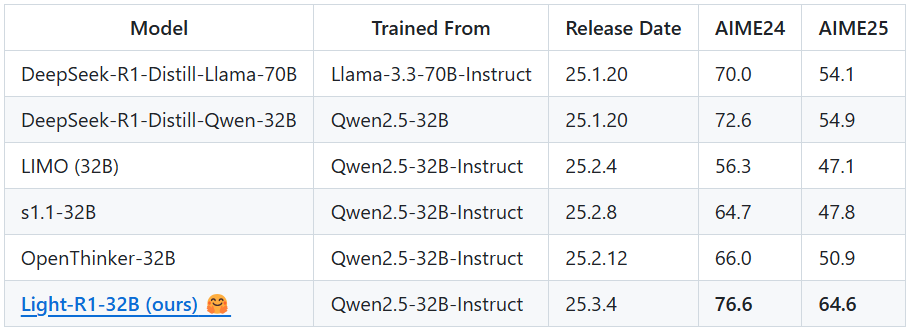
DeepSeek-TNG-R1T2-Chimera 是由 TNG Technology Consulting GmbH 开发的一款开源大型语言模型,托管在 Hugging Face 平台上。该模型于 2025 年 7 月 2 日发布,是 DeepSeek-R1T-Chimera 的升级版,融合了 R1、V3-0324 和 R1-0528 三个母模型,通过 Assembly of Experts(AoE)方法进行精细化构建。R1T2 在速度和智能性上找到平衡点,相比 R1 快约 20%,比 R1-0528 快两倍以上,同时在 GPQA 和 AIME-24/25 等基准测试中表现出更高的智能性。它修复了前代模型的 标记一致性问题,适合需要高效推理和快速响应的场景。模型采用 MIT 许可证,开放权重,供开发者免费使用。

功能列表
- 高效文本生成:快速生成流畅、准确的文本,适合对话、内容创作等任务。
- 高级推理能力:支持复杂问题分析和逻辑推理,适用于学术研究和技术文档处理。
- 多语言支持:处理多种语言输入,适合国际化应用场景。
- 优化 token 效率:相比 R1-0528,输出 token 更少,降低计算成本。
- 修复 标记问题:确保推理过程中的一致性,提升模型可靠性。
- 开源模型权重:基于 MIT 许可证,允许用户自由下载、修改和部署。
使用帮助
安装流程
DeepSeek-TNG-R1T2-Chimera 是一个托管在 Hugging Face 的模型,需通过 Python 环境结合 Hugging Face 的 Transformers 库使用。以下是详细安装和使用步骤:
1. 安装环境
确保本地或云端环境已安装 Python 3.8 或更高版本,并配置好 pip 包管理器。运行以下命令安装必要依赖:
pip install transformers torch
transformers是 Hugging Face 提供的库,用于加载和运行模型。torch是 PyTorch 框架,确保模型推理正常运行。
如果使用 GPU 加速,需安装支持 CUDA 的 PyTorch 版本。请参考 PyTorch 官网,根据硬件配置选择合适的版本,例如:
pip install torch --index-url https://download.pytorch.org/whl/cu118
2. 下载模型
DeepSeek-TNG-R1T2-Chimera 的模型权重可直接从 Hugging Face 下载。使用以下 Python 代码加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "tngtech/DeepSeek-TNG-R1T2-Chimera"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
- 确保网络连接稳定,模型文件较大,下载可能需要时间。
- 如果本地存储空间有限,可使用 Hugging Face 的
cache_dir参数指定缓存路径:
model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir="/path/to/cache")
3. 配置运行环境
模型支持 CPU 和 GPU 运行。GPU 环境可显著提升推理速度。确保 GPU 驱动和 CUDA 版本与 PyTorch 兼容。如果使用多 GPU,可启用 device_map="auto" 自动分配:
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
4. 使用模型
加载模型后,可以通过以下代码进行文本生成或推理:
input_text = "请解释量子计算的基本原理"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # 如果使用 GPU
outputs = model.generate(**inputs, max_length=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
max_length参数控制生成文本的最大长度,可根据需求调整。- 若需更高质量输出,可设置
temperature=0.7和top_p=0.9调整生成随机性:
outputs = model.generate(**inputs, max_length=200, temperature=0.7, top_p=0.9)
5. 主要功能操作
- 文本生成:输入任意文本提示,模型可生成连贯的回答。例如,输入“写一篇关于AI伦理的短文”,模型会生成结构清晰的文章。
- 逻辑推理:输入复杂问题,如“解决以下数学问题:x^2 + 2x – 8 = 0”,模型会逐步推理并给出答案。
- 多语言任务:输入非英语提示,如“用西班牙语介绍巴黎”,模型会生成相应语言的回答。
- 优化推理:通过设置
max_length和num_beams(如num_beams=4)启用束搜索,提升生成质量:
outputs = model.generate(**inputs, max_length=200, num_beams=4)
6. 部署到生产环境
若需将模型部署到服务器,推荐使用 Hugging Face 的 Inference API 或第三方推理服务(如 vLLM)。本地部署时,需确保服务器有足够内存(建议 32GB 以上)和 GPU 资源(至少 16GB 显存)。可参考 Hugging Face 官方文档:
https://huggingface.co/docs/transformers/main/en/main_classes/pipelines
7. 注意事项
- 模型未部署在任何推理提供商,需自行下载和配置。
- 运行前检查硬件资源,671B 参数量需要较高算力。
- 若需微调,可使用 Hugging Face 的
Trainer类,参考官方文档:
https://huggingface.co/docs/transformers/main/en/training
特色功能操作
- 高效推理:相比 R1-0528,R1T2 的 token 效率更高,适合高频推理任务。设置
max_length=100可快速生成短文本。 - 标记修复:模型在推理时自动处理 标记,确保输出一致。无需手动干预。
- 开源灵活性:开发者可修改模型权重,适配特定任务。例如,微调后可用于定制化对话系统。
应用场景
- 学术研究
研究人员可使用 R1T2 分析学术文献、生成研究报告或解答复杂问题。例如,输入“总结量子力学最新进展”,模型会提取关键信息并生成简洁报告。 - 内容创作
内容创作者可利用模型生成文章、社交媒体帖子或营销文案。输入“写一篇关于环保的博客”,即可获得结构清晰的文章。 - 技术开发
开发者可将模型集成到聊天机器人或智能助手中,支持多语言交互和复杂任务处理。例如,构建客服机器人处理用户查询。 - 教育辅助
学生和教师可使用模型解答数学、物理等问题,或生成学习材料。例如,输入“解释牛顿第二定律”,模型会提供详细讲解。
QA
- DeepSeek-TNG-R1T2-Chimera 适合哪些用户?
适合需要高效文本生成和推理的开发者、研究人员和内容创作者。模型开源,适合有一定编程能力的用户。 - 与 DeepSeek-R1T 相比,R1T2 有何改进?
R1T2 融合三个母模型,速度提高 20%,修复 标记问题,并在 GPQA 等测试中表现更优。 - 如何降低模型运行的硬件需求?
可使用模型量化技术(如 4-bit 量化)或云端 GPU 部署,参考 Hugging Face 文档。 - 模型支持哪些语言?
支持多语言,包括英语、中文、西班牙语等,具体支持范围需测试验证。