
MiniMax Audio is an AI speech generation tool from MiniMax, with the core feature of quickly converting text into highly similar natural speech. It is based on the Speech-02 model, with a speech synthesis similarity of up to 99%, studio-grade sound quality, and support for more than 30 languages and a wide range of mouth...

MegaTTS3 is an open source speech synthesis tool developed by ByteDance in cooperation with Zhejiang University, focusing on generating high-quality Chinese and English speech. Its core model is only 0.45B parameters , lightweight and efficient , support for mixed Chinese and English speech generation and speech cloning . The project is hosted on GitHub, providing code and...

Seed-VC is an open source project on GitHub, developed by Plachtaa. It can use a piece of reference audio from 1 to 30 seconds to quickly realize the voice or song conversion, without additional training. The project supports real-time voice conversion with a latency as low as 400 milliseconds , suitable for online meetings , games ...

CSM Voice Cloning is an open source project developed by Isaiah Bjork and hosted on GitHub. It is based on the Sesame CSM-1B model, which allows users to clone their own voice and generate a voice with their own personal characteristics by simply providing an audio sample. This tool supports this ...

PlayHT is an efficient online platform focusing on AI speech generation, helping users quickly convert text into natural, realistic speech. It provides more than 600 AI voices, supports more than 60 languages and diverse accents, and is suitable for a variety of scenarios such as podcast production, educational content, marketing and promotion. Users only need to input...

Spark-TTS is an open source Text-to-Speech (TTS) tool developed by the SparkAudio team, hosted on GitHub, designed to help users efficiently convert text into natural and smooth speech. It is based on advanced deep learning technology and supports multiple languages and voice styles...

Step-Audio is an open source intelligent speech interaction framework designed to provide out-of-the-box speech understanding and generation capabilities for production environments. The framework supports multi-language dialog (e.g., Chinese, English, Japanese), emotional speech (e.g., happy, sad), regional dialects (e.g., Cantonese, Szechuan), adjustable speech rate...

Zonos is an open source speech synthesis and speech cloning tool developed by Zyphra.The Zonos-v0.1 version employs an advanced Transformer and blending model to generate high-quality speech output. The tool supports multiple languages, including English, Japanese, Chinese, French and German, and provides fine...
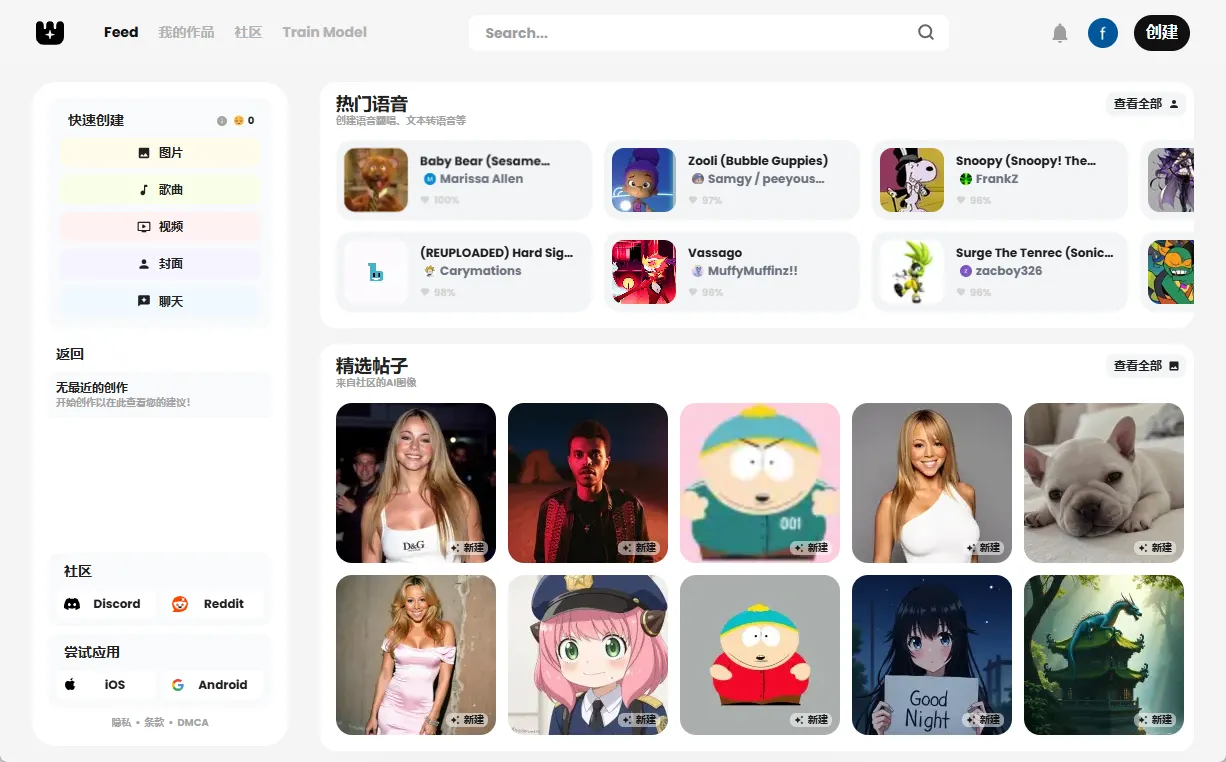
Weights is a social platform that utilizes AI for creation, allowing users to create voice covers, text-to-speech, images, music, and videos with simple actions. The platform provides a wealth of tools and templates to help users get started quickly and share their work with the community.Weights ...

AnyVoice is an advanced AI speech generation platform that provides ultra-realistic speech generation and voice cloning services. The platform allows users to convert text into natural speech and choose from hundreds of preset voices. If you can't find the right voice, just 3 seconds of recording can be free gr...

Llasa-3B is an open source text-to-speech (TTS) model developed by the Audio Lab of the Hong Kong University of Science and Technology (HKUST Audio). The model is based on the Llama 3.2B architecture, which has been carefully tuned to provide high-quality speech generation that not only supports multiple languages, but also enables emotional expression and personalized speech g...

Fish Speech Derivative Project Fish Agent is a revolutionary end-to-end AI speech cloning system developed based on V0.1 3B model architecture. As a fully end-to-end speech cloning processing system, its most important feature is that it adopts an innovative semantic tagless architecture design, which does not need to rely on the traditional language such as Whisper .....
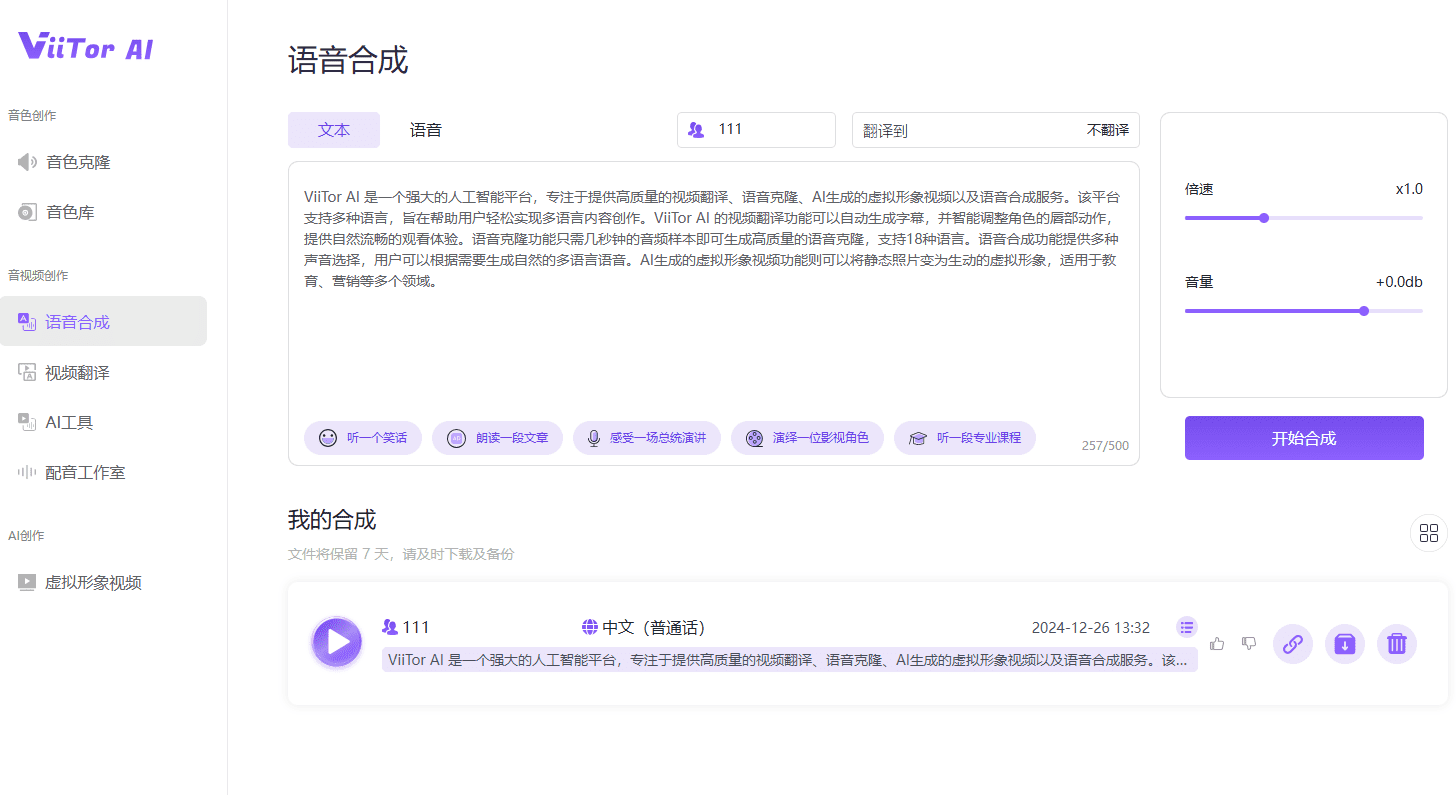
ViiTor AI is a powerful artificial intelligence platform focused on providing high-quality video translation, voice cloning, AI-generated avatar videos, and speech synthesis services. The platform supports multiple languages and is designed to help users easily realize multilingual content creation.ViiTor AI's video translation feature can...
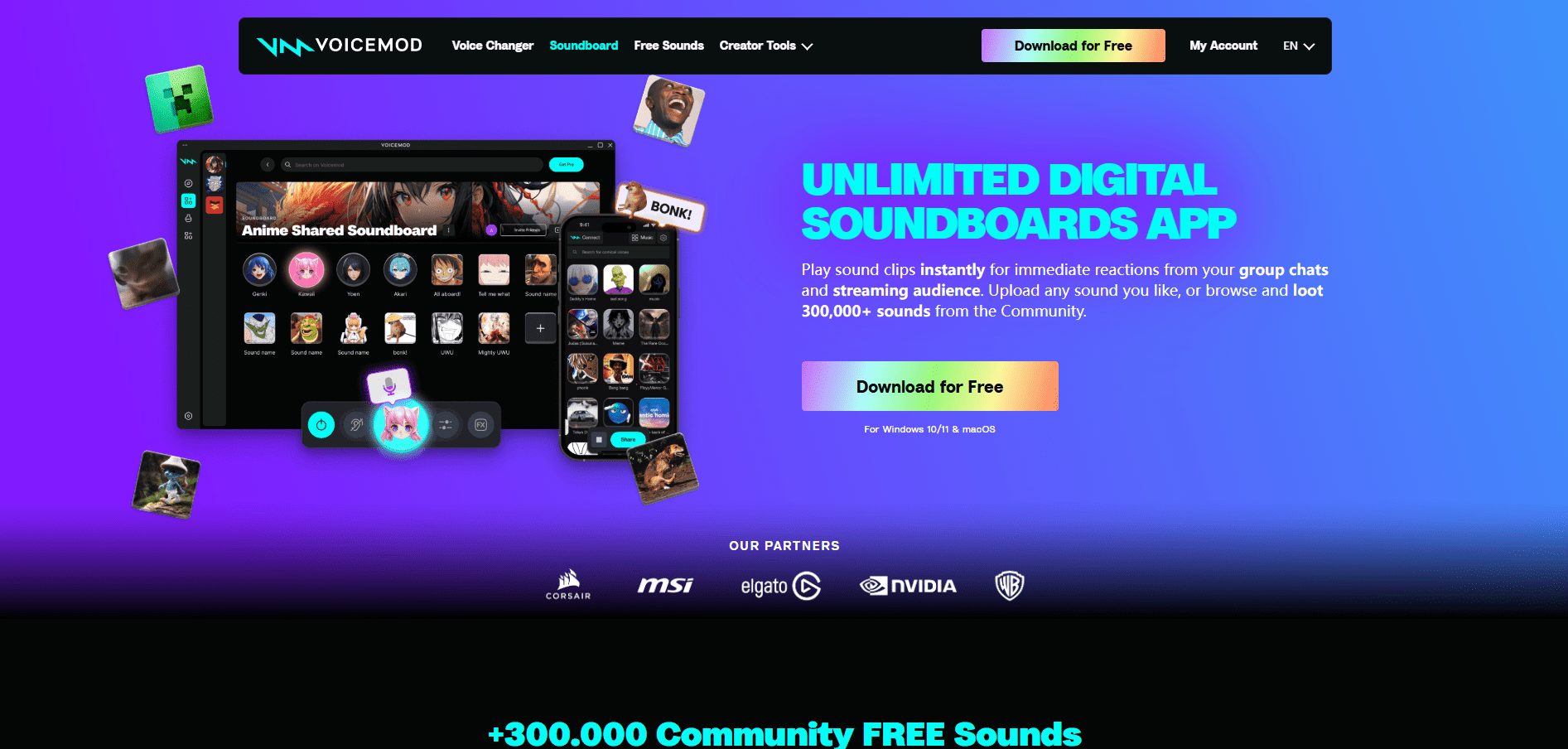
Voicemod is a leading real-time voice changer and sound effects software for Windows and macOS. Whether you are role-playing in a game, chatting with friends, or live-streaming, Voicemod provides you with a rich variety of voice changing effects. With AI technology, Voicemod is able to real-time...
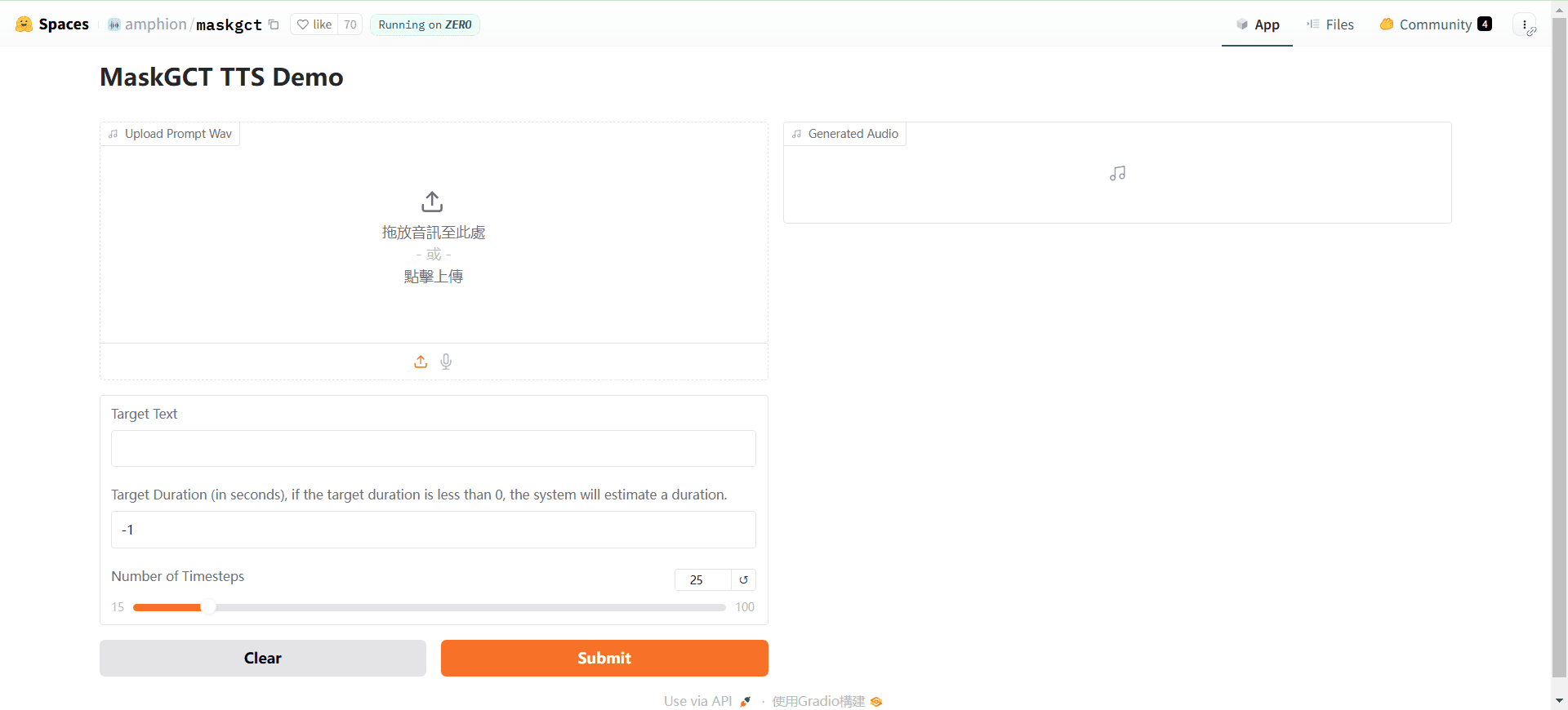
MaskGCT (Masked Generative Codec Transformer) is a completely non-autoregressive Text-to-Speech (TTS) model jointly introduced by Funky Maru Technology and The Chinese University of Hong Kong. The model does not require explicit text-to-speech alignment information, and adopts a two-stage generation approach, first through text pre...

Funmaru Thousand Voices is a multilingual AI voice synthesis platform that provides realistic and natural voice generation solutions. Users can easily convert text content into professional-grade audio and support the creation of exclusive AI voices (voice clones) from zero samples to meet personalized needs. The platform also provides video translation function to help users realize...
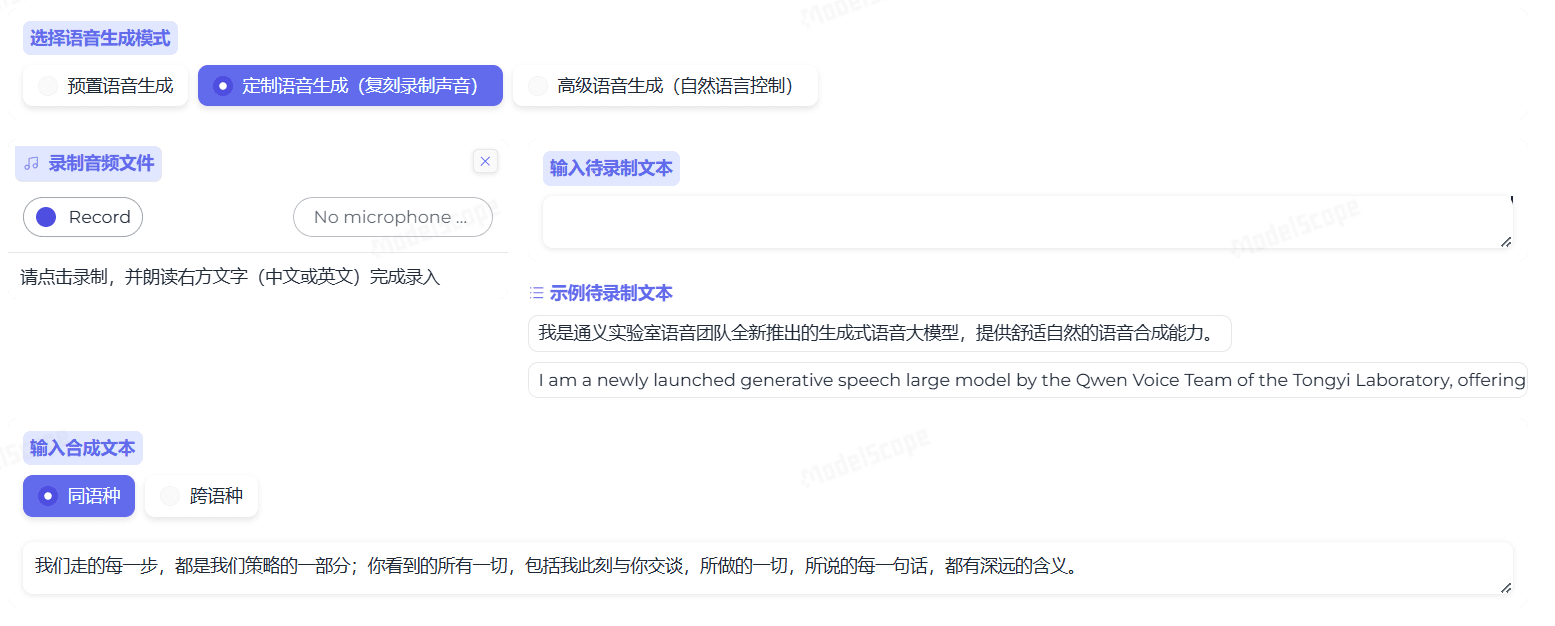
CosyVoice is a multilingual large-scale speech generation model that provides full-stack capabilities from inference, training to deployment. Developed by FunAudioLLM team, it aims to achieve high quality speech synthesis through advanced autoregressive transformers and ODE-based diffusion models.CosyVoice not only supports multilingual...
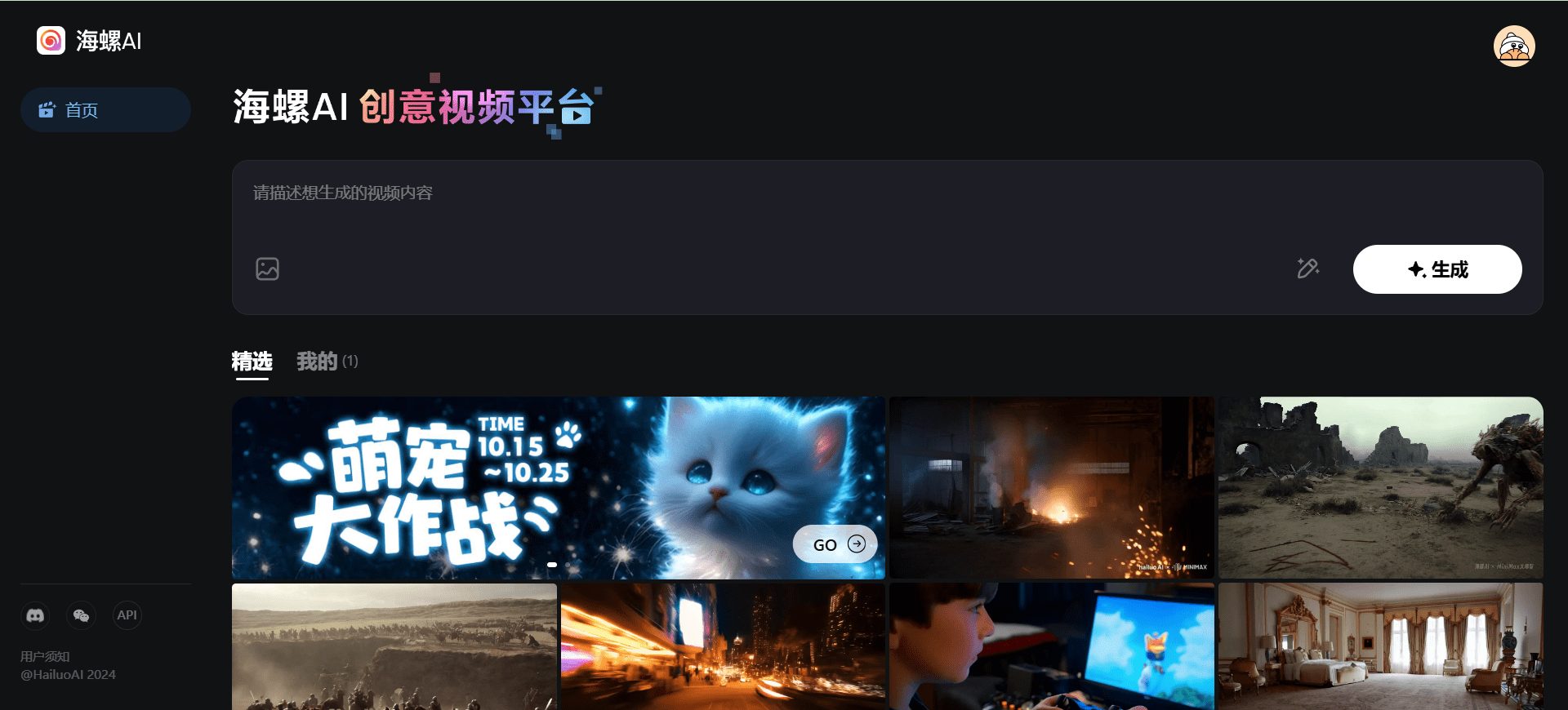
Conch AI Video Generator is an advanced AI video generation tool developed by MiniMax. Users only need to provide a simple text description or upload images, and Conch AI can quickly generate high-quality video content. The tool is widely used by creators, marketers and storytellers to help them bring...
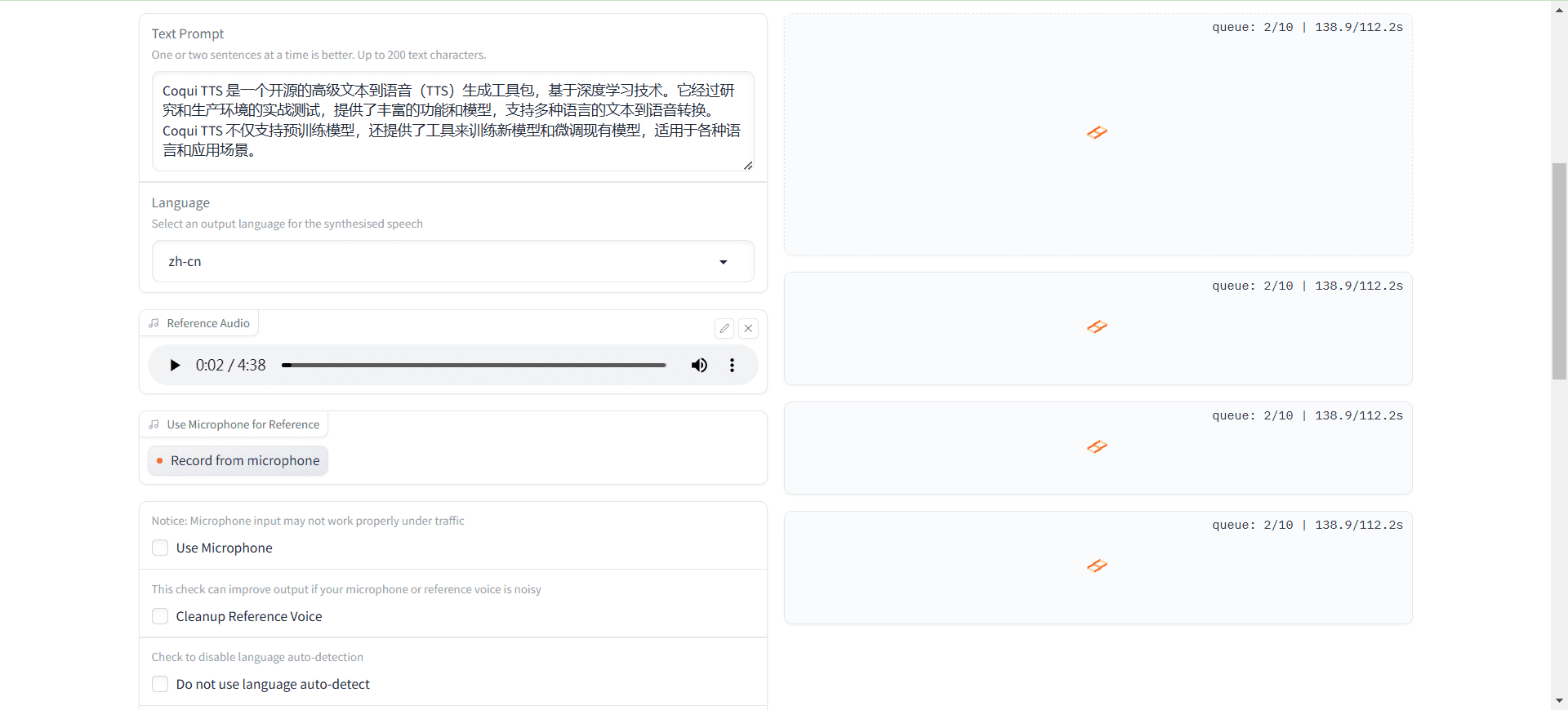
Comprehensive Introduction Coqui TTS is an open source advanced text-to-speech (TTS) generation toolkit based on deep learning techniques. It has been battle-tested in both research and production environments, and provides a rich set of features and models that support text-to-speech conversion in multiple languages.Coqui TTS not only supports pre-trained models...

