
GLM-4.1V-Thinking ist ein quelloffenes visuelles Sprachmodell, das vom KEG Lab der Tsinghua Universität (THUDM) entwickelt wurde und sich auf multimodale Argumentationsfähigkeiten konzentriert. Basierend auf dem Basismodell GLM-4-9B-0414 verwendet GLM-4.1V-Thinking Verstärkungslernen und "chain-of-mind"-Schlussfolgernde Mechanismen,...

Trackers ist eine Open-Source-Python-Werkzeugbibliothek, die sich auf die Verfolgung mehrerer Objekte in Videos konzentriert. Sie integriert mehrere führende Verfolgungsalgorithmen wie SORT und DeepSORT und ermöglicht es den Benutzern, verschiedene Modelle zur Objekterkennung (z. B. YOLO, RT-DETR) für eine flexible Videoanalyse zu kombinieren. Benutzer können einfach...

Describe Anything ist ein von NVIDIA und mehreren Universitäten entwickeltes Open-Source-Projekt, dessen Kernstück das Describe Anything Model (DAM) ist. Dieses Tool generiert detaillierte Beschreibungen auf der Grundlage von Bereichen (wie Punkte, Kästchen, Kritzeleien oder Masken), die der Benutzer in einem Bild oder Video markiert. Es ist nicht ...

Find My Kids ist ein Open-Source-Projekt, das auf GitHub gehostet und vom Entwickler Tomer Klein erstellt wurde. Es kombiniert die DeepFace-Gesichtserkennungstechnologie mit der WhatsApp Green API und soll Eltern dabei helfen, die WhatsApp-Gruppen ihrer Kinder durch...
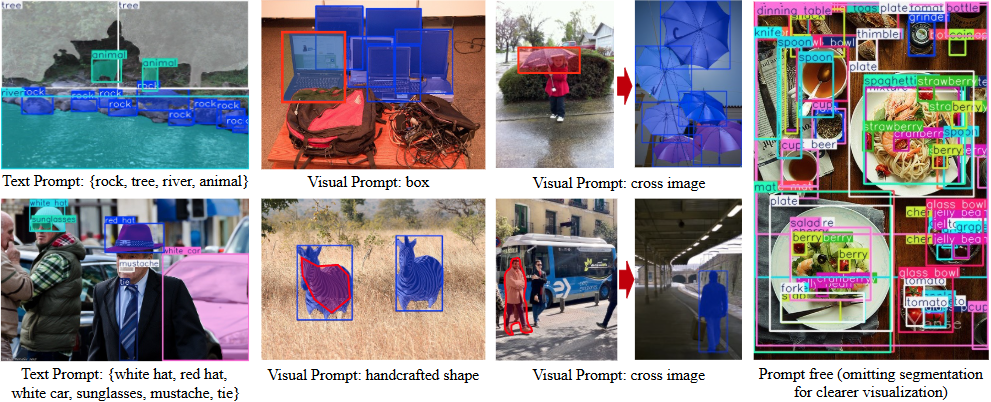
YOLOE ist ein Open-Source-Projekt, das von der Multimedia Intelligence Group (THU-MIG) an der School of Software der Tsinghua-Universität entwickelt wurde und den vollständigen Namen "You Only Look Once Eye" trägt. Es basiert auf dem PyTorch-Framework, gehört zur YOLO-Serie von Erweiterungen und kann jedes Objekt in Echtzeit erkennen und segmentieren. Das Projekt wird auf GitHu gehostet...
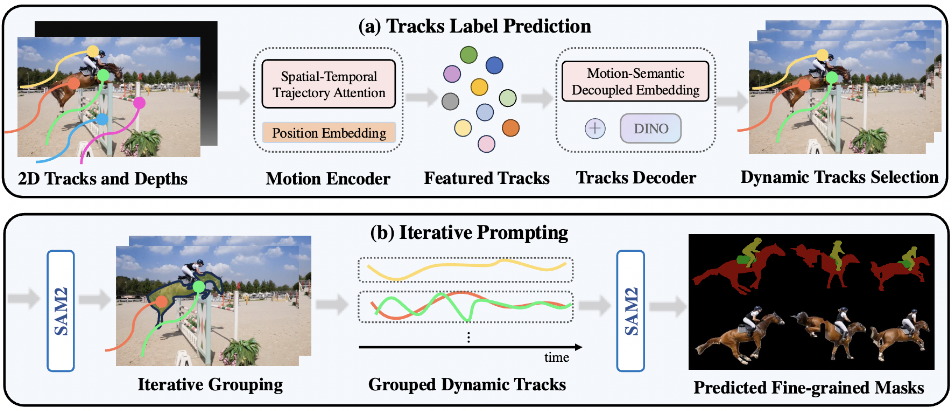
SegAnyMo ist ein Open-Source-Projekt, das von einem Team von Forschern der UC Berkeley und der Universität Peking entwickelt wurde, zu denen auch Nan Huang gehört. Dieses Tool konzentriert sich auf die Videoverarbeitung und kann automatisch beliebige bewegte Objekte in einem Video identifizieren und segmentieren, z. B. Menschen, Tiere oder Fahrzeuge. Es kombiniert TAPNet, DINO...

RF-DETR ist ein Open-Source-Objekterkennungsmodell, das vom Roboflow-Team entwickelt wurde. Es basiert auf der Transformer-Architektur und sein Hauptmerkmal ist die Echtzeit-Effizienz. Zum ersten Mal erreicht das Modell eine Echtzeit-Erkennung von über 60 APs im Microsoft COCO-Datensatz und schneidet auch im RF100-VL-Benchmark gut ab...

HumanOmni ist ein quelloffenes multimodales Big Model, das vom HumanMLLM-Team entwickelt und auf GitHub gehostet wird. Es konzentriert sich auf die Analyse von menschlichem Video und kann sowohl Bild als auch Ton verarbeiten, um Emotionen, Bewegungen und Dialoginhalte zu verstehen. Für das Projekt wurden 2,4 Millionen menschenzentrierte Videoclips und 14 Millionen .....

Vision Agent ist ein Open-Source-Projekt, das von LandingAI (Enda Wus Team) entwickelt wurde und auf GitHub gehostet wird, um Benutzern zu helfen, schnell Code zu generieren, um Computer-Vision-Aufgaben zu lösen. Es nutzt ein fortschrittliches Agenten-Framework und ein multimodales Modell, um effiziente Vision-KI-Agenten mit einfachen Eingabeaufforderungen zu erzeugen...

Make Sense ist ein kostenloses Online-Tool zur Bildkommentierung, das Benutzern helfen soll, Datensätze für Computer-Vision-Projekte schnell vorzubereiten. Es erfordert keine komplizierte Installation, öffnen Sie einfach einen Browser-Zugang, um es zu verwenden, unterstützt mehrere Betriebssysteme und ist perfekt für kleine Deep-Learning-Projekte. Benutzer können es verwenden, um Bilder zu...

YOLOv12 ist ein Open-Source-Projekt, das vom GitHub-Benutzer sunsmarterjie entwickelt wurde und sich auf Echtzeit-Zielerkennungstechnologie konzentriert. Das Projekt basiert auf der YOLO (You Only Look Once)-Reihe von Frameworks, die Einführung von Aufmerksamkeitsmechanismen zur Optimierung der Leistung traditioneller Faltungsneuronaler Netze (CNN), nicht nur ...

VLM-R1 ist ein Open-Source-Projekt zur visuellen Sprachmodellierung, das von Om AI Lab entwickelt und auf GitHub gehostet wird. Das Projekt basiert auf DeepSeeks R1-Ansatz, kombiniert mit dem Qwen2.5-VL-Modell, und verbessert das Modell durch Verstärkungslernen (R1) und überwachte Feinabstimmung (SFT) in...
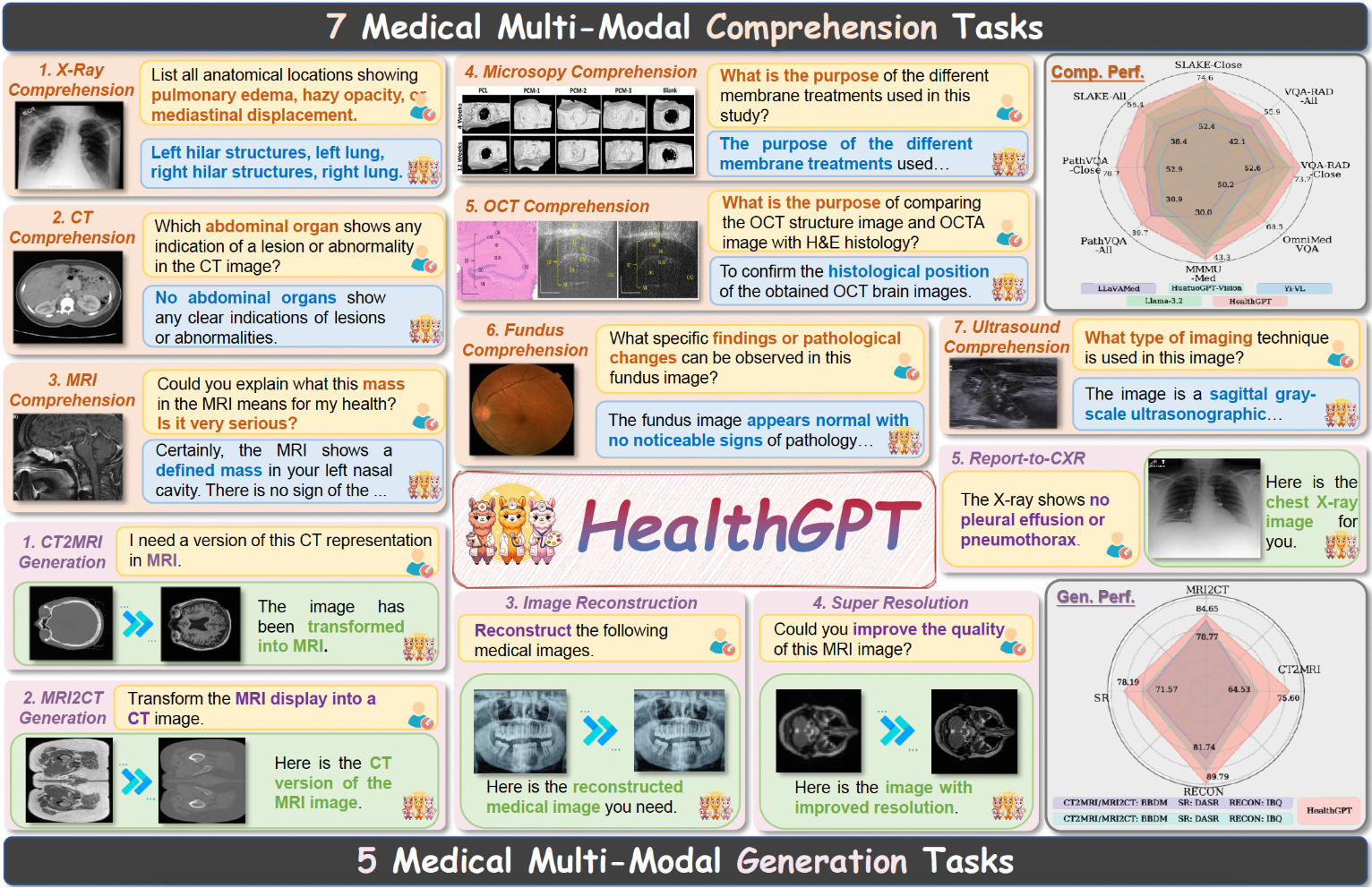
HealthGPT ist ein hochmodernes medizinisches visuelles Sprachmodell, das darauf abzielt, ein einheitliches medizinisches visuelles Verständnis und Generierungsfähigkeiten durch heterogene Wissensanpassung zu erreichen. Das Ziel des Projekts ist es, das Verständnis und die Generierung von medizinischem Bildmaterial in einen einheitlichen autoregressiven Rahmen zu integrieren und so die Effizienz und Genauigkeit der medizinischen Bildverarbeitung deutlich zu verbessern...
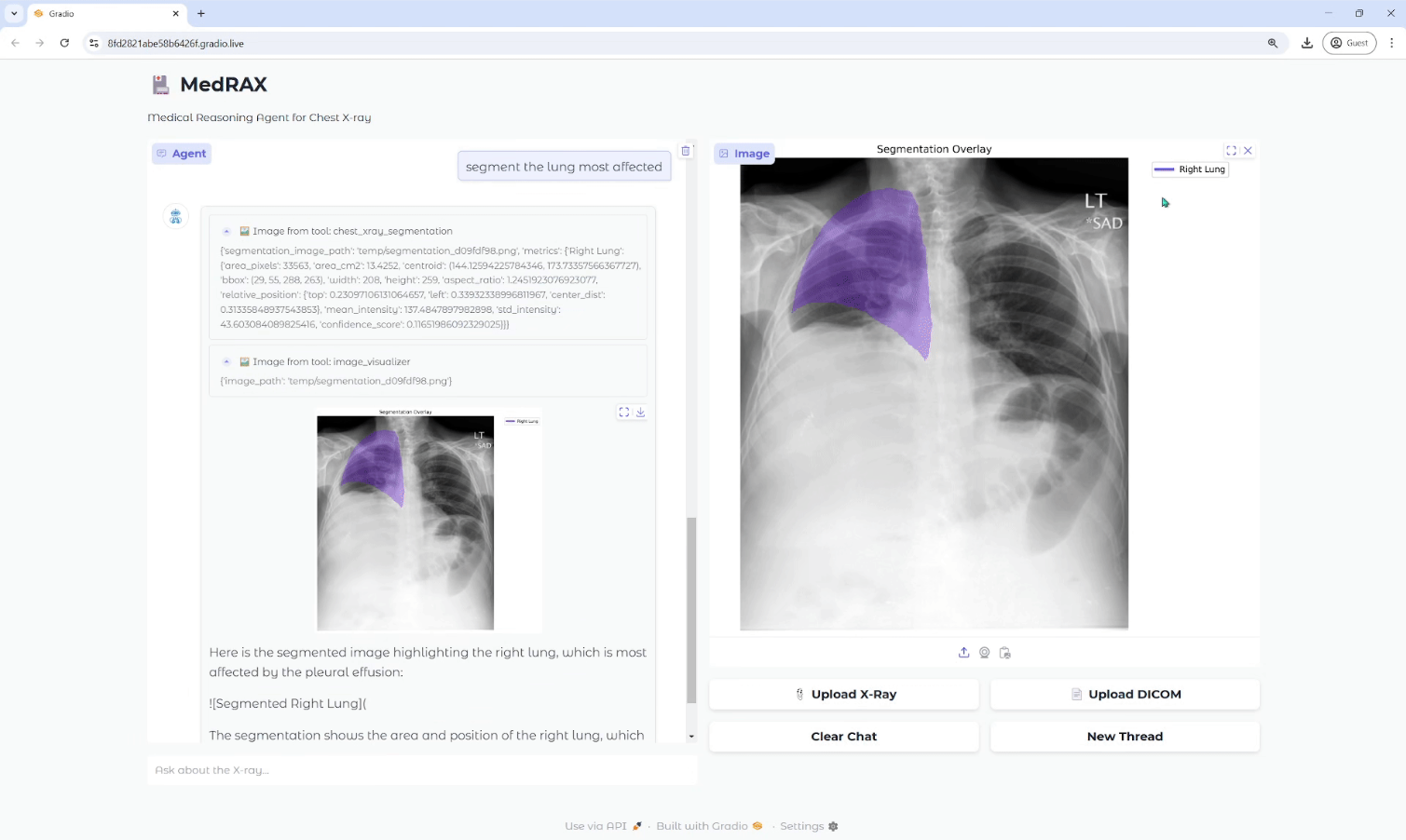
MedRAX ist eine hochmoderne KI-Intelligenz, die speziell für die Analyse von Röntgenaufnahmen der Brust (CXR) entwickelt wurde. Es integriert modernste CXR-Analysetools und multimodale große Sprachmodelle zur dynamischen Verarbeitung komplexer medizinischer Anfragen ohne zusätzliches Training.MedRAX bietet durch seinen modularen Aufbau und seine starke technologische...

Agentic Object Detection ist ein fortschrittliches Zielerkennungswerkzeug von Landing AI. Das Tool vereinfacht den Prozess der herkömmlichen Zielerkennung erheblich, indem es Textaufforderungen für die Erkennung verwendet, ohne dass eine Datenbeschriftung und ein Modelltraining erforderlich sind. Benutzer laden einfach ein Bild hoch und geben die Erkennungsaufforderungen ein, und der KI-Agent kann .....
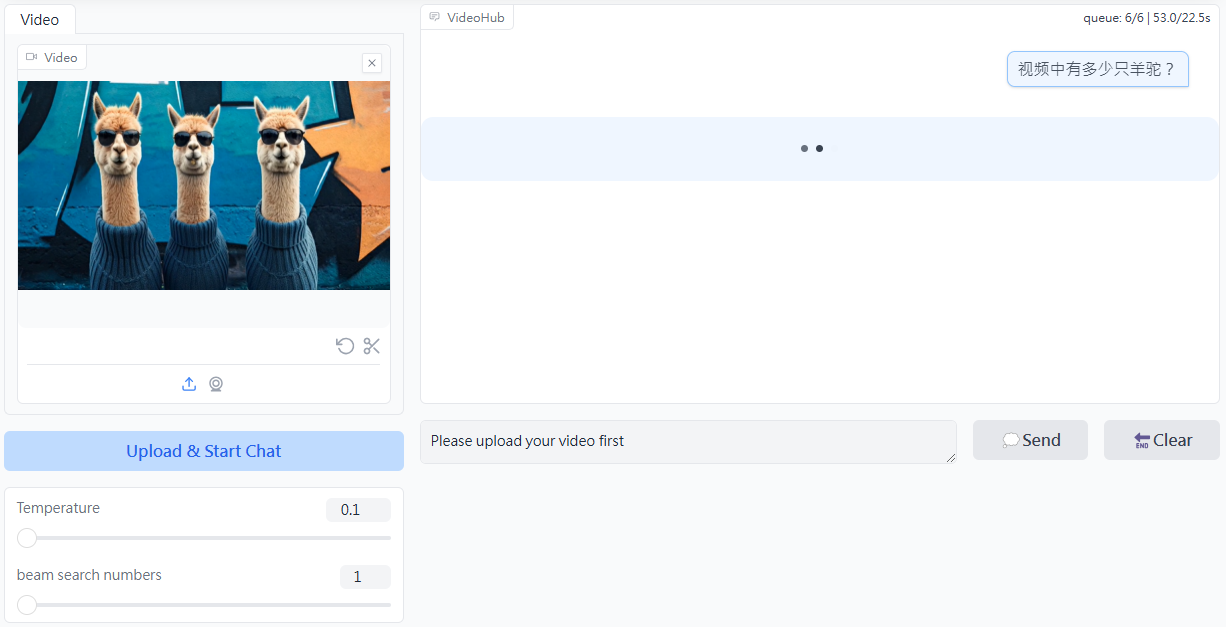
CogVLM2 ist ein quelloffenes multimodales Modell, das von der Tsinghua University Data Mining Research Group (THUDM) entwickelt wurde. Es basiert auf der Llama3-8B-Architektur und soll eine vergleichbare oder sogar bessere Leistung als GPT-4V bieten. Das Modell unterstützt das Verstehen von Bildern, den Dialog in mehreren Runden und das Verstehen von Videos und ist in der Lage, Inhalte mit einer Länge von bis zu 8K zu verarbeiten und unterstützt...
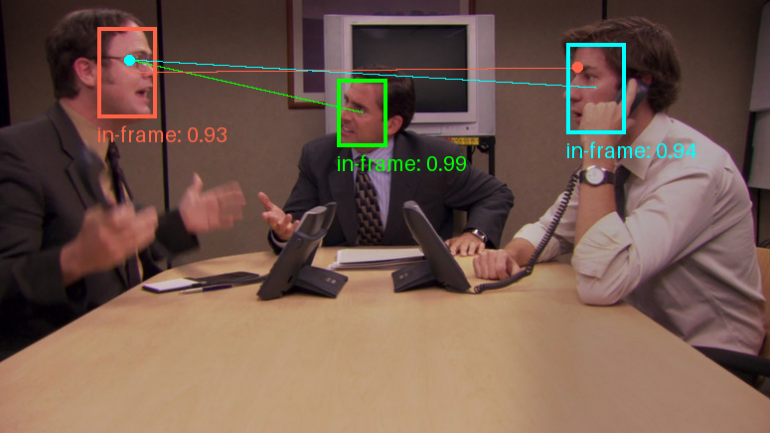
Gaze-LLE ist ein Tool zur Blickzielvorhersage, das auf einem groß angelegten Lern-Encoder basiert. Entwickelt von Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman und James M. Rehg, zielt es darauf ab, vortrainierte visuelle...
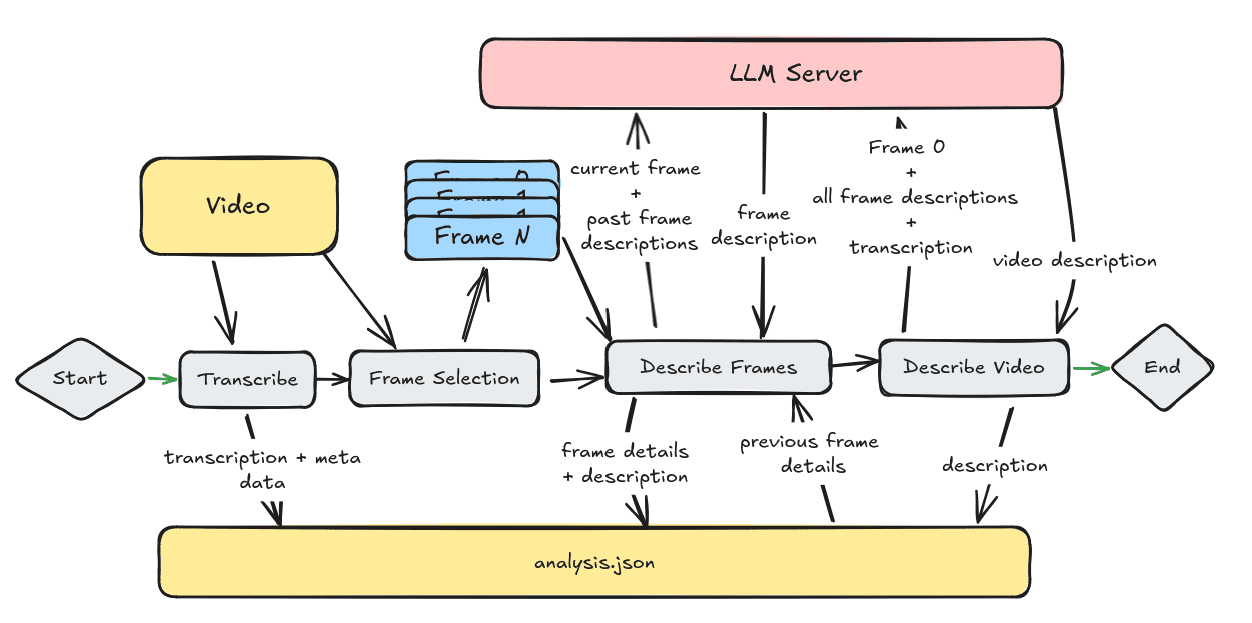
Video Analyzer ist ein umfassendes Videoanalysetool, das Computer Vision, Audiotranskription und natürliche Sprachverarbeitungstechniken kombiniert, um detaillierte Beschreibungen von Videoinhalten zu erstellen. Das Tool erzeugt natürlichsprachliche Beschreibungen, indem es Schlüsselbilder aus dem Video extrahiert, Audioinhalte transkribiert und...

Twelve Labs ist ein Unternehmen für multimodale KI, das sich auf das Verstehen von Videos spezialisiert hat und Nutzern durch fortschrittliche KI-Technologien hilft, große Mengen an Videoinhalten zu verstehen und zu verarbeiten. Zu den Kerntechnologien gehören Videosuche, -generierung und -einbettung, die in der Lage sind, Schlüsselmerkmale aus Videos zu extrahieren, wie z. B. Aktionen, Objekte, Bildschirmtext, Sprache und Charaktere...

