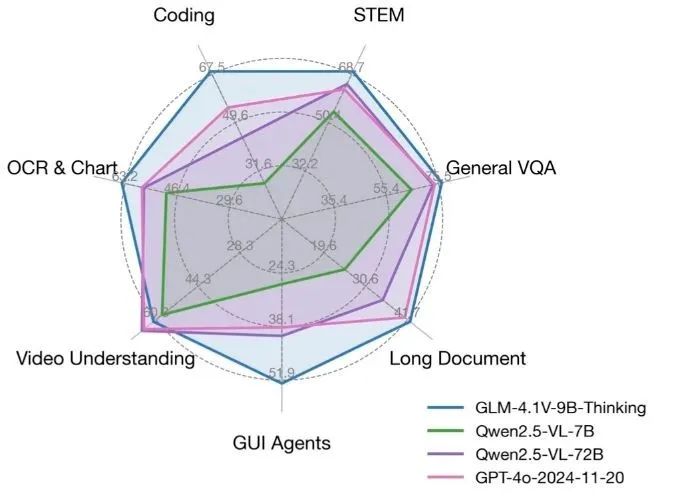
GLM-4.1V-Thinking ist ein quelloffenes visuelles Sprachmodell, das vom KEG-Labor (THUDM) der Tsinghua-Universität entwickelt wurde und sich auf multimodale Argumentationsfähigkeiten konzentriert. Basierend auf dem Basismodell GLM-4-9B-0414 verbessert GLM-4.1V-Thinking die Verarbeitungsfähigkeit komplexer Aufgaben durch Verstärkungslernen und einen "chain-of-thinking"-Schlussfolgermechanismus erheblich. Es unterstützt 64k ultralange Kontexte, 4K hochauflösende Bildverarbeitung, ist kompatibel mit beliebigen Bildseitenverhältnissen und bietet zweisprachige Unterstützung für Englisch und Chinesisch. Das Modell schneidet bei Aufgaben wie Mathematik, Code, Verstehen langer Dokumente und Video-Reasoning hervorragend ab und übertrifft in einigen Bewertungen sogar GPT-4o. Der Code und das Modell stehen auf GitHub unter der MIT-Lizenz zur Verfügung und sind für die kommerzielle Nutzung durch Entwickler, Forscher und Unternehmen frei.
Funktionsliste
- Unterstützung für sehr lange 64k-Kontexte zur Bearbeitung langer Dokumente oder komplexer Dialoge.
- Verarbeitet hochauflösende 4K-Bilder und unterstützt beliebige Seitenverhältnisse.
- Bietet zweisprachige Unterstützung in Englisch und Chinesisch, geeignet für mehrsprachige Szenarien.
- Integration von Mechanismen der "Gedankenkette", um die Genauigkeit bei Mathematik-, Code- und Logikaufgaben zu verbessern.
- Unterstützt Video-Reasoning, um Videoinhalte zu analysieren und damit verbundene Fragen zu beantworten.
- Open-Source-Code und -Modelle, basierend auf der MIT-Lizenz, die eine kostenlose kommerzielle Nutzung ermöglicht.
- Die Online-Demos von Hugging Face und ModelScope ermöglichen ein schnelles Kennenlernen der Modellierungsfunktionen.
- Unterstützt die Ausführung auf einer einzigen 3090-Grafikkarte für ressourcenbeschränkte Entwicklungsumgebungen.
Hilfe verwenden
Installation und Einsatz
GLM-4.1V-Thinking bietet vollständige Code- und Modelldateien mit einem einfachen Bereitstellungsprozess für Entwickler, der lokal oder auf einem Server ausgeführt werden kann. Im Folgenden werden die Installations- und Verwendungsschritte detailliert beschrieben:
1. die Vorbereitung der Umwelt
Es muss in einer GPU-fähigen Umgebung ausgeführt werden; eine NVIDIA-Grafikkarte (wie die RTX 3090) wird empfohlen. Stellen Sie sicher, dass Python 3.8 oder höher sowie PyTorch installiert ist. Hier sind die Schritte zur Installation der Abhängigkeiten:
pip install git+https://github.com/huggingface/transformers.git
pip install torch torchvision torchaudio
pip install -r requirements.txt
Wenn eine Feinabstimmung des Modells erforderlich ist, siehe finetune/README.md Datei unter Verwendung des LLaMA-Factory-Toolkits. Bei der Feinabstimmung wird empfohlen, die Strategie Zero3 zu verwenden, um die Stabilität des Trainings zu gewährleisten und das Problem des Nullpunktverlusts zu vermeiden, das sich bei Zero2 ergeben kann.
2. das Modell herunterladen
Das GLM-4.1V-Thinking-Modell kann von den Hugging Face- oder GitHub-Repositories heruntergeladen werden. Führen Sie den folgenden Code aus, um das Modell zu laden:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Modell-Unterstützung bfloat16 Format, geringerer Speicherbedarf und geeignet für den Betrieb mit nur einer GPU.
3) Einzelbildbetrachtung
GLM-4.1V-Thinking unterstützt Denkaufgaben mit Bildeingabe. Unten sehen Sie ein einfaches Beispiel für eine Bildbeschreibung:
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/sample_image.png"},
{"type": "text", "text": "描述这张图片"}
]
}
]
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
Oberbefehlshaber (Militär) sample_image.png Ersetzen Sie durch die tatsächliche Bild-URL oder den lokalen Pfad. Das Modell analysiert das Bild und erstellt eine detaillierte Beschreibung.
4) Video-Argumentation
GLM-4.1V-Thinking unterstützt die Analyse von Videoinhalten. Benutzer können eine Videodatei über einen Beispielcode in einem GitHub-Repository oder einer Online-Demoplattform (z. B. Hugging Face) hochladen, und das Modell wird das Video analysieren und Fragen dazu beantworten. Wenn Sie beispielsweise ein Video eines Meetings hochladen und die Frage "Welche Themen wurden in dem Video besprochen" stellen, extrahiert das Modell die wichtigsten Informationen und generiert eine genaue Antwort.
5. langes Verstehen von Dokumenten
Das Modell unterstützt 64k lange Kontexte, was ideal für die Verarbeitung langer Dokumente ist. Die Benutzer können Text in das Modell eingeben und nach bestimmten Inhalten fragen oder die wichtigsten Punkte des Dokuments zusammenfassen. Geben Sie beispielsweise eine 50-seitige wissenschaftliche Abhandlung ein und fragen Sie "Was sind die wichtigsten Schlussfolgerungen der Abhandlung?", und das Modell wird diese schnell extrahieren und zusammenfassen.
6. online Präsentation
Es ist kein lokaler Einsatz erforderlich und kann direkt über eine von Hugging Face oder ModelScope bereitgestellte Online-Demo ausprobiert werden. Besuchen Sie die unten stehenden Links:
- Umarmung Gesicht Demo:
https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking - ModelScope Demo:
https://modelscope.cn/models/THUDM/GLM-4.1V-9B-Thinking
Die Benutzer können Bilder und Videos hochladen oder Text eingeben, um die Argumentation des Modells schnell zu testen.
7. die Feinabstimmung des Modells
Entwickler können das LLaMA-Factory-Toolkit zur Feinabstimmung des Modells verwenden, um es an bestimmte Aufgaben anzupassen. Die Konfigurationsdatei für die Feinabstimmung befindet sich im Verzeichnis configs/lora.yamlführen Sie den folgenden Befehl aus, um die Feinabstimmung zu starten:
cd finetune
python finetune.py data/YourDataset/ THUDM/GLM-4-9B-0414 configs/lora.yaml
Achten Sie darauf, dass der Datensatz korrekt formatiert ist, empfohlen wird das JSON-Format. Nach der Feinabstimmung kann das Modell besser an domänenspezifische Aufgaben angepasst werden, z. B. an die medizinische Bildanalyse oder die Verarbeitung juristischer Dokumente.
Featured Function Bedienung
- KettenreaktionDas Modell zerlegt komplexe Probleme durch einen "chain of thought"-Mechanismus. Bei einer Matheaufgabe beispielsweise leitet das Modell die Antwort Schritt für Schritt ab, um ein genaues Ergebnis zu gewährleisten. Der Benutzer gibt ein: "Lösen Sie die quadratische Gleichung x² + 2x - 3 = 0" und das Modell gibt detaillierte Schritte zur Lösung der Aufgabe aus.
- multimodale UnterstützungBenutzer können sowohl Bilder als auch Text eingeben. Wenn Sie zum Beispiel einen Schaltplan hochladen und die Frage "Wie funktioniert der Schaltkreis?" stellen, kombiniert das Modell das Bild und die Frage, um eine detaillierte Erklärung zu erstellen.
- Chinesisch-Englisch zweisprachigDas Modell unterstützt gemischte chinesische und englische Eingaben, was für sprachübergreifende Szenarien geeignet ist. Geben Sie zum Beispiel eine Frage auf Chinesisch und eine Bildbeschreibung auf Englisch ein, und das Modell wird in der angegebenen Sprache antworten.
caveat
- Vergewissern Sie sich, dass die GPU über genügend Speicher verfügt, empfohlen werden mindestens 24 GB.
- Aktivieren Sie die YaRN-Konfiguration für die Verarbeitung langer Kontexte, um die Leistung der Konfigurationsdatei zu optimieren.
config.jsonden Nagel auf den Kopf treffen"rope_scaling": {"type": "yarn", "factor": 4.0}. - Die Geschwindigkeit der Modellinferenz ist hardwareabhängig, und die 3090-Grafikkarte ermöglicht eine Reaktion in Echtzeit.
Anwendungsszenario
- akademische Forschung
Forscher können GLM-4.1V-Thinking verwenden, um lange wissenschaftliche Arbeiten zu analysieren und die wichtigsten Schlussfolgerungen oder Zusammenfassungen zu extrahieren. Das Modell kann auch experimentelle Bilder verarbeiten und bei der Analyse von Datendiagrammen helfen. - Pädagogische Unterstützung
Die Schülerinnen und Schüler können Bilder von mathematischen Problemen oder naturwissenschaftlichen Experimenten hochladen, und das Modell liefert detaillierte Schritte zur Lösung der Probleme oder Erklärungen zu den Experimenten, die sich für das Selbststudium oder als Lehrmittel eignen. - Erstellung von Inhalten
Ersteller können Video- oder Bildmaterial eingeben, um beschreibenden Text oder kreative Skripte zu erstellen. Geben Sie zum Beispiel ein Reisevideo ein, um eine Beschreibung einer Attraktion zu erstellen. - Unternehmensanwendung
Unternehmen können das Modell zur Automatisierung von Dokumenten nutzen, z. B. zur Analyse von Vertragsbedingungen oder zur Erstellung von Berichten. Die zweisprachige Unterstützung in Englisch und Chinesisch macht es für multinationale Organisationen geeignet.
QA
- Welche Eingangsarten unterstützt GLM-4.1V-Thinking?
Das Modell unterstützt Bild-, Video- und Texteingaben und ist mit 4K-Bildern und 64k-Kontexten für multimodale Aufgaben kompatibel. - Ist leistungsstarke Hardware erforderlich?
Läuft mit einer einzigen RTX 3090-Grafikkarte, wobei 24 GB Videospeicher für flüssiges Denken empfohlen werden. - Wie stimme ich mein Modell ab?
Wenn Sie das LLaMA-Factory-Toolkit verwenden, finden Sie das GitHub-Repository für diefinetune/README.mdDatei, konfigurieren Sie dielora.yamlFeinabstimmung. - Sind die Modelle kostenlos?
Ja, das Modell ist quelloffen und basiert auf der MIT-Lizenz, die eine freie kommerzielle Nutzung erlaubt. - Wie kann ich das Modell erleben?
Testen Sie schnell die Modellfunktionalität, indem Sie Bilder oder Text über Hugging Face oder die Online-Demo von ModelScope hochladen.