
ReCall ist ein Open-Source-Framework, das entwickelt wurde, um Large Language Models (LLMs) für Tool-Aufrufe und Inferenzen durch Reinforcement Learning zu trainieren, ohne auf überwachte Daten angewiesen zu sein. Es ermöglicht den Modellen die autonome Nutzung und Kombination von externen Werkzeugen, wie z. B. Suche, Rechner usw., um komplexe Aufgaben zu lösen.ReCall unterstützt benutzerdefinierte Werkzeuge, die...
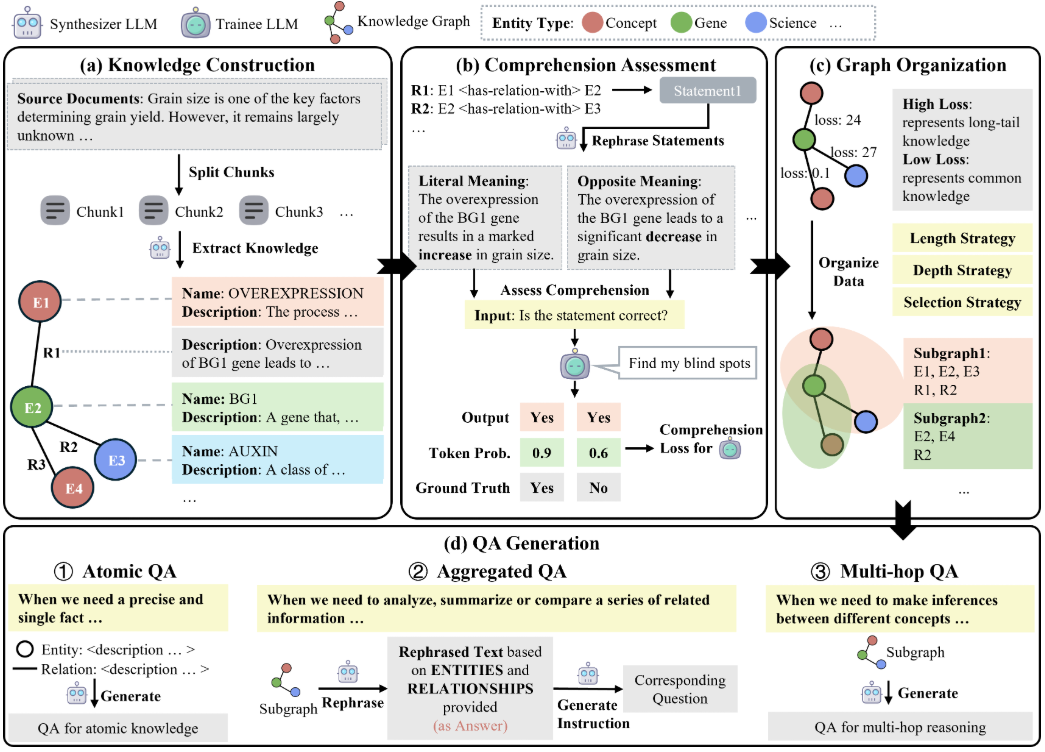
GraphGen ist ein Open-Source-Framework, das von OpenScienceLab, einem KI-Labor in Shanghai, entwickelt wurde und auf GitHub gehostet wird. Es konzentriert sich auf die Optimierung der überwachten Feinabstimmung von Large Language Models (LLMs), indem es die Erzeugung synthetischer Daten durch Wissensgraphen anleitet. Es konstruiert feinkörnige Wissensgraphen aus dem Ausgangstext, wobei der erwartete Kalibrierungsfehler...
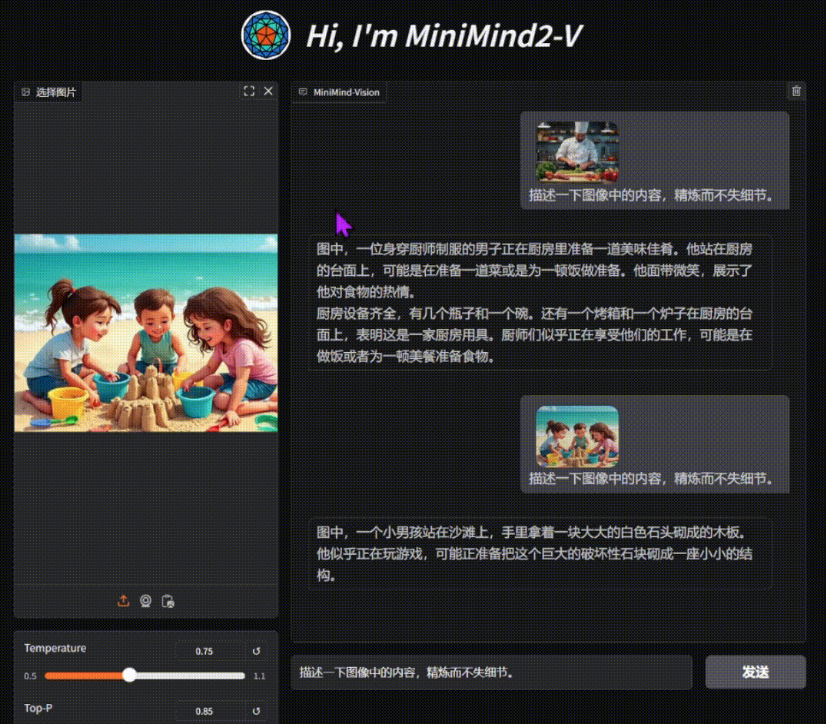
MiniMind-V ist ein Open-Source-Projekt, das auf GitHub gehostet wird und Benutzern helfen soll, ein leichtes visuelles Sprachmodell (VLM) mit nur 26 Millionen Parametern in weniger als einer Stunde zu trainieren. Es basiert auf dem MiniMind-Sprachmodell, dem neuen visuellen Codierer und dem Modul für die Merkmalsprojektion, der Unterstützung für die gemeinsame Verarbeitung von Bildern und Text. .....

DeepCoder-14B-Preview ist ein Open-Source-Modell zur Codegenerierung, das vom Agentica-Team entwickelt und auf der Hugging Face-Plattform veröffentlicht wurde. Es basiert auf DeepSeek-R1-Distilled-Qwen-14B, optimiert durch verteilte Reinforcement Learning (RL) Techniken...

WeClone ist ein Open-Source-Projekt, mit dem Nutzer personalisierte digitale Doppelgänger erstellen können, indem sie Chatprotokolle und Sprachnachrichten von WeChat mit großen Sprachmodellen und Sprachsynthesetechnologie kombinieren. Das Projekt kann die Chat-Gewohnheiten eines Nutzers analysieren, um das Modell zu trainieren, und kann außerdem mit einer kleinen Anzahl von Stimmproben realistische Stimmklone erzeugen. Letztendlich wird die digitale...
Search-R1 ist ein Open-Source-Projekt, das von PeterGriffinJin auf GitHub entwickelt wurde und auf dem veRL-Framework aufbaut. Es nutzt Techniken des Reinforcement Learning (RL), um ein großes Sprachmodell (LLM) zu trainieren, so dass das Modell selbstständig lernt, zu argumentieren und die Suchmaschine aufzurufen, um Probleme zu lösen. Projektunterstützung Qwen2....
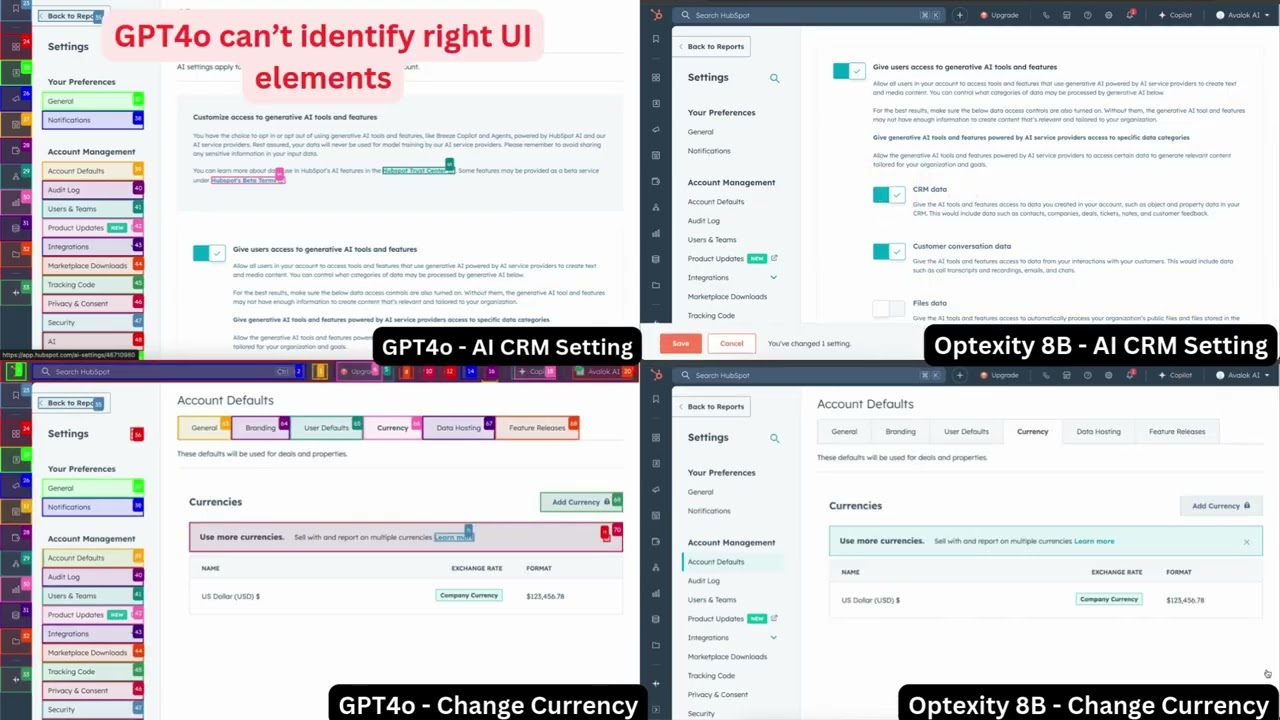
Optexity ist ein Open-Source-Projekt auf GitHub, das vom Optexity-Team entwickelt wurde. Sein Kern ist es, menschliche Demonstrationsdaten zu verwenden, um KI zu trainieren, um Computeraufgaben zu erledigen, insbesondere Webseitenoperationen. Das Projekt besteht aus drei Code-Bibliotheken: ComputerGYM, AgentAI und Playwright...

Bonsai ist ein von deepgrove-ai entwickeltes Open-Source-Sprachmodell mit einer Parametergröße von 500 Millionen, das ternäre Gewichte verwendet. Es basiert auf der Llama-Architektur und dem Mistral-Klassifikator-Design, mit linearen Schichten, die zur Unterstützung ternärer Gewichte angepasst wurden. Das Modell verwendet hauptsächlich ...

Second Me ist ein vom Mindverse-Team entwickeltes Open-Source-Projekt, mit dem Sie eine KI auf Ihrem Computer erstellen können, die wie ein "digitaler Doppelgänger" agiert, Ihre Sprachmuster und Gewohnheiten anhand Ihrer Worte und Erinnerungen lernt und zu einem intelligenten Assistenten wird, der Sie versteht. Das Beste daran ist, dass alle Daten im Computer bleiben...

Easy Dataset ist ein Open-Source-Tool, das speziell für die Feinabstimmung großer Modelle (LLMs) entwickelt wurde und auf GitHub gehostet wird. Es bietet eine einfach zu bedienende Schnittstelle, die es Benutzern ermöglicht, Dateien hochzuladen, Inhalte automatisch zu segmentieren, Fragen und Antworten zu generieren und schließlich strukturierte Datensätze auszugeben, die für die Feinabstimmung geeignet sind. Der Entwickler, Cona...

MM-EUREKA ist ein Open-Source-Projekt, das vom Shanghai Artificial Intelligence Laboratory der Shanghai Jiao Tong University und anderen Parteien entwickelt wurde. Es erweitert die Fähigkeiten des textuellen Reasonings auf multimodale Szenarien durch regelbasierte Verstärkungslerntechniken, um Modelle bei der Verarbeitung von Bild- und Textinformationen zu unterstützen. Das Hauptziel dieses Tools ist die Verbesserung der Modelle in...

AI Toolkit von Ostris ist ein Open-Source-KI-Toolkit, das sich auf die Unterstützung von Stable Diffusion und FLUX.1-Modellen für Trainings- und Bilderzeugungsaufgaben konzentriert. Das vom Entwickler Ostris erstellte und gepflegte Toolkit, das auf GitHub gehostet wird, zielt darauf ab, Forschern und Entwicklern flexible Modellierungsmöglichkeiten zu bieten...

X-R1 ist ein Reinforcement-Learning-Framework, das vom dhcode-cpp-Team auf GitHub zur Verfügung gestellt wird. Ziel ist es, Entwicklern ein kostengünstiges, effizientes Tool für das Training von Modellen auf Basis von End-to-End Reinforcement Learning zur Verfügung zu stellen. Inspiriert von DeepSeek-R1 und open-r1, konzentriert sich das Projekt auf den Aufbau eines einfachen...

OpenManus-RL ist ein Open-Source-Projekt, das gemeinsam von UIUC-Ulab und dem OpenManus-Team der MetaGPT-Community entwickelt wurde und auf GitHub gehostet wird. Das Projekt verbessert die Argumentations- und Entscheidungsfähigkeiten von Large Language Model (LLM)-Intelligenzen durch Reinforcement Learning (RL)-Techniken, basierend auf Deepseek-R1...
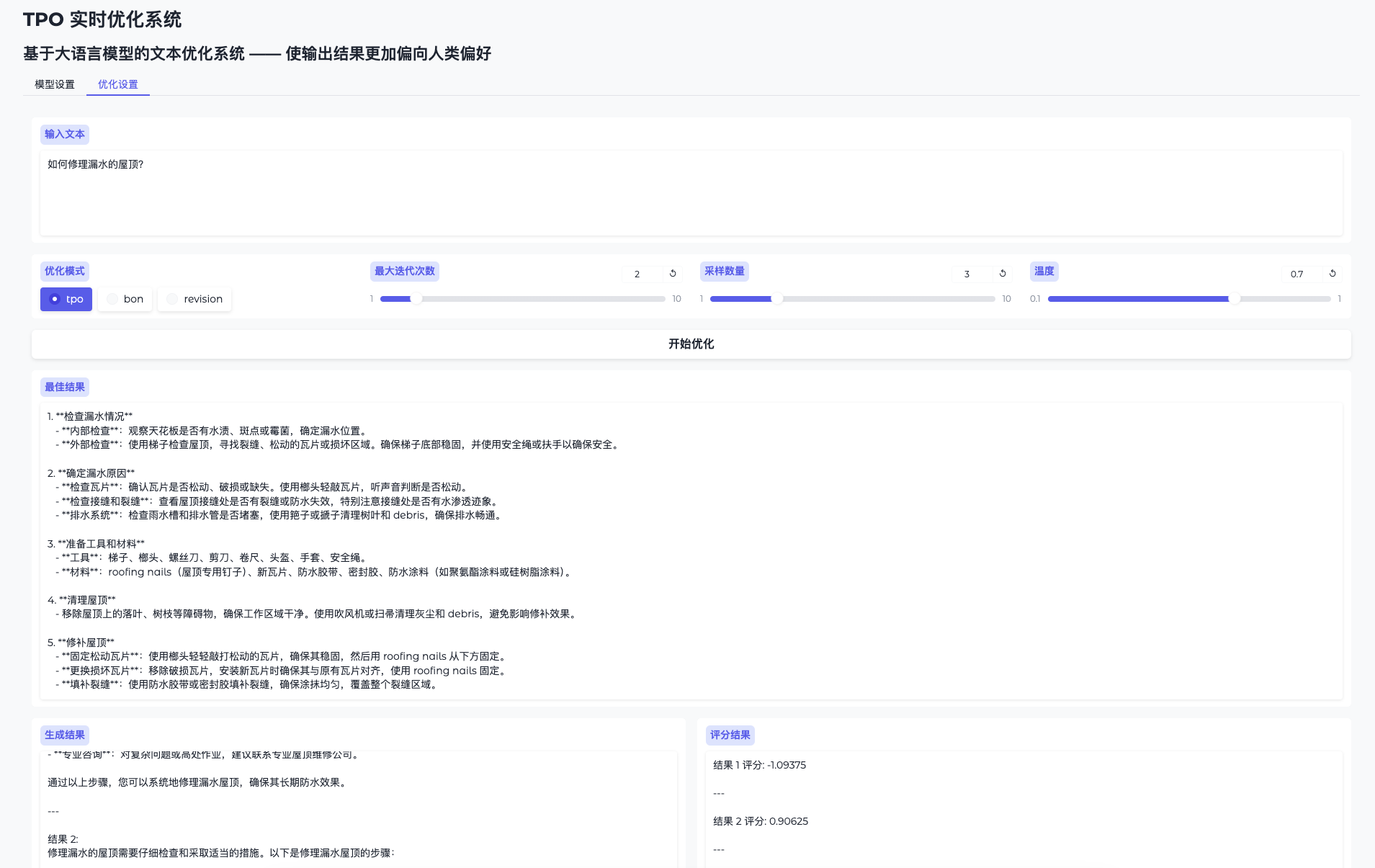
TPO-LLM-WebUI ist ein innovatives Projekt, das von Airmomo auf GitHub zur Verfügung gestellt wird und die Echtzeit-Optimierung von Large Language Models (LLMs) über eine intuitive Webschnittstelle ermöglicht. Es nutzt das TPO-Framework (Test-Time Prompt Optimisation) und verabschiedet sich damit von ...
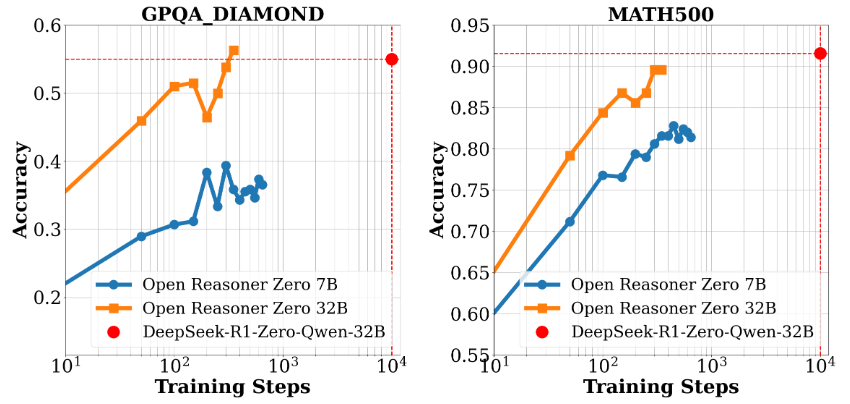
Open-Reasoner-Zero ist ein Open-Source-Projekt, das sich auf die Forschung im Bereich Reinforcement Learning (RL) konzentriert und vom Open-Reasoner-Zero-Team auf GitHub entwickelt wurde. Es zielt darauf ab, den Forschungsprozess im Bereich der künstlichen Intelligenz zu beschleunigen, indem es ein effizientes, skalierbares und einfach zu verwendendes Trainingsframework bereitstellt, insbesondere für...
Der chinesische DeepSeek-R1-Destillationsdatensatz ist ein chinesischer Open-Source-Datensatz mit 110.000 Daten, der zur Unterstützung der Forschung im Bereich des maschinellen Lernens und der Verarbeitung natürlicher Sprache entwickelt wurde. Der Datensatz wird von Liu Cong NLP-Team veröffentlicht, der Datensatz enthält nicht nur mathematische Daten, sondern auch eine große Anzahl von allgemeinen Arten von Daten, wie logische Argumentation, Xiaohongshu...

ColossalAI ist eine Open-Source-Plattform, die von HPC-AI Technologies entwickelt wurde, um eine effiziente und kostengünstige Lösung für das Training und die Inferenz von KI-Modellen in großem Maßstab zu bieten. Durch die Unterstützung mehrerer paralleler Strategien, heterogener Speicherverwaltung und Training mit gemischter Genauigkeit ist ColossalAI in der Lage, die Zeit für Modelltraining und Inferenz erheblich zu reduzieren und...

One Shot LoRA ist eine Plattform, die sich auf die Erstellung hochwertiger LoRA-Modelle aus Videos konzentriert. Benutzer können schnell und einfach hochwertige LoRA-Modelle aus Videos trainieren, ohne sich anzumelden oder private Daten zu speichern. Die Plattform unterstützt Hunyuan Video, FLUX und SDXL...

