

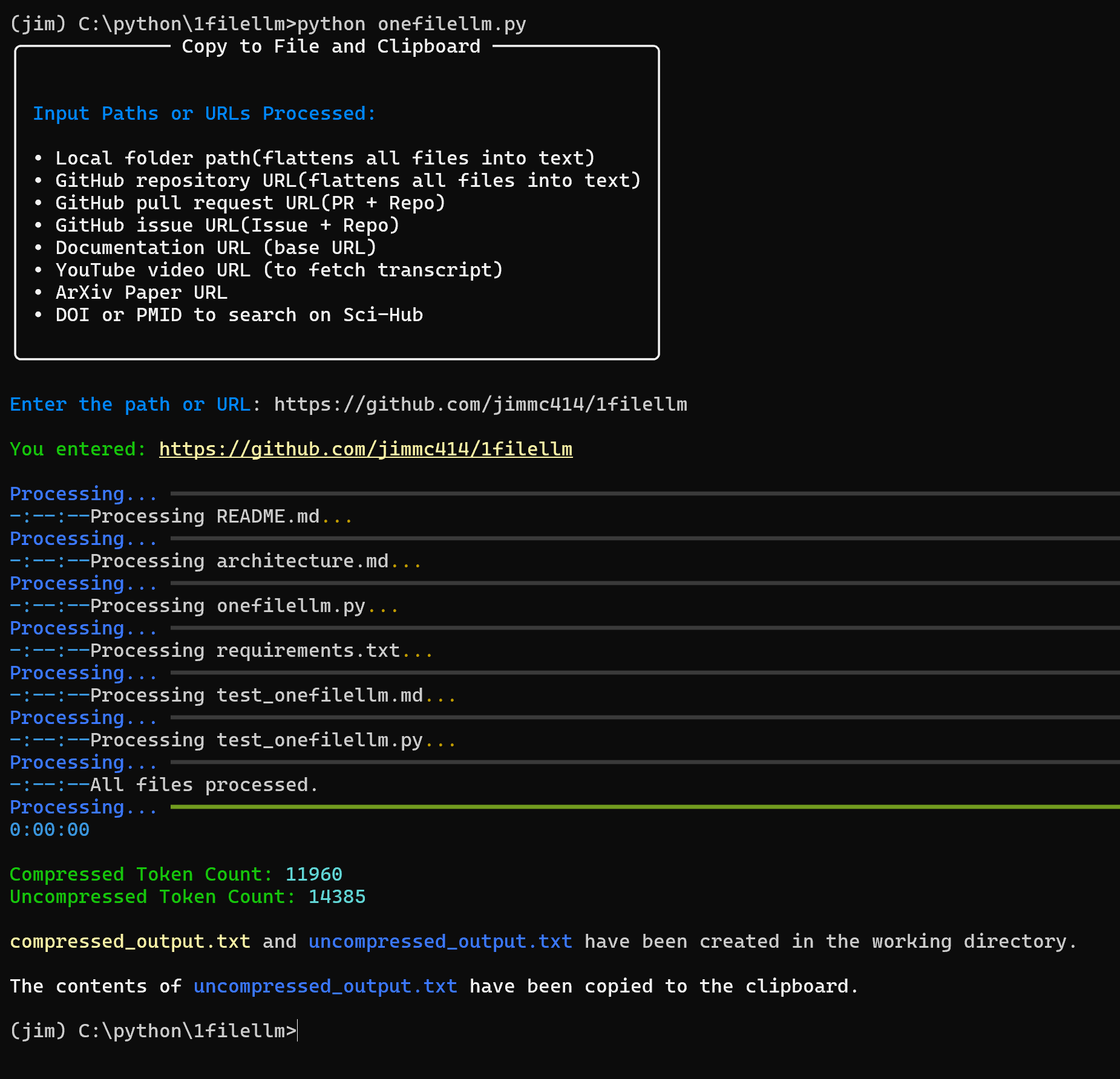
综合介绍 OneFileLLM 是一个开源命令行工具,旨在将多种数据源整合成单一文本文件,方便输入大语言模型(LLM)。它支持处理 GitHub 仓库、ArXiv 论文、YouTube 视频转录、网页内容、Sci-Hub 论文和本地文件,自...
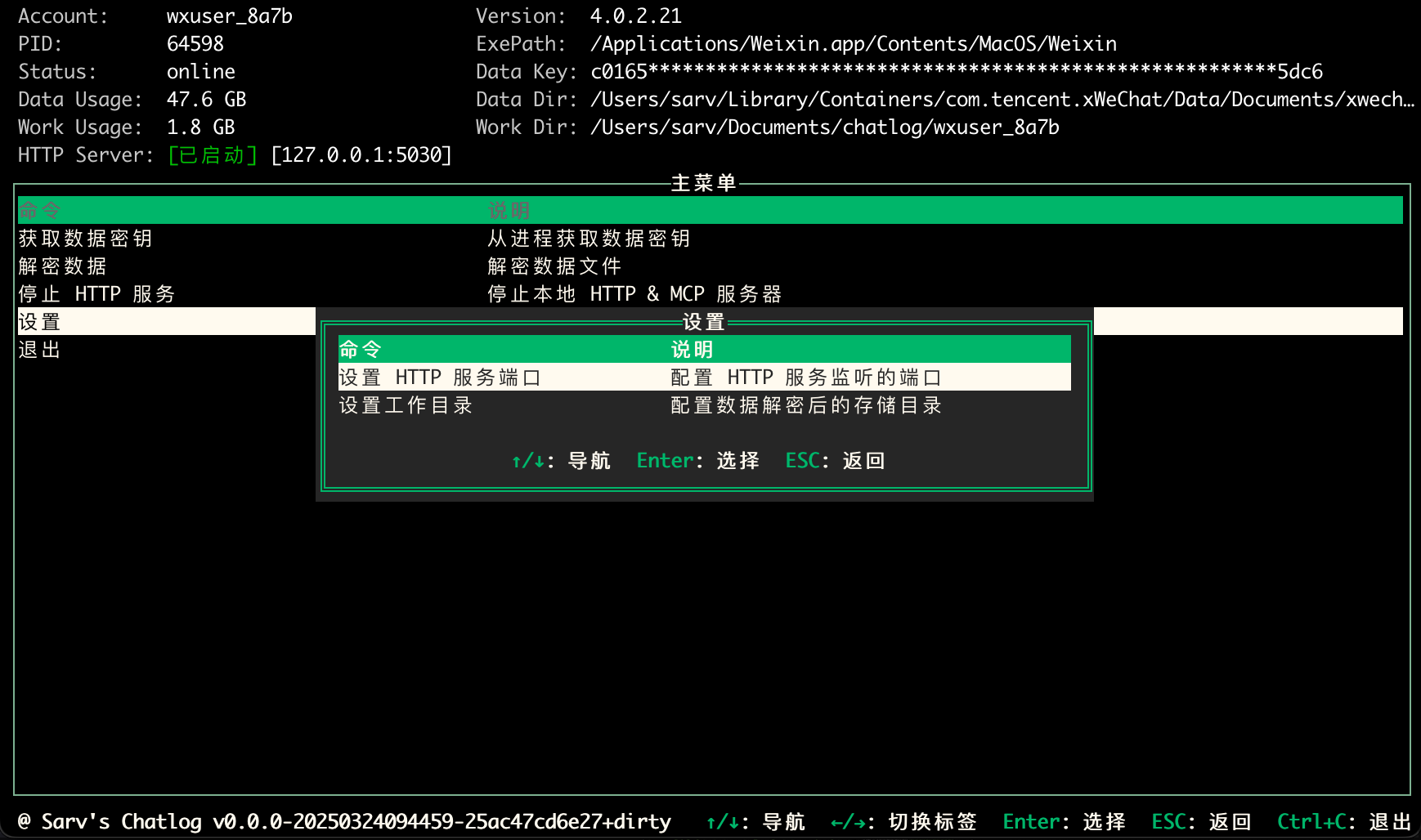
Allgemeine Einführung Chatlog ist ein Open-Source-Tool, das sich auf die Extraktion und Abfrage von Chat-Protokollen aus der lokalen Datenbank von WeChat konzentriert. Es unterstützt die WeChat-Versionen 3.x und 4.0, die Windows- und macOS-Systeme abdecken. Benutzer können die Befehlszeile, die Terminalschnittstelle oder die HTTP-API-Operation verwenden, um Chat-Protokolle, Kontaktinformationen und...

Umfassende Einführung Das vielseitige OCR-Programm ist ein Open-Source-Tool für die optische Zeichenerkennung (OCR), das für die Verarbeitung komplexer akademischer und pädagogischer Dokumente entwickelt wurde. Es kann Text, Tabellen, mathematische Formeln, Diagramme und Schemata aus PDFs, Bildern und anderen Dokumenten extrahieren und eine Struktur erzeugen, die für das Training von maschinellem Lernen geeignet ist...
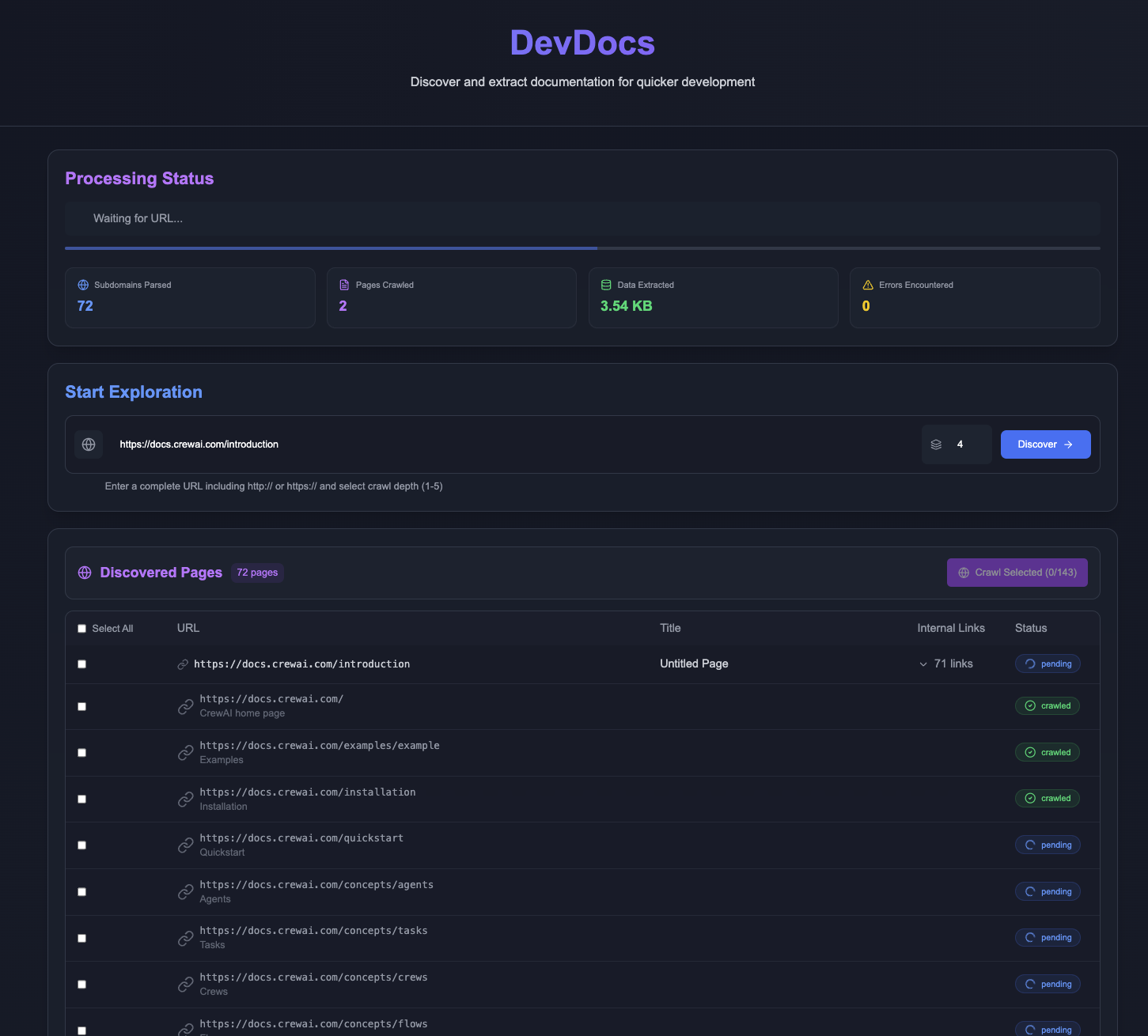
Allgemeine Einführung DevDocs ist ein völlig kostenloses Open-Source-Tool, das vom CyberAGI-Team entwickelt und auf GitHub gehostet wird. Es wurde für Programmierer und Softwareentwickler entwickelt und geht von der URL eines technischen Dokuments aus, durchsucht automatisch die relevanten Seiten und organisiert sie in prägnanten Markdown- oder JSON-Dateien. Es hat eine eingebaute...
Umfassende Einführung Es analysiert automatisch das Layout von PDF-Dokumenten, identifiziert Text, Titel, Bilder, Tabellen, Formeln und andere Elemente auf der Seite und bestimmt ihre richtige Reihenfolge. Das Tool unterstützt OCR-Funktionalität, Sie können gescannte PDF in durchsuchbaren Text umwandeln. Es läuft auf Docker , bietet zwei Modelle: visuelles Modell (Vis...
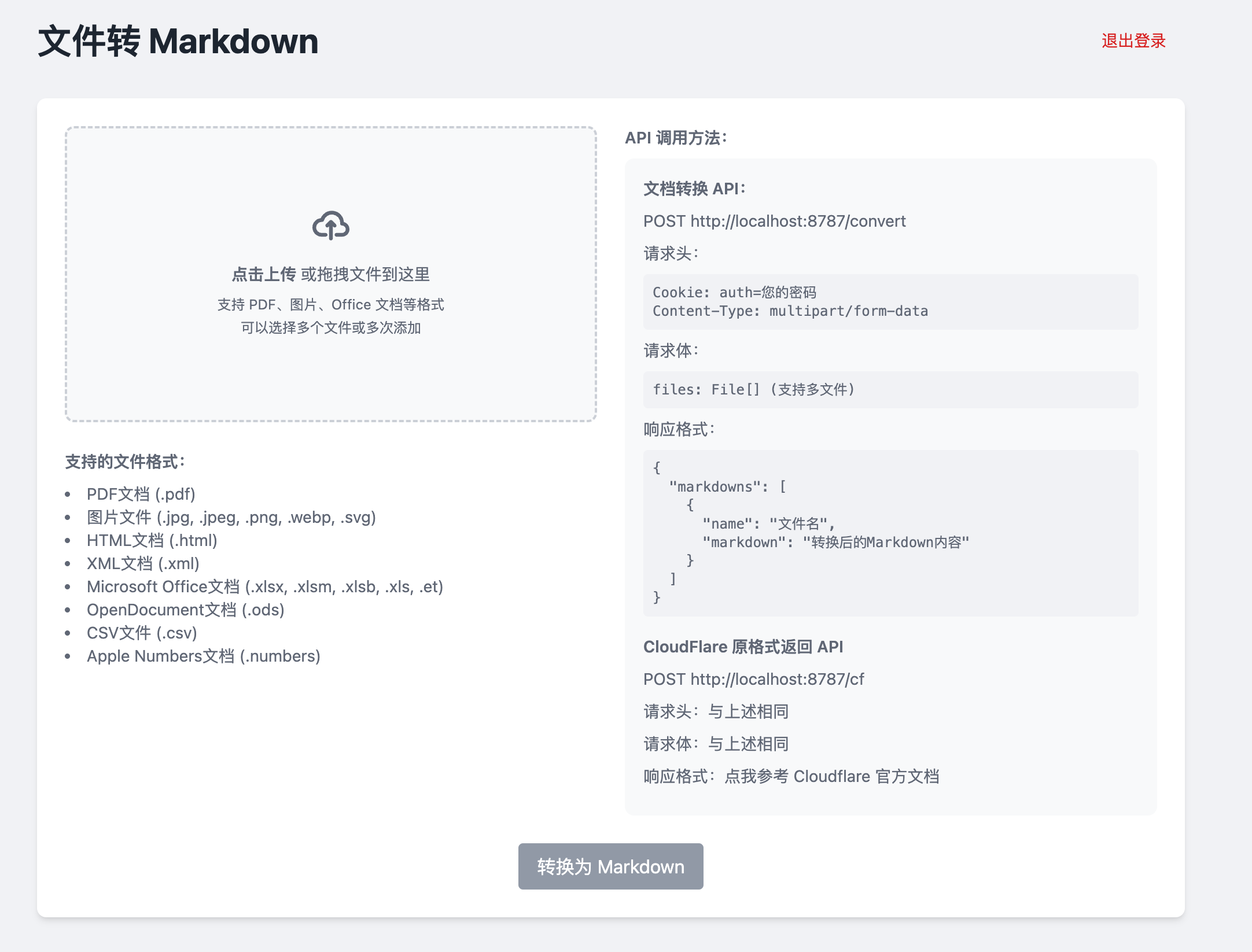
综合介绍 serverless-markdown-convertor 是一个免费的开源工具,基于 Cloudflare Worker 和 Workers AI 开发,能将多种文件转换为 Markdown 格式。它支持 PDF、图片、Offi...
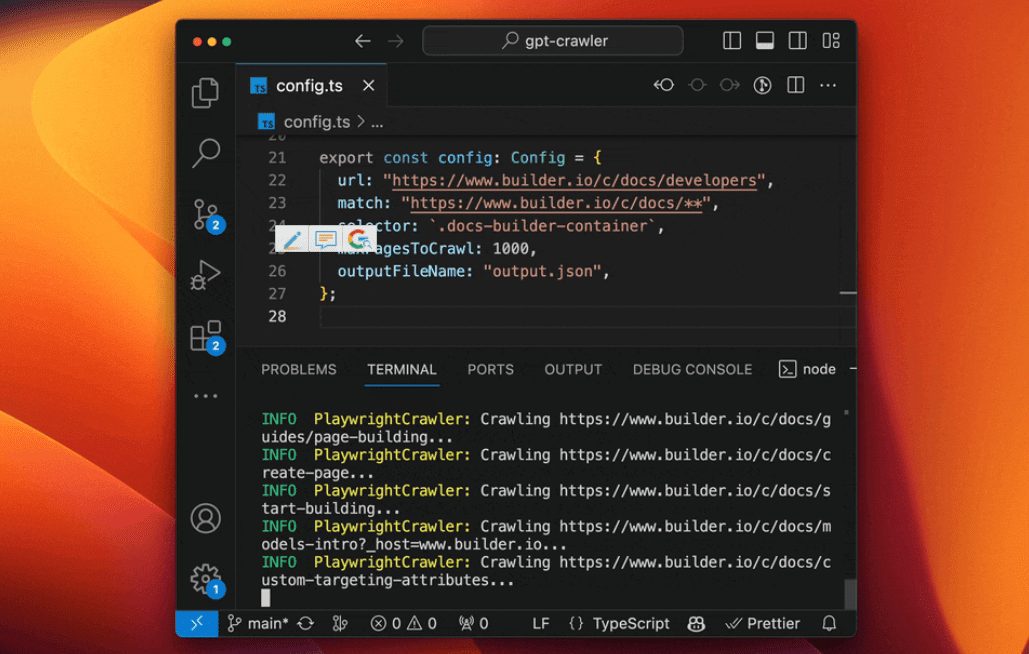
综合介绍 GPT-Crawler 是由 BuilderIO 团队开发的一个开源工具,托管在 GitHub 上。它通过输入一个或多个网站 URL,爬取页面内容,生成结构化的知识文件(output.json),用于创建自定义 GPT 或 AI ...
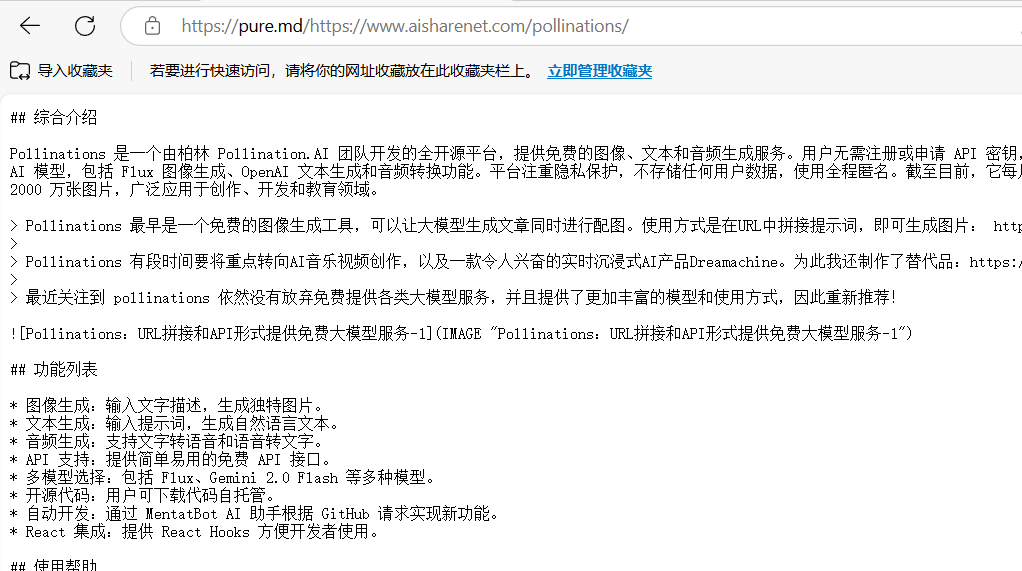
Allgemeine Einführung pure.md ist ein Tool für KI-Agenten und Entwickler, das sich auf die schnelle Umwandlung von Webinhalten oder Dateien in das Markdown-Format konzentriert. Es umgeht Anti-Crawler-Beschränkungen durch Proxy-Dienste, extrahiert die Kerndaten einer Webseite und gibt eine übersichtliche Markdown-Datei aus. Ob es sich um eine dynamische Webseite, eine PDF-Datei...
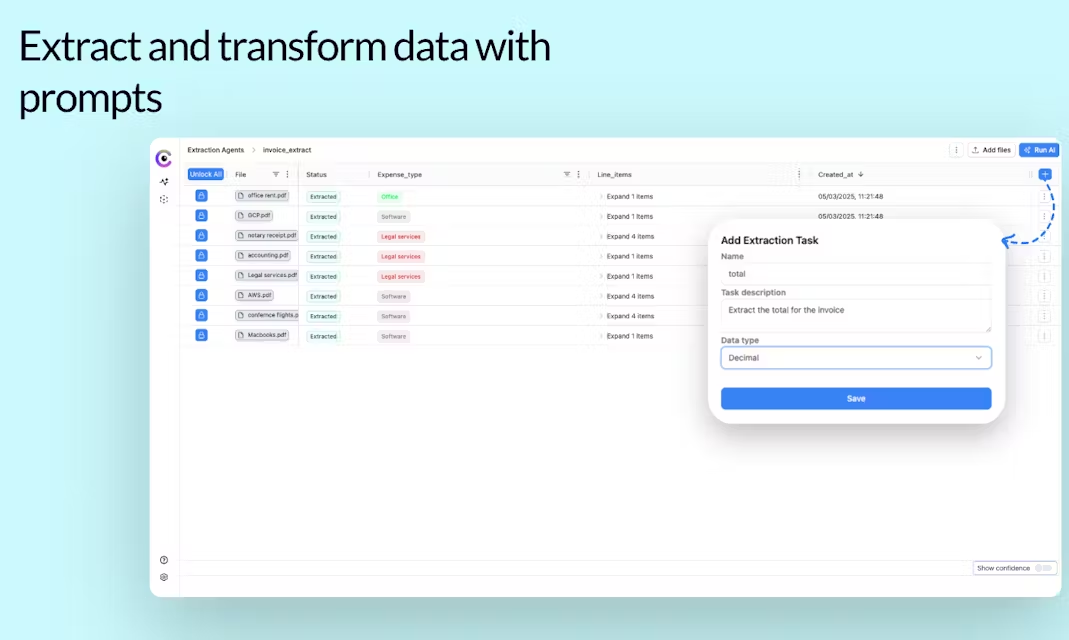
Allgemeine Einführung Cloudsquid ist ein 2023 in Berlin, Deutschland, gegründetes Unternehmen, das sich auf die Vereinfachung der Dokumentenverarbeitung mit künstlicher Intelligenz konzentriert. Das Kernprodukt ist eine Online-Plattform zur Datenextraktion, die es Nutzern ermöglicht, PDFs, Bilder, Audio, Video usw. hochzuladen und einfach anzugeben, welche Daten extrahiert werden sollen, z. B. "Finde...

Allgemeine Einführung PDF Craft ist ein Open-Source-Tool, mit dem PDFs von Büchern gescannt und in das Markdown-Format konvertiert werden können. Es wird von oomol-lab entwickelt und auf GitHub gehostet für Benutzer, die ihre E-Books organisieren möchten. Das Tool läuft über ein lokales KI-Modell, ohne dass eine Internetverbindung erforderlich ist, was sowohl die Privatsphäre als auch den Platz...
Umfassende Einführung Supametas.AI ist eine Datenverarbeitungsplattform, die sich darauf spezialisiert hat, das Durcheinander von Webseiten, Dokumenten, Audio und Video in strukturierte Daten umzuwandeln, die KI nutzen kann. Sie unterstützt das Sammeln von Daten aus verschiedenen Quellen, einschließlich Weblinks, APIs, lokalen Dateien usw., und exportiert sie dann in das JSON- oder Markdown-Format. Plattform...

综合介绍 MarkPDFDown 是一个开源工具。它利用多模态大语言模型,把 PDF 文件转为 Markdown 格式。开发者是 GitHub 用户 jorben。这个工具的目标很简单:让 PDF 文档变得更易编辑和分享。它能识别文档中的标...

综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 256M 参数,却是全球最小的 VLM。...

Das Ziel der Tabellenerkennung besteht darin, Tabellen in Bildern zu analysieren, Tabellenstrukturen und Zellenpositionen genau zu identifizieren und sie in strukturierte Tabellenformate (z. B. HTML) zu reduzieren. Im heutigen Informationszeitalter liegt eine große Menge wichtiger tabellarischer Daten immer noch in einem unstrukturierten Zustand vor (z. B. Bilder von Informationsstatistiken in gescannten Dokumenten, pd...

In der langen Geschichte der menschlichen Zivilisation hat jeder Sprung in der Art und Weise, wie Informationen erworben und ausgewertet werden, den sozialen Fortschritt entscheidend vorangetrieben. Von den antiken Hieroglyphen über den tragbaren Papyrus bis hin zur späteren Entwicklung des Buchdrucks und der heutigen digitalen Welle hat jede technologische Innovation die Weitergabe von menschlichem Wissen erheblich erweitert...
综合介绍 Firecrawl MCP Server 是由 MendableAI 开发的一款开源工具,基于 Model Context Protocol (MCP) 协议实现,与 Firecrawl API 集成,提供强大的网页抓取和数据提取...
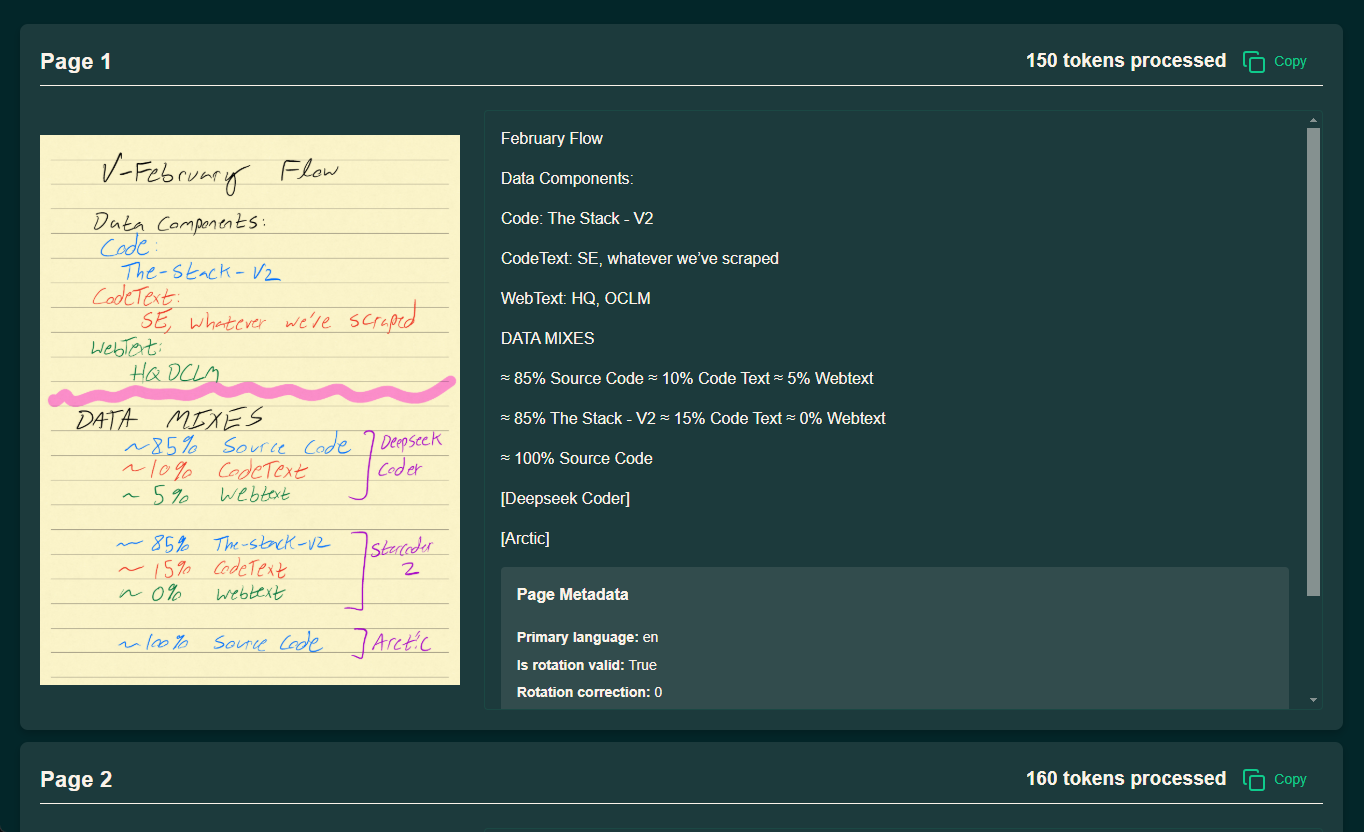
综合介绍 olmOCR 是由 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具,专注于将 PDF 文件转换为线性化文本,特别适合用于大规模语言模...
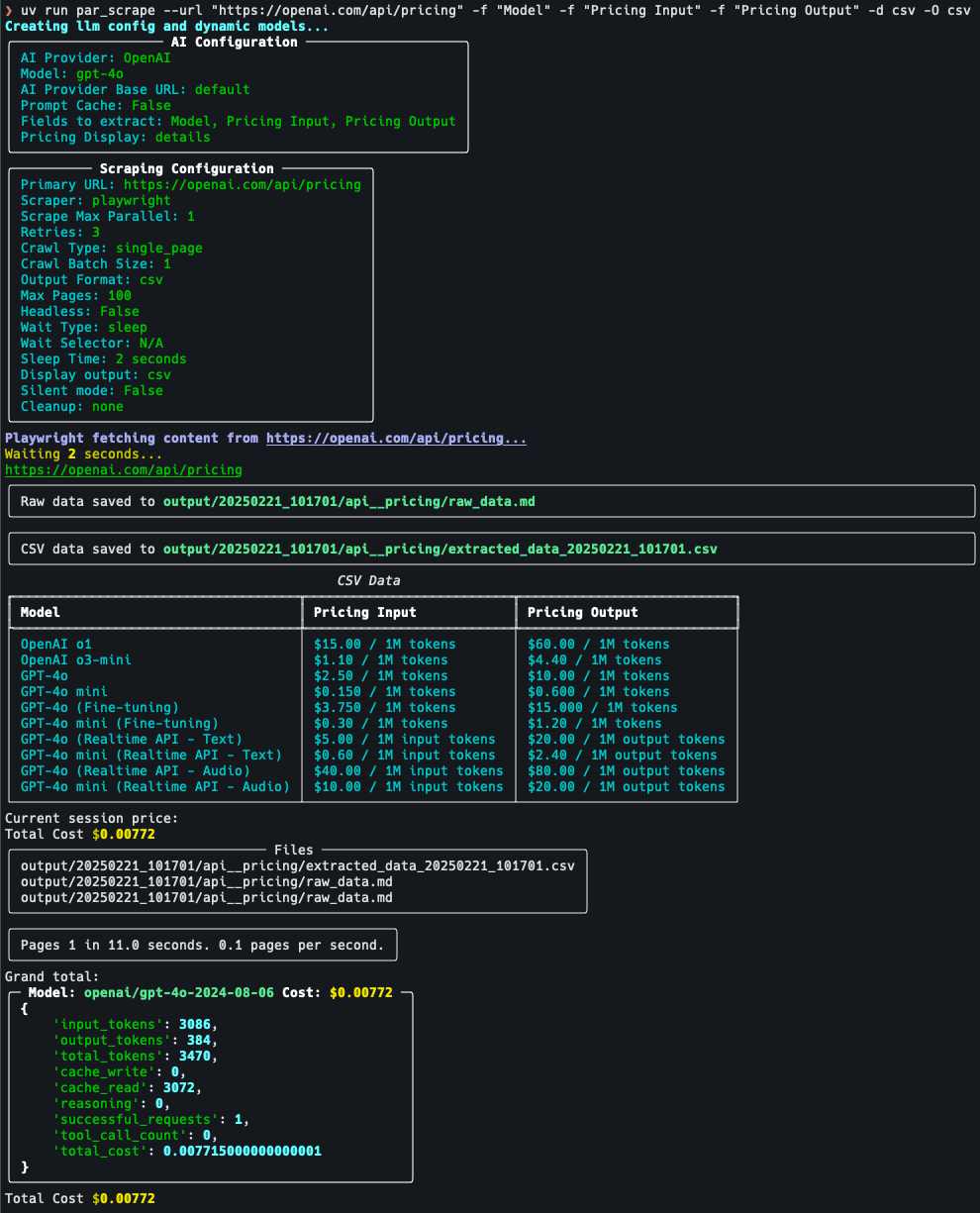
综合介绍 par_scrape 是一个基于 Python 的开源网页爬虫工具,由开发者 Paul Robello 在 GitHub 上推出,旨在帮助用户从网页中智能提取数据。它整合了 Selenium 和 Playwright 两种强大的浏...

综合介绍 PDF-Extract-Kit 是一个由 OpenDataLab 团队开发的开源项目,专注于从复杂多样的 PDF 文档中高效提取高质量内容。它集成了先进的文档解析技术,支持布局检测、公式识别、表格提取和 OCR 等功能,适用于.....
