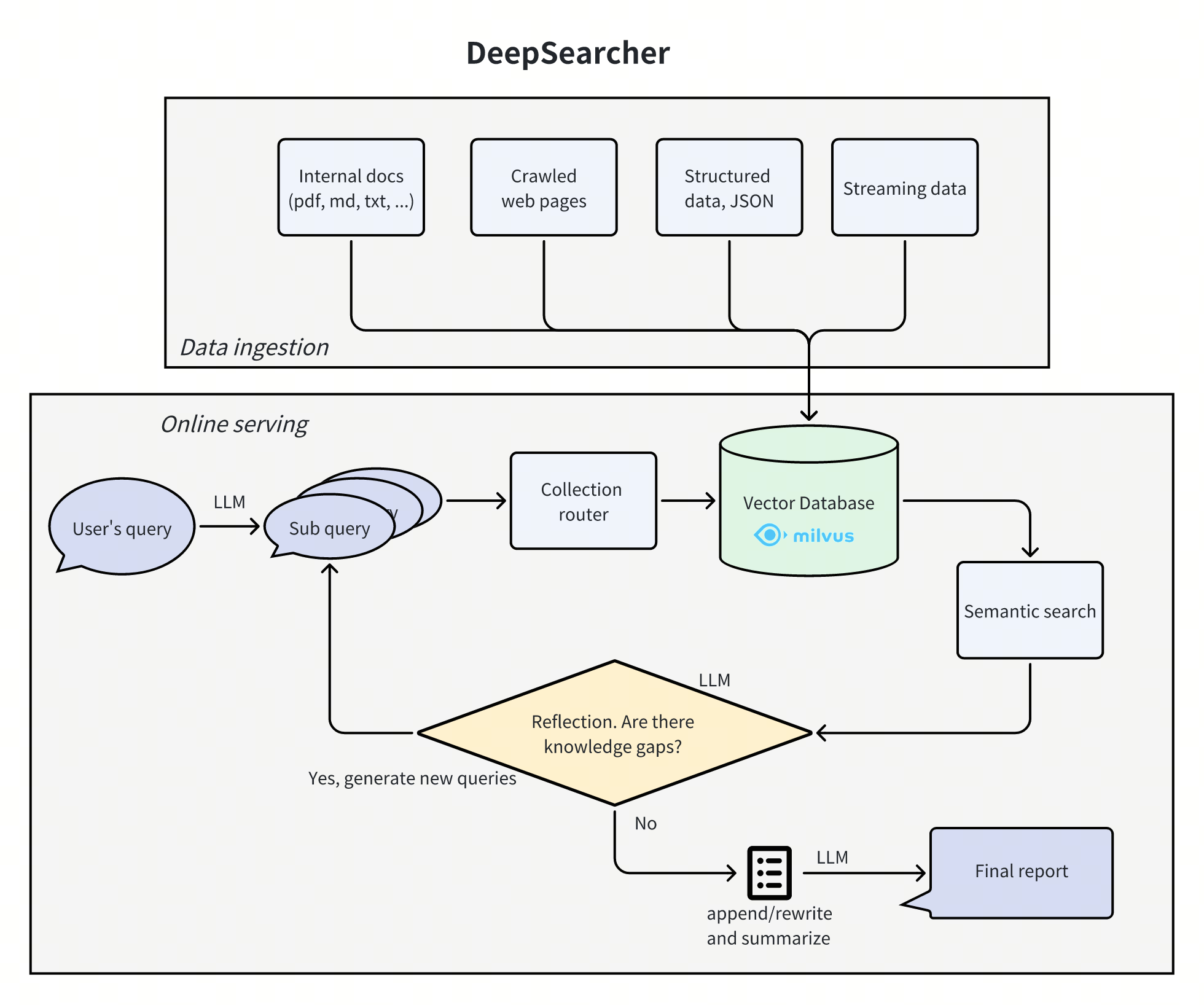
MultiTalk ist ein von MeiGen-AI entwickeltes Open-Source-Tool zur Erzeugung von Multiplayer-Dialogvideos. Es erzeugt lippensynchrone interaktive Multiplayer-Videos mit mehreren Audioeingängen, Referenzbildern und Textaufforderungen. Das Projekt unterstützt die Videogenerierung von realen und Cartoon-Charakteren und eignet sich für Dialog-, Gesangs- und Interaktionssteuerungsszenarien usw. MultiTalk verwendet die innovative L-RoPE-Technologie, um das Problem der Audio- und Charakterbindung zu lösen, und stellt sicher, dass die Lippenbewegungen genau auf den Ton abgestimmt sind. Das Projekt bietet Modellgewichte und eine ausführliche Dokumentation auf GitHub unter der Apache 2.0-Lizenz und ist für die akademische Forschung und Technologieentwickler geeignet.

Funktionsliste
- Unterstützung für die Erstellung von Dialogvideos mit mehreren Personen: Auf der Grundlage mehrerer Audioeingaben können Videos von mehreren Personen erstellt werden, die miteinander interagieren, wobei die Lippenbewegungen mit dem Audio synchronisiert werden.
- Generierung von Zeichentrickfiguren: Unterstützung der Generierung von Dialogen oder Gesangsvideos von Zeichentrickfiguren zur Erweiterung der Anwendungsszenarien.
- Interaktionssteuerung: Steuern Sie das Verhalten der Figur und die Interaktionslogik durch Textaufforderungen.
- Auflösungsflexibilität: Unterstützt 480p- und 720p-Videoausgänge, um verschiedene Geräte zu unterstützen.
- L-RoPE-Technologie: Löst das Problem der mehrfachen Audio- und Zeichenbindung durch Einbettung der Etikettendrehung in die Position und verbessert die Genauigkeit der Erzeugung.
- TeaCache-Beschleunigung: Optimiert die Geschwindigkeit der Videoerzeugung für Geräte mit geringem Videospeicher.
- Open-Source-Modelle: Bereitstellung von Modellgewichten und -code, die von Entwicklern frei heruntergeladen und angepasst werden können.
Hilfe verwenden
Einbauverfahren
Um MultiTalk zu verwenden, müssen Sie die Laufzeitumgebung lokal konfigurieren. Im Folgenden finden Sie detaillierte Installationsschritte für Python-Entwickler oder -Forscher:
- Erstellen einer virtuellen Umgebung
Erstellen Sie eine Python 3.10-Umgebung mit Conda, um die Isolierung von Abhängigkeiten zu gewährleisten:conda create -n multitalk python=3.10 conda activate multitalk - Installation von PyTorch und verwandten Abhängigkeiten
Installieren Sie PyTorch 2.4.1 und seine Begleitbibliotheken, um die CUDA-Beschleunigung zu unterstützen:pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121 pip install -U xformers==0.0.28 --index-url https://download.pytorch.org/whl/cu121 - Installieren zusätzlicher Abhängigkeiten
Installieren Sie die erforderlichen Bibliotheken wie Ninja und Librosa:pip install ninja psutil packaging flash_attn conda install -c conda-forge librosa pip install -r requirements.txt - Download Modellgewichte
Laden Sie MultiTalk und die zugehörigen Modellgewichte von Hugging Face herunter:huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base huggingface-cli download MeiGen-AI/MeiGen-MultiTalk --local-dir ./weights/MeiGen-MultiTalk - Überprüfung der Umgebung
Vergewissern Sie sich, dass alle Abhängigkeiten korrekt installiert sind, und prüfen Sie, ob die GPU verfügbar ist (CUDA-kompatible GPUs werden empfohlen).
Verwendung
MultiTalk über Befehlszeilenskript generate_multitalk.py Video generieren. Der Benutzer muss die folgenden Eingaben vorbereiten:
- Mehrere AudioUnterstützung von Audiodateien im WAV-Format: Die Unterstützung von Audiodateien im WAV-Format gewährleistet, dass jeder Audiokanal der Stimme eines Charakters entspricht.
- ReferenzbildStellt ein Standbild des Aussehens der Figur zur Verfügung, das verwendet wird, um die Figur im Video zu erzeugen.
- TextmeldungText, der eine Szene oder die Interaktion einer Figur beschreibt, z. B. "Nick und Judy unterhalten sich im Café".
Kurze Videos generieren
Führen Sie den folgenden Befehl aus, um ein einzelnes kurzes Video zu erstellen:
python generate_multitalk.py \
--ckpt_dir weights/Wan2.1-I2V-14B-480P \
--wav2vec_dir weights/chinese-wav2vec2-base \
--input_json examples/single_example_1.json \
--sample_steps 40 \
--mode clip \
--size multitalk-480 \
--use_teacache \
--save_file output_short_video
Raw Growth Video
Verwenden Sie für lange Videos den Streaming-Erzeugungsmodus:
python generate_multitalk.py \
--ckpt_dir weights/Wan2.1-I2V-14B-480P \
--wav2vec_dir weights/chinese-wav2vec2-base \
--input_json examples/single_example_1.json \
--sample_steps 40 \
--mode streaming \
--use_teacache \
--save_file output_long_video
Optimierung für geringen Speicherbedarf
Wenn nicht genügend Videospeicher vorhanden ist, setzen Sie --num_persistent_param_in_dit 0::
python generate_multitalk.py \
--ckpt_dir weights/Wan2.1-I2V-14B-480P \
--wav2vec_dir weights/chinese-wav2vec2-base \
--input_json examples/single_example_1.json \
--sample_steps 40 \
--mode streaming \
--num_persistent_param_in_dit 0 \
--use_teacache \
--save_file output_lowvram_video
Beschreibung der Parameter
--mode::clipErstellung kurzer Videos.streamingRaw Growth Video.--size: Auswahlmultitalk-480vielleichtmultitalk-720Ausgabeauflösung.--use_teacacheAktivieren Sie die TeaCache-Beschleunigung, um die Generierungsgeschwindigkeit zu optimieren.--teacache_thresh: Werte von 0,2 bis 0,5 zum Ausgleich von Geschwindigkeit und Masse.
Featured Function Bedienung
- Generierung von Mehrspieler-Dialogen
Der Benutzer muss mehrere Audiospuren und entsprechende Referenzbilder vorbereiten. Die Audiodateien sollten klar sein, mit einer empfohlenen Abtastrate von 16kHz, und die Referenzbilder sollten das Gesicht oder den Körper der Figur enthalten. Der Text sollte die Szene und das Verhalten der Figur klar beschreiben, z. B. "Zwei Personen diskutieren über ihre Arbeit an einem Kaffeetisch im Freien". Nach der Erstellung verwendet MultiTalk die L-RoPE-Technologie, um sicherzustellen, dass jeder Audiokanal mit dem entsprechenden Charakter verbunden ist und dass die Lippenbewegungen mit der Stimme synchronisiert werden. - Unterstützung von Cartoon-Charakteren
Mit Hilfe von Referenzbildern von Zeichentrickfiguren (z. B. Nick und Judy im Disney-Stil) erzeugt MultiTalk Dialoge oder Gesangsvideos im Zeichentrickstil. Beispielanforderung: "Nick und Judy singen in einem gemütlichen Zimmer". - interaktive Steuerung
Steuern Sie die Aktionen der Figuren mit Textaufforderungen. Geben Sie zum Beispiel "Frau trinkt Kaffee, Mann schaut aufs Handy" ein und MultiTalk erzeugt eine dynamische Szene. Die Aufforderungen sollten prägnant, aber spezifisch sein und vage Beschreibungen vermeiden. - Auswahl der Auflösung
ausnutzen--size multitalk-720Erzeugt HD-Videos, die für die Anzeige auf hochwertigen Anzeigegeräten geeignet sind. Niedrige Auflösung 480p Ideal für schnelle Tests oder Geräte mit geringer Leistung.
caveat
- Hardware-VoraussetzungCUDA-Grafikprozessoren mit mindestens 12 GB RAM werden empfohlen; bei Geräten mit geringem RAM müssen Optimierungsparameter aktiviert werden.
- AudioqualitätDer Ton muss frei von auffälligem Rauschen sein, um einen lippensynchronen Effekt zu gewährleisten.
- LizenzbeschränkungenDer generierte Inhalt ist nur für den akademischen Gebrauch bestimmt, eine kommerzielle Nutzung ist untersagt.
Anwendungsszenario
- akademische Forschung
Forscher können MultiTalk nutzen, um audiogesteuerte Videogenerierungstechniken zu erforschen und die Wirksamkeit innovativer Ansätze wie L-RoPE in Szenarien mit mehreren Charakteren zu testen. - Pädagogische Demonstrationen
Lehrer können Videos mit Dialogen von Zeichentrickfiguren für den Unterricht im Klassenzimmer oder für Online-Kurse erstellen, um Spaß und Interaktivität hinzuzufügen. - Erstellung virtueller Inhalte
Inhaltsersteller können schnell Multiplayer-Dialoge oder Gesangsvideos für kurze Videoplattformen oder virtuelle Charakterpräsentationen erstellen. - Technologieentwicklung
Auf der Grundlage des Open-Source-Codes von MultiTalk können Entwickler szenariospezifische Tools zur Videoerstellung für virtuelle Meetings oder digitale Projekte mit Menschen anpassen.
QA
- Welche Audioformate werden von MultiTalk unterstützt?
Unterstützt Audio im WAV-Format mit einer empfohlenen Abtastrate von 16 kHz, um eine optimale Lippensynchronisation zu gewährleisten. - Wie behebe ich einen Audio-zu-Zeichen-Bindungsfehler?
MultiTalk verwendet die L-RoPE-Technologie zur automatischen Lösung von Bindungsproblemen, indem es dieselben Etiketten für Audio und Video einbettet. So wird sichergestellt, dass das eingehende Audio und das Referenzbild übereinstimmen. - Wie lange dauert es, ein Video zu erstellen?
Hängt von der Hardware und der Videolänge ab. Kurze Videos (10 Sekunden) dauern auf einer leistungsstarken GPU etwa 1-2 Minuten, längere Videos können 5-10 Minuten dauern. - Unterstützt es die Generierung in Echtzeit?
Die aktuelle Version unterstützt keine Echtzeitgenerierung und erfordert eine Offline-Verarbeitung. Zukünftige Versionen können die Generierung mit geringer Latenz optimieren. - Wie kann die Leistung von Geräten mit geringem Grafikspeicher optimiert werden?
ausnutzen--num_persistent_param_in_dit 0im Gesang antworten--use_teacacheDadurch wird der Speicherbedarf der Grafikkarte verringert.