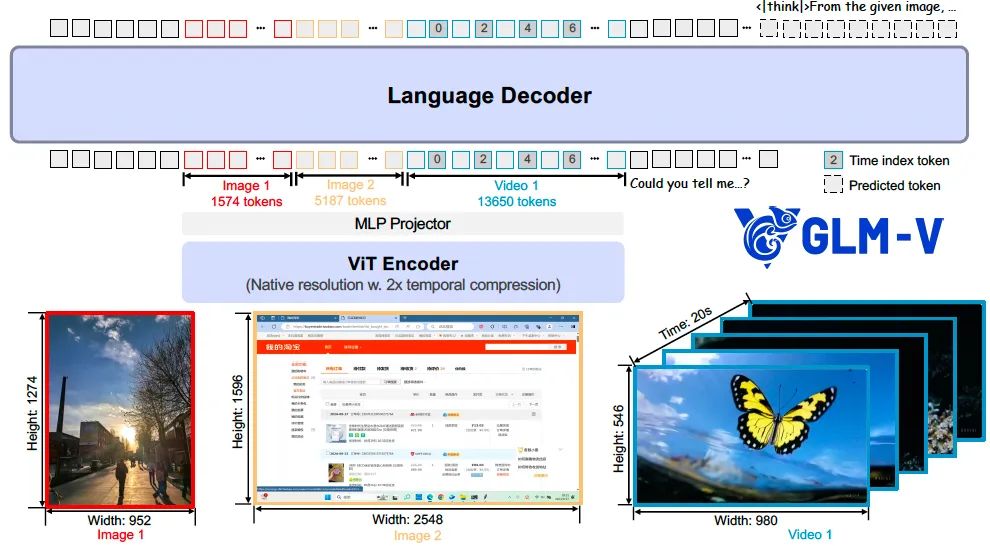
The model was chosen AIMv2-Huge as a visual coder, and the 2D convolution therein is extended in 3D to efficiently handle the temporal dimension of the video input. In order to enhance the adaptability to images of arbitrary resolution and aspect ratio, two key improvements are introduced to the model:
- Two-dimensional rotational position encoding (2D-RoPE). This technology helps the model better understand the spatial relationships within an image, enabling it to stabilize extreme aspect ratios in excess of 200:1 and high resolution images above 4K.
- Dynamic Resolution Adaptation. By preserving the absolute positional embedding of the ViT pre-trained model and combining it with the bicubic interpolation method, the model can be dynamically adapted to inputs of different resolutions during training.
In the language decoder section, the model extends the original rotational position encoding (RoPE) to Three-dimensional rotational position encoding (3D-RoPE), which significantly enhances the model's spatial comprehension when processing mixed graphic-video inputs without affecting its plain text processing performance.
Training process
The training of the model is divided into three stages: pre-training, supervised fine-tuning (SFT) and reinforcement learning (RL).
- Pre-training phase. It is divided into two sub-phases: generalized multimodal pre-training and long context continuous training. The former aims to establish a basic multimodal understanding; the latter extends the model's processing sequence length to 32,768 by introducing video frame sequences and very long graphic content to enhance the processing capability for high-resolution and long videos.
- Supervised Fine Tuning (SFT) Phase. In this phase, the model is fully parametrically fine-tuned using a high-quality Chain of Thought (CoT) dataset. All training samples are in a uniform format, forcing the model to learn to generate detailed reasoning processes instead of giving direct answers.
<think> {推理过程} </think> <answer> {最终答案} </answer>This step effectively strengthens the model's ability to reason causally over long periods of time.
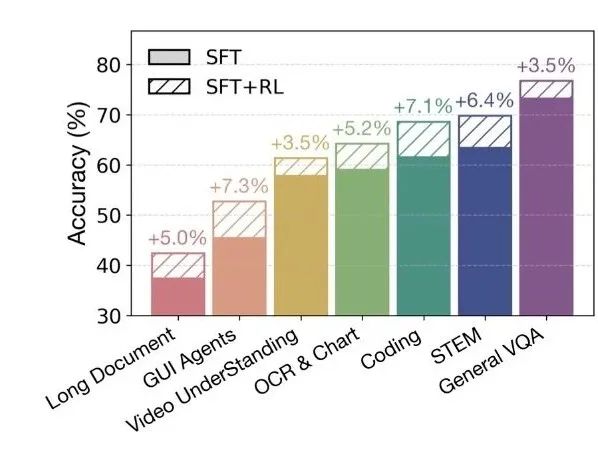
- Course Sampling Intensive Learning (RLCS) Phase. This is the key to improving the performance of the model. Based on the supervised fine-tuned model, the development team combined Reinforcement Learning based on Verifiable Rewards (RLVR) and Reinforcement Learning based on Human Feedback (RLHF). Through a "course sampling" mechanism, the model starts learning from simple tasks in multiple dimensions, such as STEM problem solving, GUI interaction, and document understanding, and gradually transitions to complex tasks. This dynamic learning paradigm from easy to difficult optimizes the model's performance in terms of utility, accuracy and stability.