
Versatile OCR Program ist ein Open-Source-Tool für die optische Zeichenerkennung (OCR), das für die Verarbeitung komplexer akademischer und pädagogischer Dokumente entwickelt wurde. Es kann Text, Tabellen, mathematische Formeln, Diagramme und Schemata aus PDF-, Bild- und anderen Dokumenten extrahieren und strukturierte Daten erzeugen, die für das Training von maschinellem Lernen geeignet sind. Unterstützt...
Es analysiert automatisch das Layout von PDF-Dokumenten, identifiziert Text, Titel, Bilder, Tabellen, Formeln und andere Elemente auf der Seite und bestimmt ihre richtige Reihenfolge. Das Tool unterstützt OCR-Funktionalität, Sie können gescannte PDFs in durchsuchbaren Text umwandeln. Es läuft auf Docker und bietet zwei Modelle: visuelles Modell (Vision Grid ...
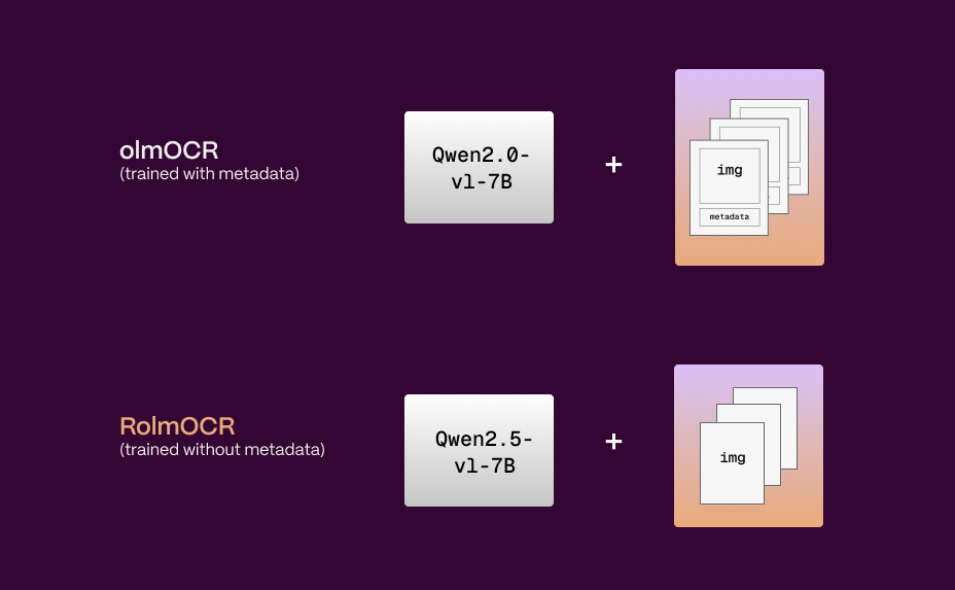
RolmOCR ist ein Open-Source-Tool zur optischen Zeichenerkennung (OCR), das vom Reducto AI-Team entwickelt wurde und auf dem visuellen Sprachmodell Qwen2.5-VL-7B basiert. Es kann Text aus Bildern und PDF-Dateien schneller als ähnliche Tools extrahieren olmOCR, geringerer Speicherbedarf.RolmOCR...
uniOCR ist ein Open-Source-Tool zur Texterkennung, das vom mediar-ai-Team entwickelt wurde. Es basiert auf der Sprache Rust und unterstützt macOS, Windows und Linux Systeme. Benutzer können es verwenden, um Text aus Bildern zu extrahieren, einfach zu bedienen und kostenlos. uniOCRs Kernfunktionen sind plattformübergreifende Unterstützung...

PDF Craft ist ein Open-Source-Tool, mit dem PDFs von Büchern gescannt und in das Markdown-Format konvertiert werden können. Es wird von oomol-lab entwickelt und auf GitHub für Benutzer gehostet, die ihre eBooks organisieren möchten. Das Tool läuft über ein lokales KI-Modell und benötigt keine Internetverbindung, was die Privatsphäre schützt und die Bedienung erleichtert. ....

SmolDocling ist ein Visual Language Model (VLM), das vom ds4sd-Team in Zusammenarbeit mit IBM entwickelt wurde. Es basiert auf SmolVLM-256M und wird auf der Hugging Face-Plattform gehostet. SmolDocling ist das kleinste VLM der Welt mit nur 256M Parametern, und seine Kernfunktion ist...

In der langen Geschichte der menschlichen Zivilisation hat jeder Sprung in der Art und Weise, wie Informationen erworben und ausgewertet werden, den sozialen Fortschritt entscheidend vorangetrieben. Von den antiken Hieroglyphen über den tragbaren Papyrus bis hin zur späteren Entwicklung des Buchdrucks und der heutigen digitalen Welle hat jede technologische Innovation die Weitergabe von menschlichem Wissen erheblich erweitert...
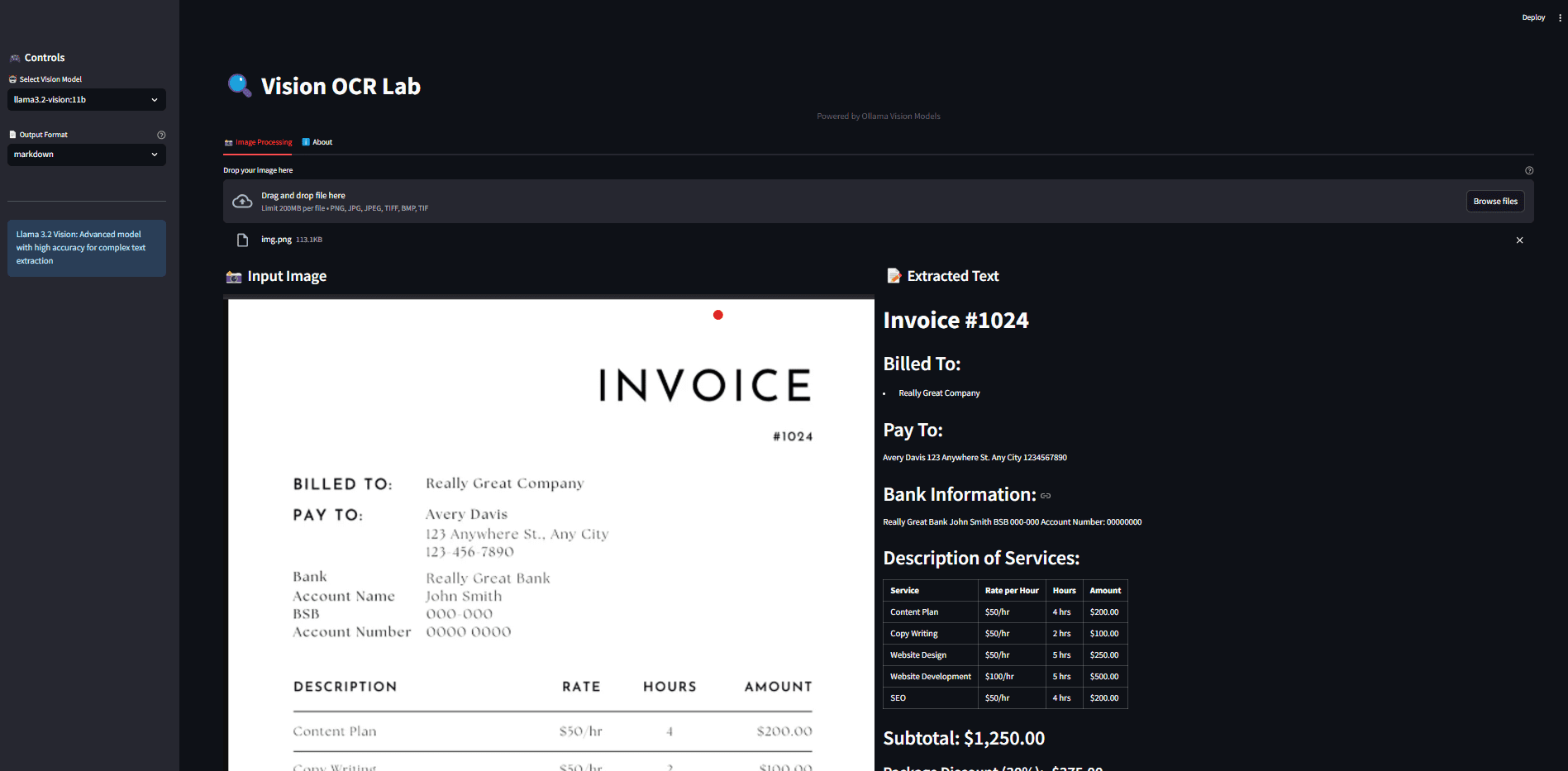
Ollama OCR ist ein leistungsstarkes Toolkit für die optische Zeichenerkennung (OCR), das das hochmoderne visuelle Sprachmodell der Ollama-Plattform nutzt, um Text aus Bildern zu extrahieren. Das Projekt ist sowohl als Python-Paket verfügbar als auch mit einer benutzerfreundlichen Streamlit-Webanwendungsschnittstelle. Es unterstützt eine breite Palette von visuellen Modellen...

STranslate ist ein gebrauchsfertiges Übersetzungs- und OCR-Tool, das von WPF entwickelt wurde. Das Tool wurde entwickelt, um eine effiziente und bequeme Übersetzung und OCR-Funktionalität (Optical Character Recognition) für eine Vielzahl von Sprachen und Texttypen zu bieten.STranslate ist ein Open-Source-Projekt, das für Benutzer kostenlos heruntergeladen und...
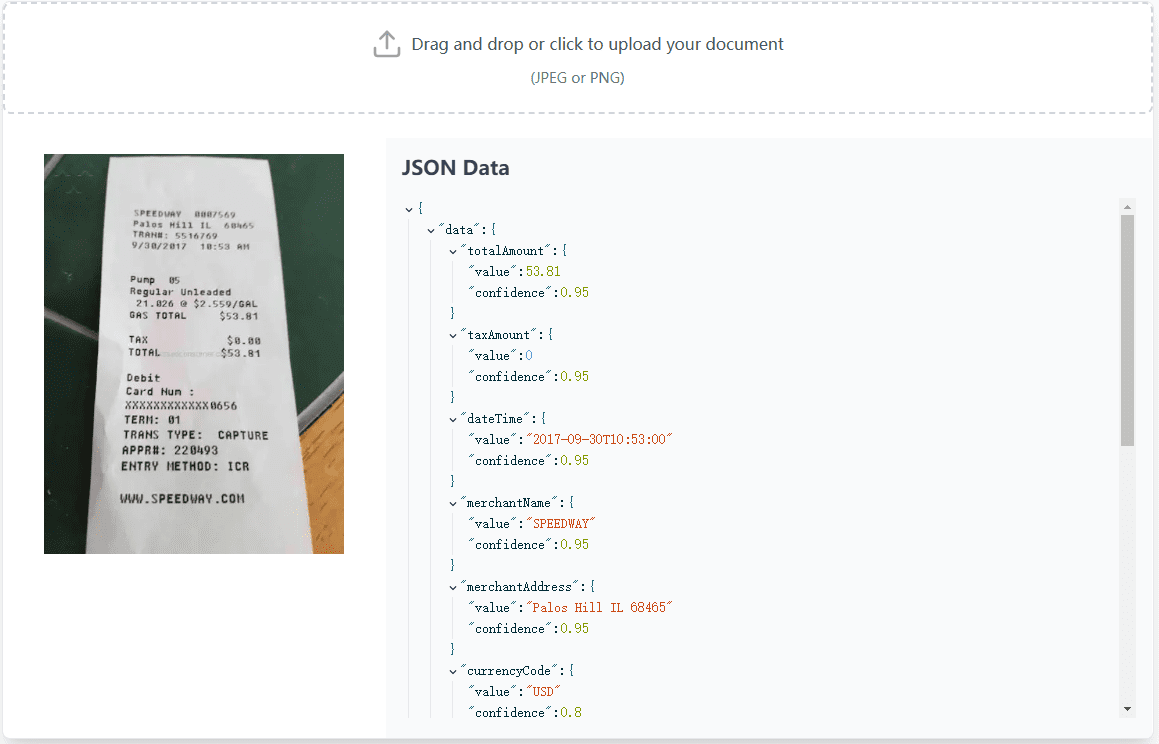
VisionParser ist ein OCR-Tool (Optical Character Recognition) für die Verarbeitung von Quittungen und Rechnungen. Dank der fortschrittlichen generativen KI-Technologie kann VisionParser alle Arten von Quittungen und Rechnungen schnell und präzise in strukturierte Daten für eine Vielzahl von Geschäftsszenarien umwandeln, z. B. für den Einzelhandel, die Gastronomie, B2B-Dienstleistungen usw. ....
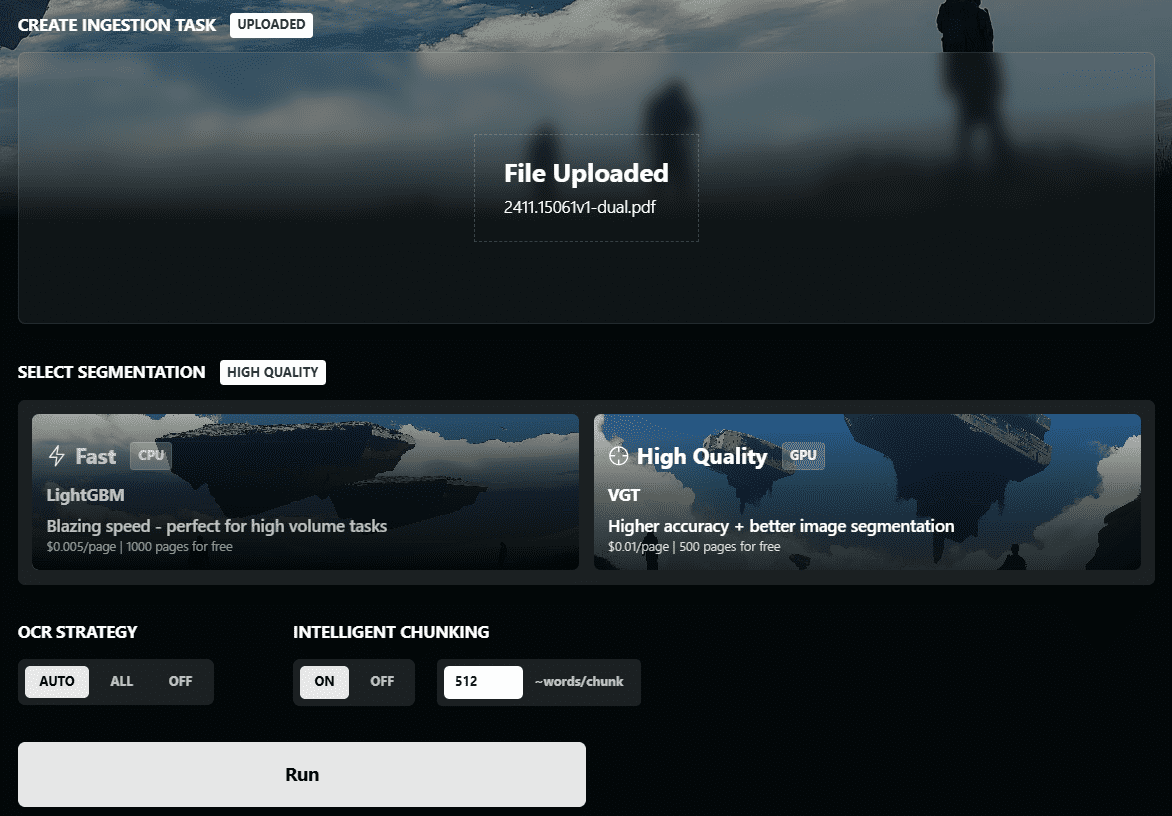
Chunkr ist eine selbst gehostete API zur Konvertierung von PDF-, PPTX-, DOCX- und Excel-Dateien in Daten, die für die Verwendung in RAG (Retrieval Augmented Generation) und LLM (Large Language Modelling) geeignet sind. Es wurde von Lumina AI Inc. entwickelt und verwendet fortschrittliche visuelle Modelle für...
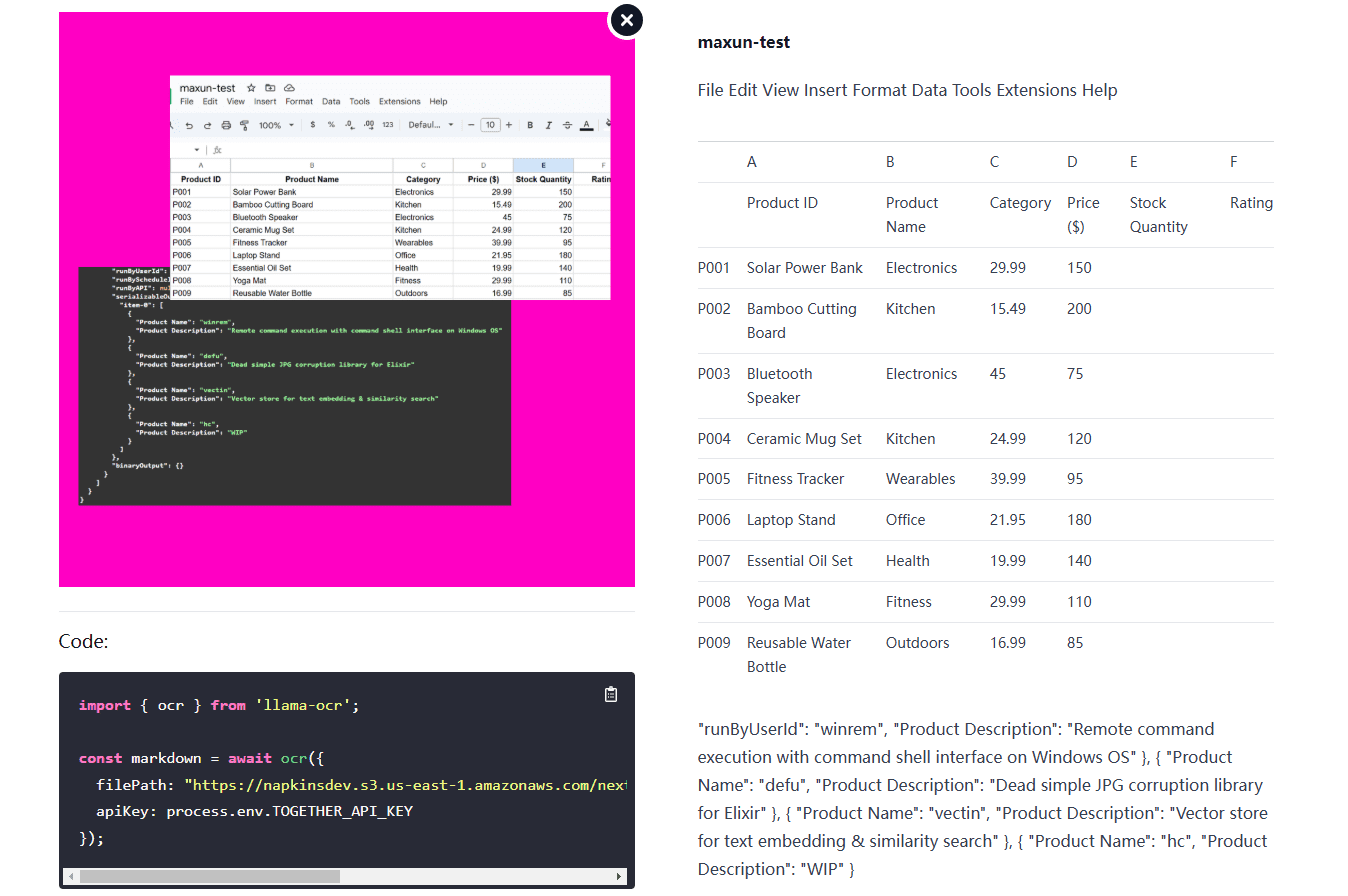
Llama OCR ist eine OCR-Bibliothek (Optical Character Recognition), die auf Llama 3.2 Vision basiert und Dokumente in das Markdown-Format konvertiert. Die Bibliothek wurde von Nutlope entwickelt und verwendet die kostenlose Llama 3.2-Schnittstelle, die von Together AI für...

Docling ist ein leistungsfähiges Tool zum Parsen und Exportieren von Dokumenten, das eine Vielzahl von Dokumentenformaten unterstützt, darunter PDF, DOCX, PPTX, XLSX, Image, HTML, AsciiDoc und Markdown. Es analysiert und exportiert diese Dokumente in die Formate HTML, Markdown und JSON....
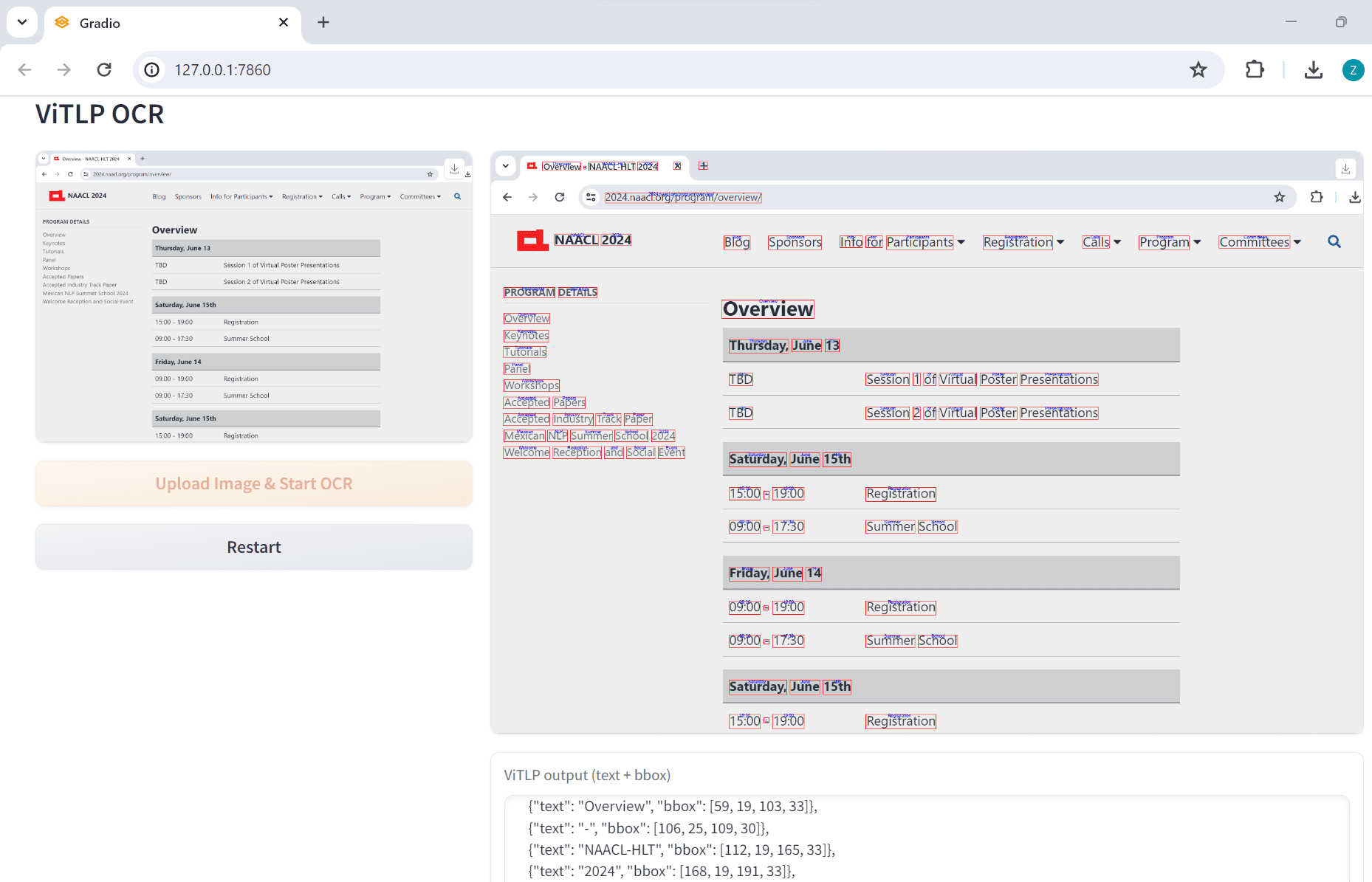
ViTLP (Visually Guided Generative Text-Layout Pre-training for Document Intelligence) ist ein Open-Source-Projekt, das darauf abzielt, die Verarbeitung von Dokumenten durch visuell geführte generative Text-Layout Pre-training-Modelle zu verbessern ...

ScreenPipe ist ein von mediar-ai entwickelter KI-Assistent, der sich auf die Aufnahme von Bildschirminhalten, Screenshots und Audio 24/7 konzentriert. Er kombiniert die Technologien von rewind.ai und cursor.com, um aufgezeichnete Daten in einer lokalen Datenbank zu speichern und unterstützt chinesische...
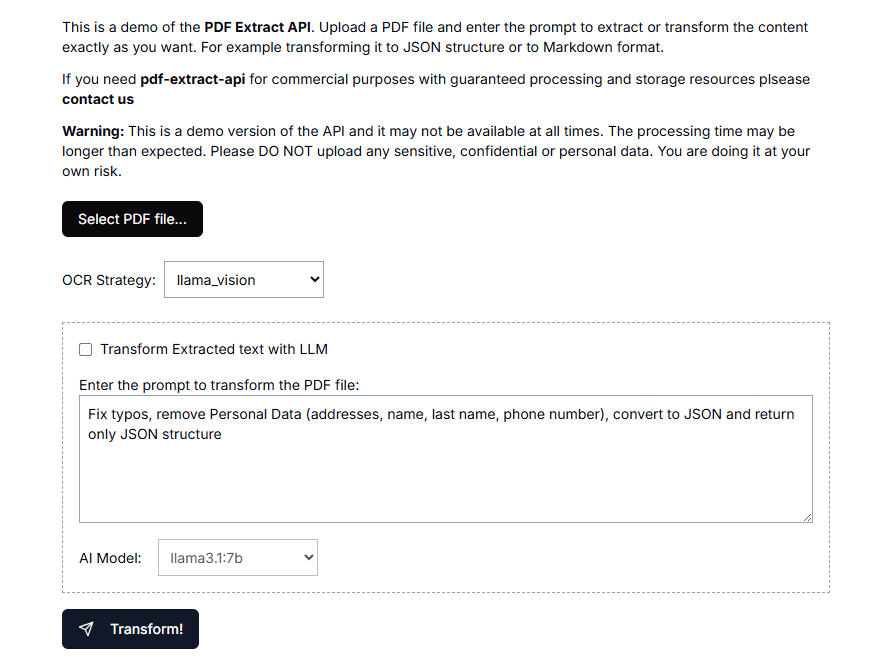
Die Textextraktions-API (text-extract-api) ist ein leistungsfähiges Tool zum Extrahieren und Parsen von Inhalten aus einer Vielzahl von Dokumentformaten (z. B. PDF, Word, PPTX usw.). Die API nutzt modernste OCR-Technologie (Optical Character Recognition) und von Ollama unterstützte Modelle, um jedes beliebige Dokument oder Bild in einen Knoten zu konvertieren ....
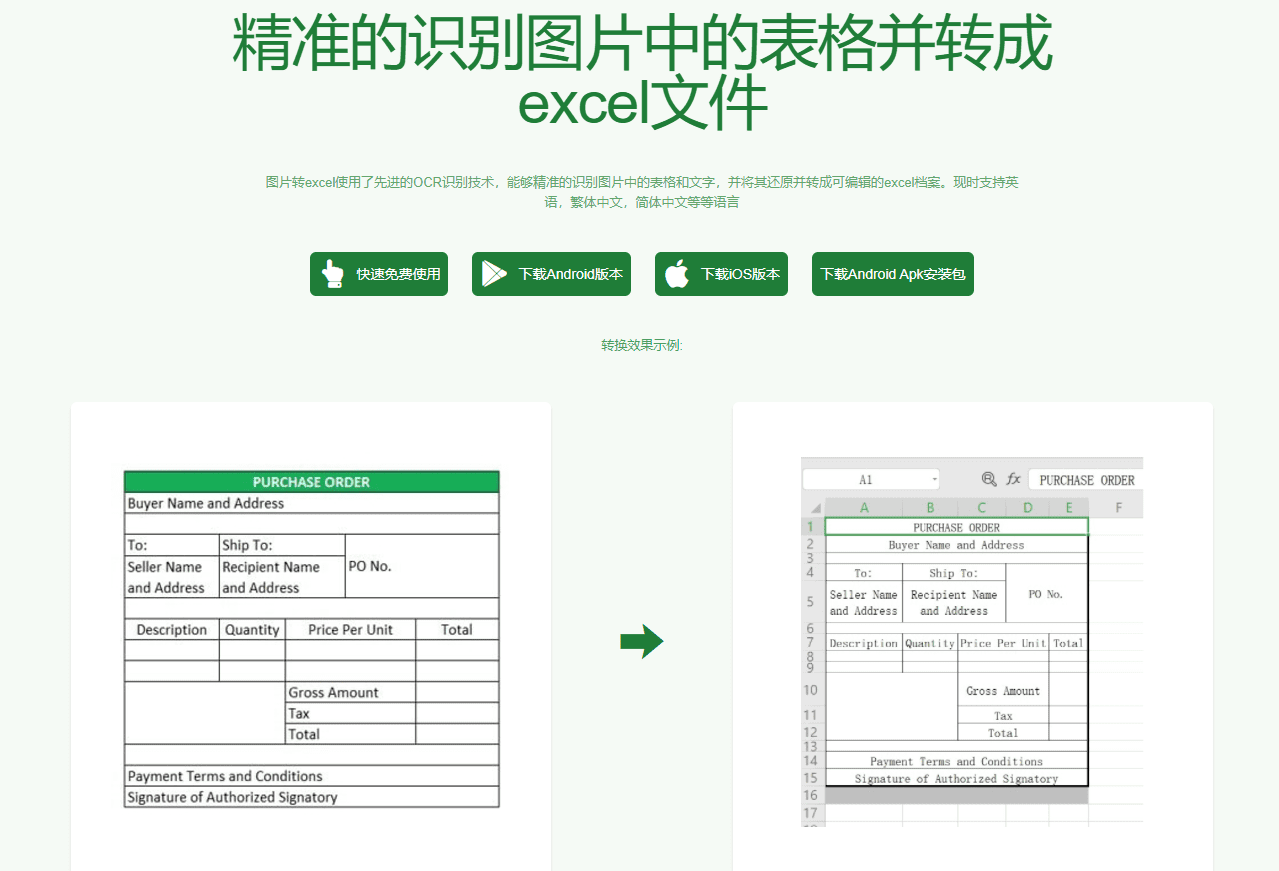
Picture to Excel Free Tool ist ein effizientes Online-Tool, das schnell und präzise Tabellendaten aus Bildern identifiziert und in Excel-Dateien konvertiert. Das Tool unterstützt eine Vielzahl von Bildformaten, wie JPG und PNG, und kann auf Webseiten, iOS-Apps und Android-Apps verwendet werden. Mit fortschrittlicher KI-Technologie kann der...

Datalab bietet eine Reihe von fortschrittlichen KI-Modellen mit Schwerpunkt auf OCR, Layout-Analyse, PDF zu Markdown und mehr. Diese Modelle sind nicht nur leistungsstark, sondern auch einfach zu bedienen und quelloffen. Die Marker-Modelle auf der Plattform können PDF schnell und präzise in Markdown konvertieren, einschließlich Tabellen und Formeln...
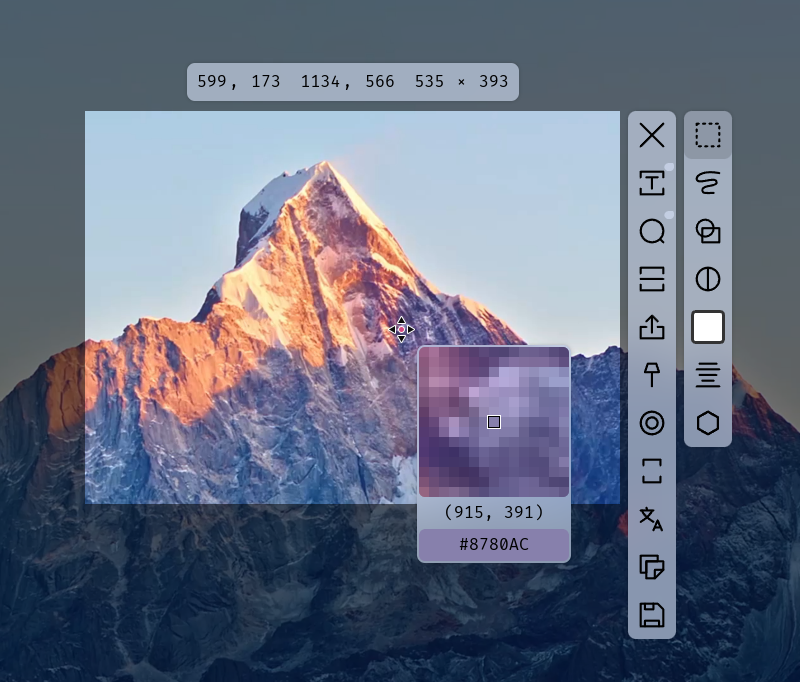
eSearch ist ein plattformübergreifendes Open-Source-Screenshot-Tool, das von xushengfeng für Windows, macOS und Linux entwickelt wurde. Es integriert eine Vielzahl von Funktionen wie Screenshot, OCR-Erkennung, Suche, Übersetzung, Mapping, Bildsuche und Bildschirmaufzeichnung. eSearch verwendet Elec...

