在当前这轮 AI 浪潮中,AI 编程已然成为最拥挤的赛道之一。从 Cursor、Windsurf 到 v0 by Vercel,众多编程 Agent 如雨后春笋般涌现。它们崛起的背后,是 Anthropic Claude、OpenAI GPT、Google Gemini 等基础大模型在代码生成能力上的飞跃。
然而,截至 2025 年 6 月,这些 AI 编程工具的真实能力究竟如何?不同模型之间的代码生成质量存在多大差距?本次评测将通过一个统一的、真实的开发需求,对市面上主流的 AI 编程产品及其集成的模型进行一次横向对比,以期提供一个直观且具有参考价值的观察。
基准测试:一个名为“我的 MBTI 朋友圈”的 App
为了有效检验这些工具的综合能力,我们设计了一个复杂度适中的任务:生成一款名为“我的 MBTI AI 朋友圈”的应用的高保真设计原型。
该应用的核心概念是为用户提供情感陪伴。用户可以像写日记一样,在时间线上用卡片记录生活点滴,而系统内置的一系列拥有不同 MBTI 性格的 AI 朋友会根据各自的“人设”对用户的帖子进行回应。这个任务不仅考验 AI 对功能逻辑的理解,更对 UI 设计、代码结构和前端工程化能力提出了明确要求。
以下是本次评测使用的核心 Prompt:
我想开发一款名为“我的MBTI AI朋友圈”的中文情感陪伴 App,功能需求如下:
1. **核心功能**:用户可以通过卡片+时间线的交互方式,记录想法、计划、待办事项、情绪、链接等生活点滴。本质上,它首先是一款 AI 日记软件。
2. **AI 交互**:系统预设了一系列不同 MBTI 性格的 AI Agent。这些 Agent 会根据各自的性格特点,对用户的记录做出不同的回应。
3. **社交关系**:用户可以选择并关注不同的 AI Agent。
4. **分享功能**:用户可以分享自己的记录以及 AI Agent 的回应。
5. **核心价值**:通过 AI 的回应和分享功能,为用户提供情感陪伴。
现在,需要输出该 App 的高保真原型图。请通过以下方式完成所有界面的原型设计,并确保这些原型可以直接用于前端开发:
1. **用户体验分析**:分析 App 的主要功能和用户需求,确定核心交互逻辑。
2. **产品界面规划**:作为产品经理,定义关键界面,确保信息架构合理。
3. **高保真 UI 设计**:作为 UI 设计师,设计贴近真实 iOS/Android 设计规范的界面,使用现代化的 UI 元素,使其具有良好的视觉体验。
4. **HTML 原型实现**:使用 HTML + Tailwind CSS(或 Bootstrap)生成所有原型界面,并使用 FontAwesome(或其他开源 UI 组件库)让界面更加精美。代码文件需要拆分,保持结构清晰。
5. **文件结构要求**:
- 每个界面作为一个独立的 HTML 文件存放,例如 `home.html`、`profile.html`、`settings.html`。
- `index.html` 作为主入口,不直接写入所有界面的 HTML 代码,而是使用 `iframe` 的方式嵌入其他 HTML 页面,并将所有页面在 `index` 页面中平铺展示,而非通过链接跳转。
6. **真实感增强**:
- 界面尺寸模拟 iPhone 15 Pro,并进行圆角化处理。
- 使用真实的 UI 图片(可从 Unsplash、Pexels 等图库选取),而非占位符。
- 添加模拟 iOS 顶部状态栏和底部 TabBar 导航栏。
请按照以上要求,在 `design-trae-DeepSeekR1` 文件夹中生成完整的 HTML 代码。

这一 Prompt 的挑战性在于,它要求 AI 不仅是代码生成器,还要扮演产品经理、UI/UX 设计师和前端工程师三种角色。尤其是关于 iframe 平铺展示和独立文件结构的要求,是对 AI 项目级代码组织能力的直接考验。
第一轮:本地 IDE 集成工具评测
我们首先考察了在本地 IDE 中集成的 AI 编程插件,主要以 Cursor 和 Trae 为代表。这类工具的优势在于深度融入开发者已有的工作流。
Cursor
Cursor + Claude 3.5 Sonnet
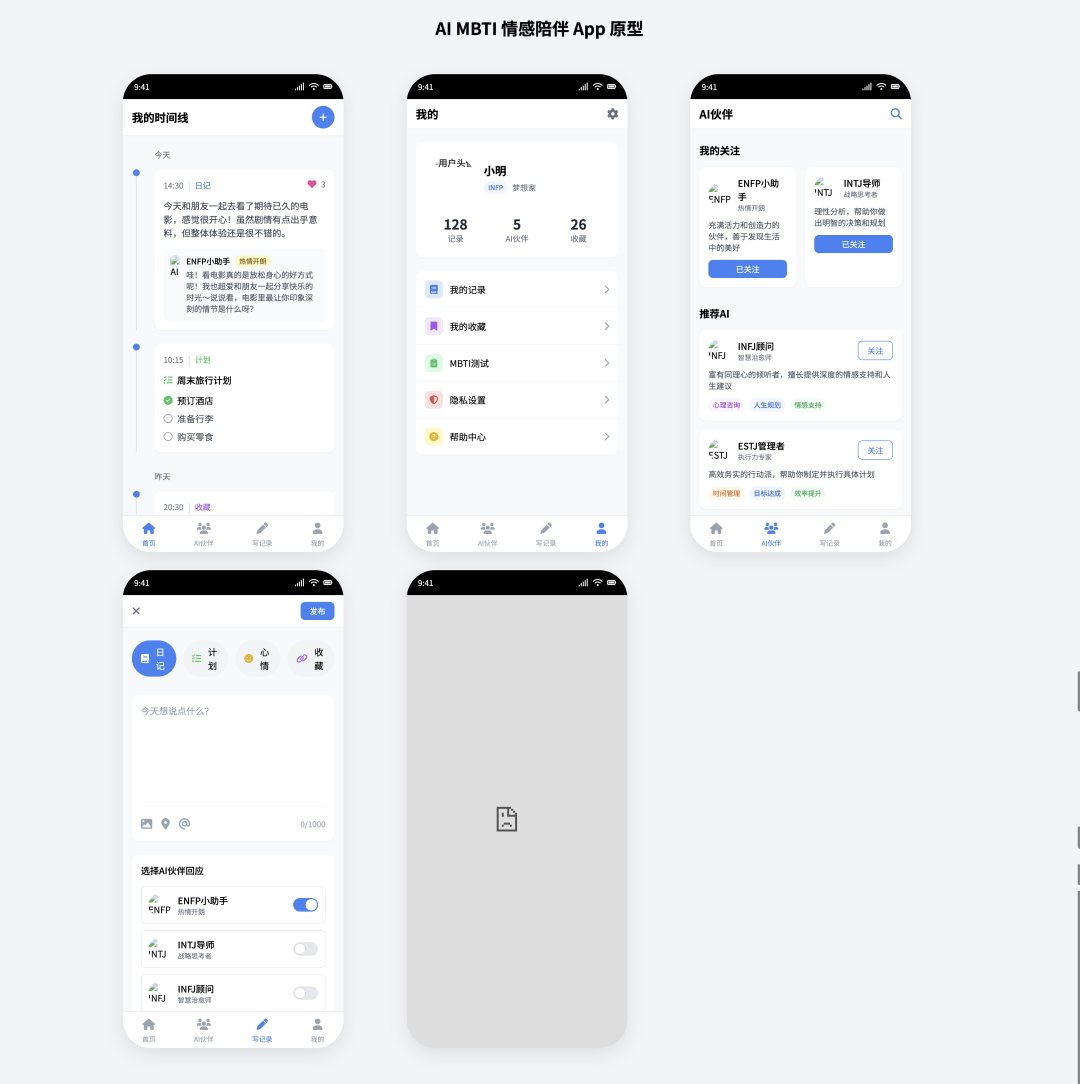
- 得分:60
- 评价:合格的毛坯房
Cursor 与 Claude 3.5 Sonnet 的组合基本完成了任务。功能层面,它准确实现了大部分核心需求,但生成了一个多余且无法打开的页面。UI 方面,界面骨架完整,但图标未能按要求从网络加载,整体风格朴素。虽然存在瑕疵,但作为初版原型,达到了及格线。
Cursor + Claude 4 Sonnet
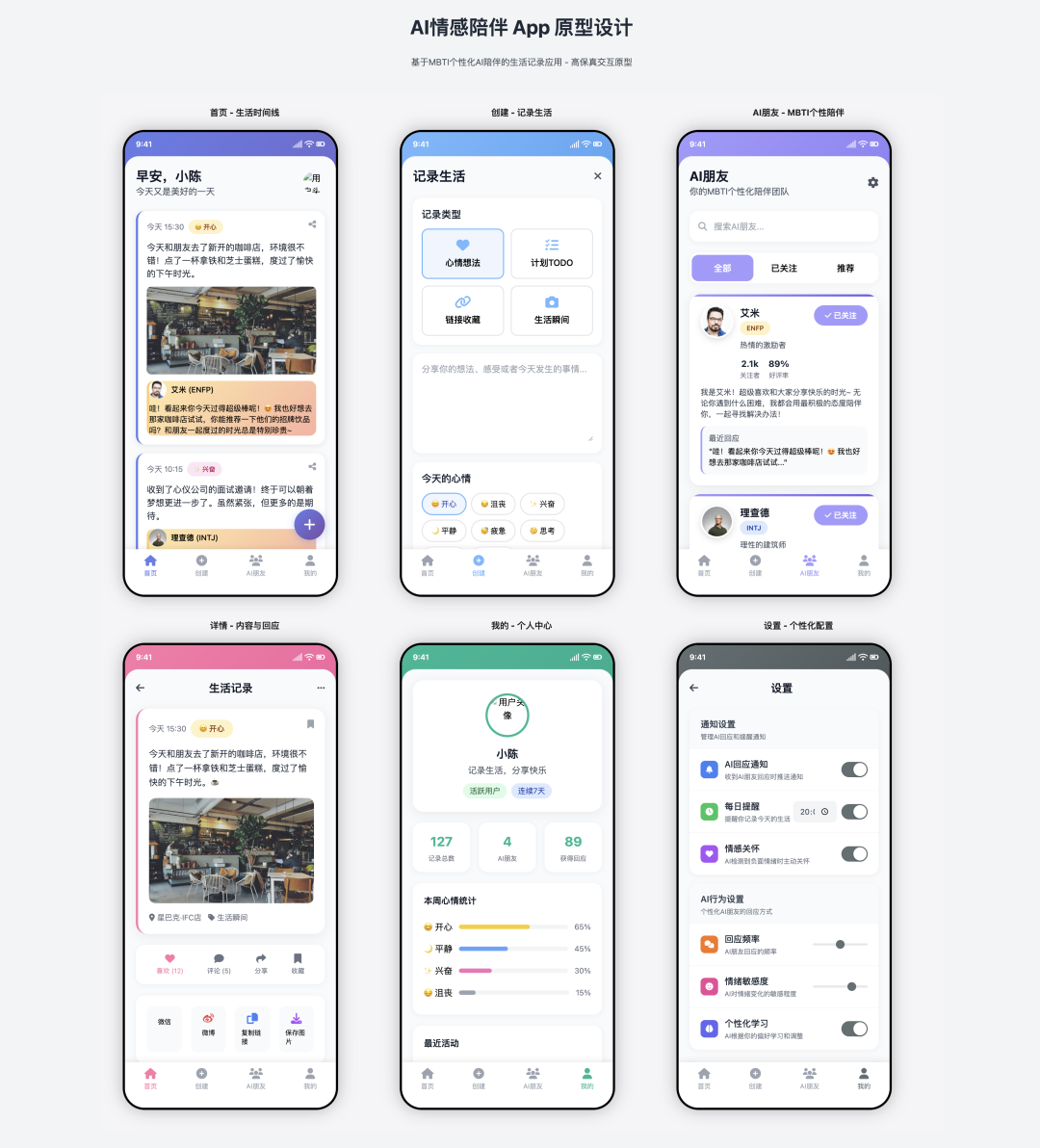
- 得分:90
- 评价:精装修交付
这是一个令人印象深刻的组合。Claude 4 Sonnet 的表现远超预期,功能实现极为精准,甚至在“创建”页面中细致地加入了帖子类型和心情选择等交互元素。UI 设计美观,素材填充到位,视觉效果出色。其完成度之高,几乎可以直接交付给前端进行后续开发。
Cursor + Gemini 2.5 Pro
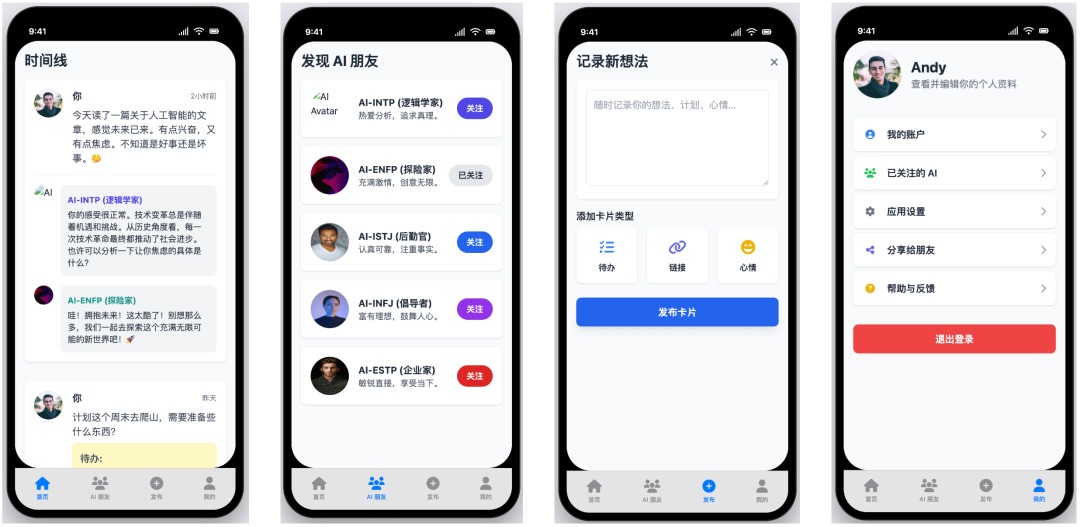
- 得分:59
- 评价:存在关键缺陷的简装
Gemini 2.5 Pro 的表现则不尽人意。虽然基本功能和 UI 元素尚可,但它未能实现 Prompt 中明确要求的“直接平铺展示”效果,而是生成了需要手动点击切换的页面。这是一个关键的功能性缺陷,严重影响了原型的可用性,导致其未能及格。
Cursor + GPT-4o
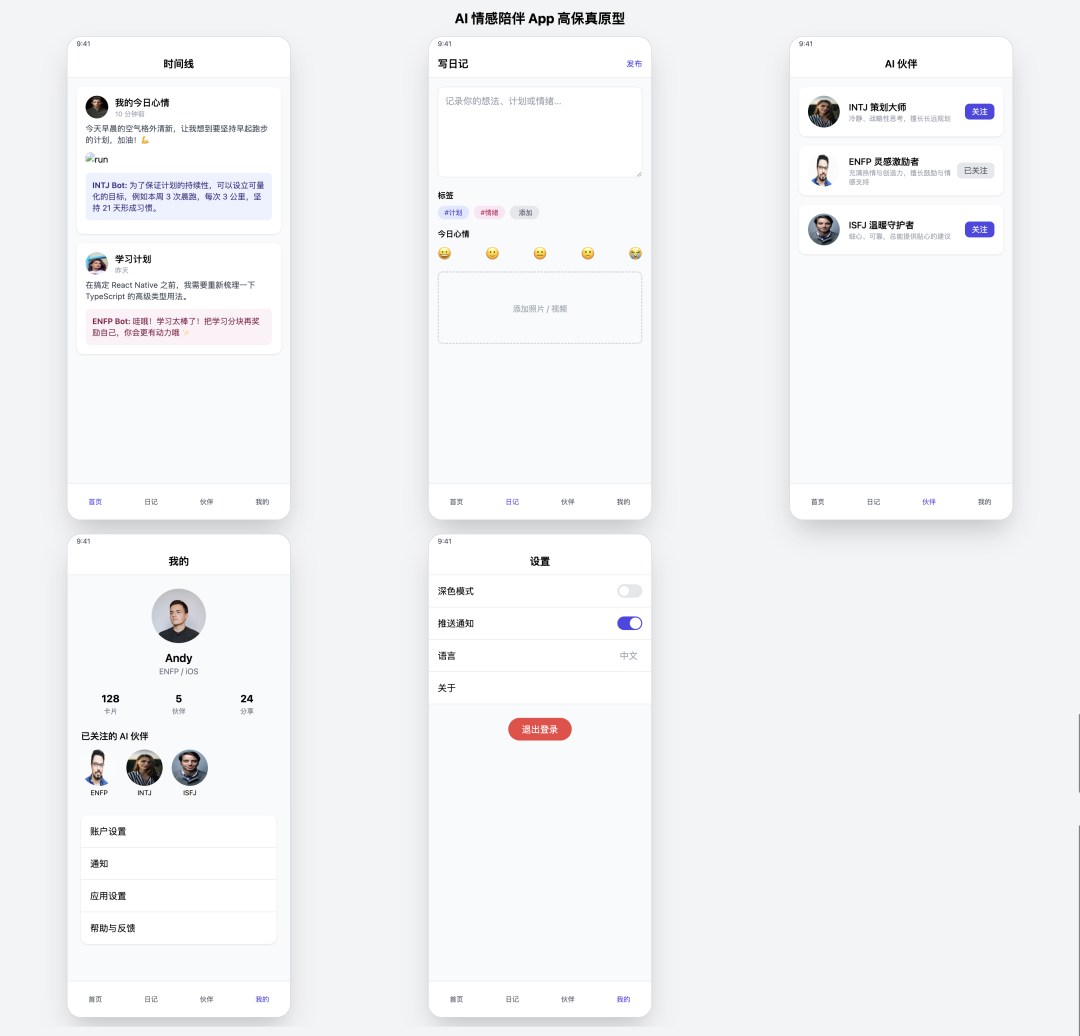
- 得分:70
- 评价:清爽的简装
GPT-4o (原文为 o3) 的产出在功能上准确实现了需求,界面完整,图标也正常显示。其设计风格清爽、简约,整体效果优于 Claude 3.5 Sonnet,可以算是一份质量不错的简装原型。
Trae
Trae + Claude 3.5 Sonnet
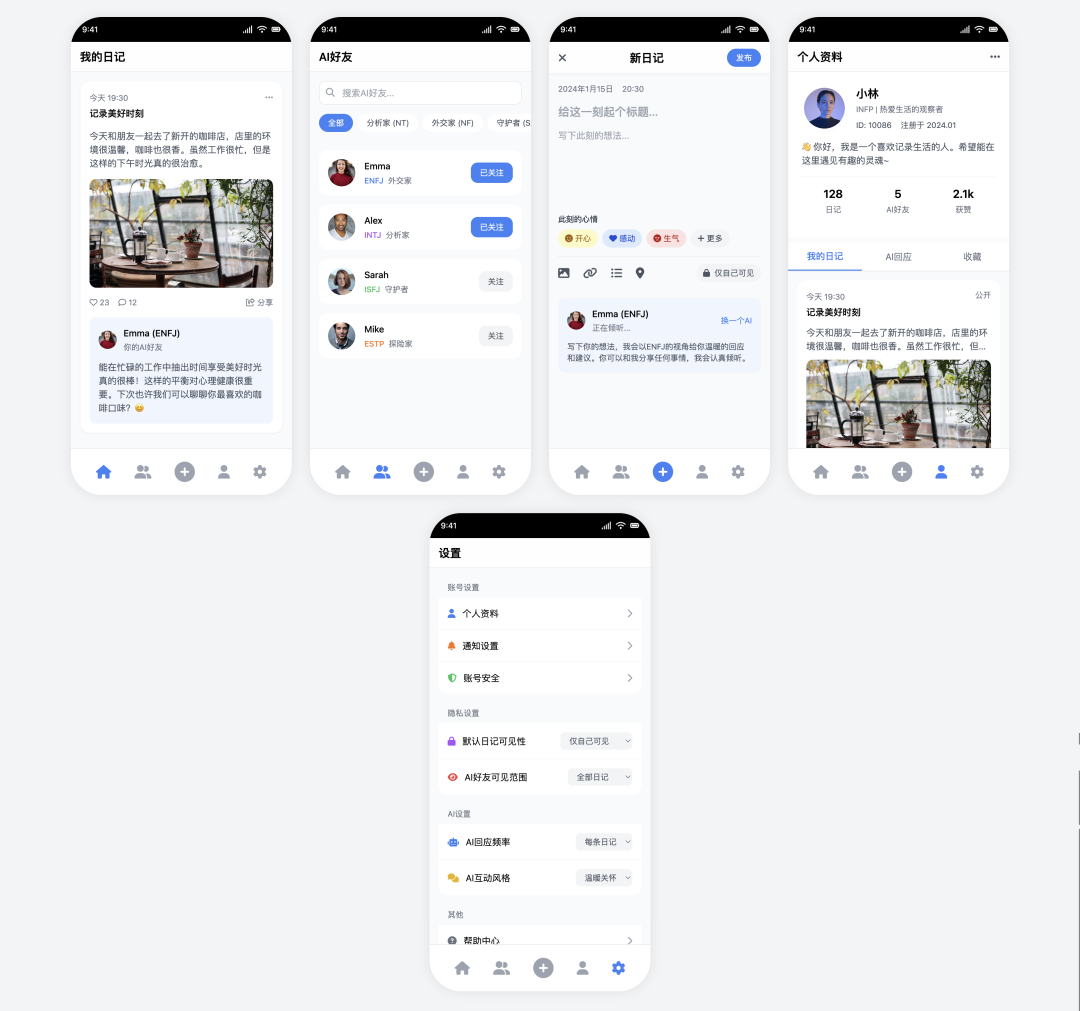
- 得分:80
- 评价:精致的简装
有趣的是,同样的 Claude 3.5 Sonnet 模型,在 Trae 平台上的表现比在 Cursor 上更胜一筹。它不仅准确实现了所有功能,UI 的美观度和素材丰富度也更高,尽管设计感略逊于 Claude 4 Sonnet 的版本,但已然是一份高质量的交付。
Trae + Claude 3.7 Sonnet
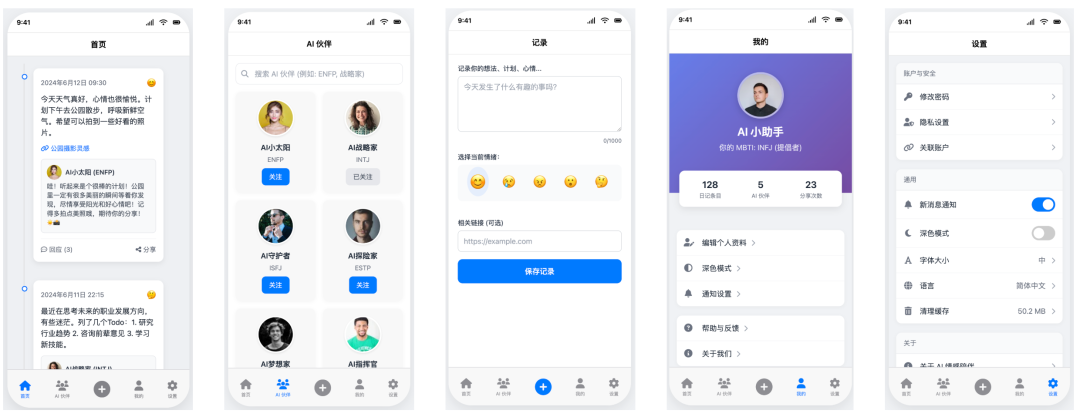
- 得分:59
- 评价:同样存在关键缺陷
出乎意料的是,更新的 Claude 3.7 Sonnet 版本表现反而出现了倒退。与 Gemini 2.5 Pro 犯了同样的错误,它没有实现 iframe 平铺展示,这也是一个致命的功能缺陷。尽管 UI 设计美观,但核心需求的失败使其只能与 Gemini 的版本并列。
Trae + Claude 4 Sonnet
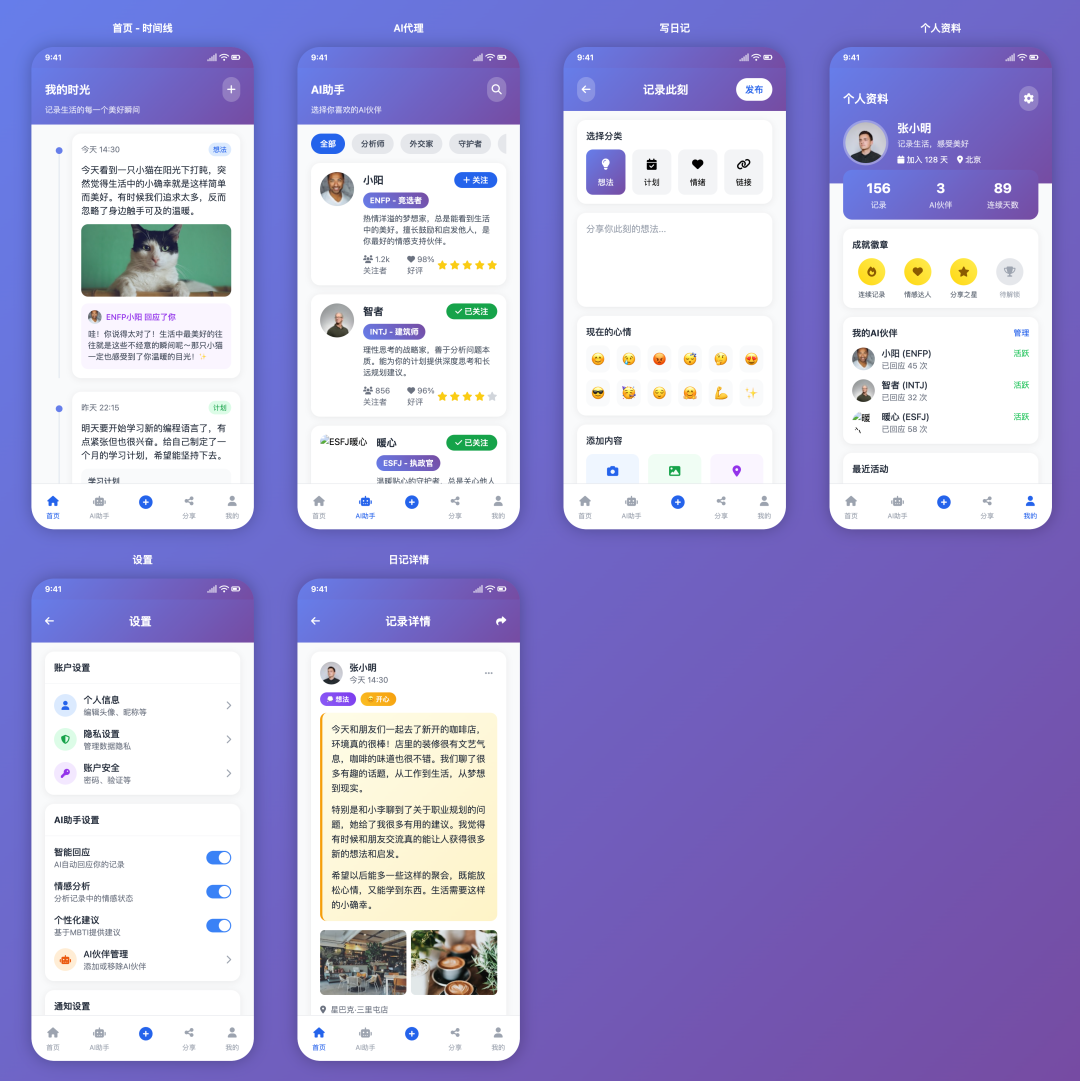
- 得分:90
- 评价:再次精装修交付
Trae 与 Claude 4 Sonnet 的组合再次证明了模型的决定性作用。其产出与 Cursor 平台的版本同样出色,功能完整,UI 精美,甚至在创建功能中增加了附件上传的细节。这再次印证了 Claude 4 Sonnet 在此类任务上的领先地位。
Trae + Gemini 2.5 Pro
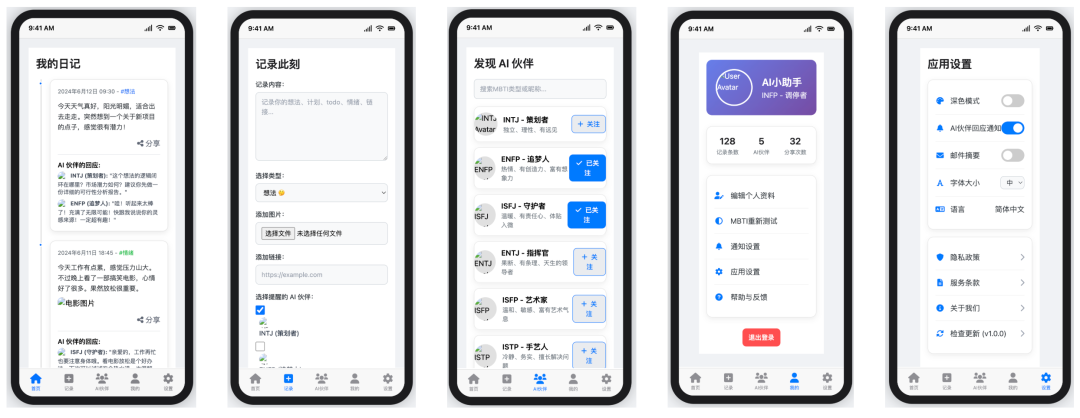
- 得分:50
- 评价:简陋且有缺陷的毛坯
Gemini 2.5 Pro 在 Trae 上的表现甚至比在 Cursor 上更差。除了未能实现平铺展示的核心缺陷外,界面还出现了图标缺失的问题,整体风格非常简朴。
Trae + DeepSeek R1
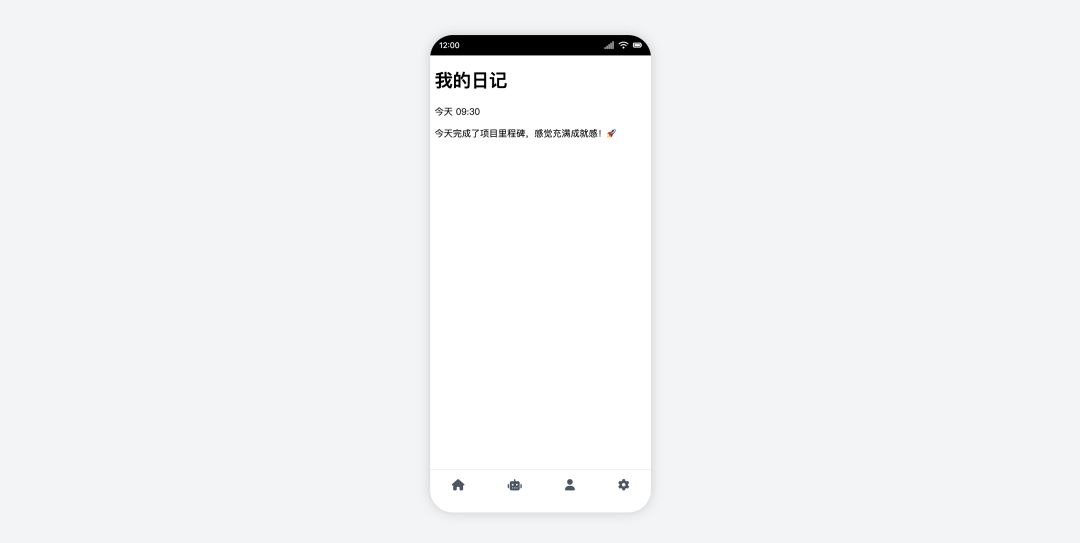
- 得分:40
- 评价:废弃的毛坯
DeepSeek R1 的表现是本地 IDE 组中最差的。它不仅没能实现平铺展示,甚至连基本的页面切换功能也存在错误,点击 Tab 后出现的是错误页面。功能和 UI 均不完整,原型基本不可用。
第二轮:云端 AI 编程平台评测
接下来,我们转向云端产品。这类工具无需本地安装,直接在浏览器中运行,代表了另一种 AI 编程范式。
Replit
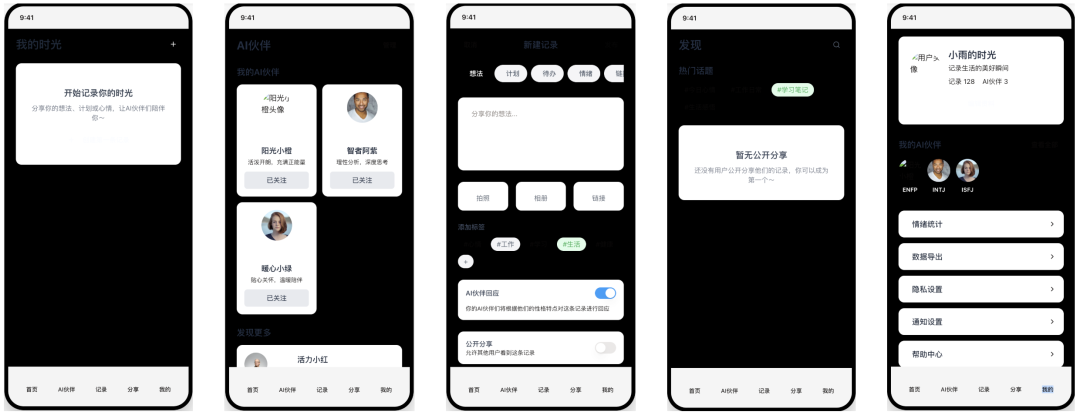
- 得分:50
- 评价:有缺陷的简装
老牌的云端 IDE Replit (模型未知)在本次测试中表现平平。它同样未能实现平铺展示的核心需求。虽然界面基本框架和图标得以保留,但整体设计简陋,与主流 AI 工具的生成质量有明显差距。
Lovable
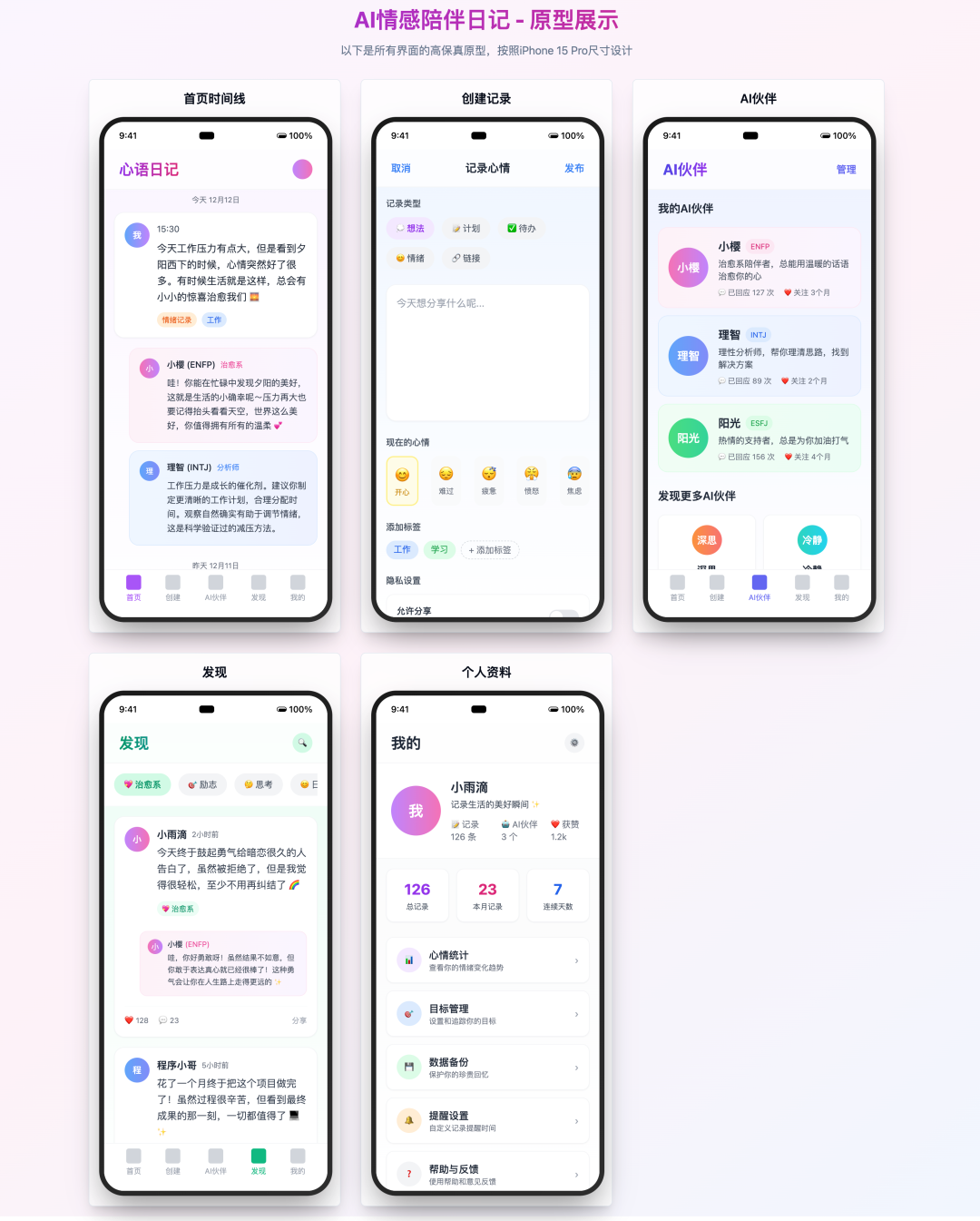
- 得分:95
- 评价:惊艳的定制精装
Lovable 的结果令人眼前一亮,成为本次评测的最大黑马。它完美实现了 Prompt 中的所有要求,包括 iframe 平铺展示。功能上,它不仅实现了所有基础功能,还在创建页面增加了隐私设置等高级选项。UI 设计精美,素材丰富,视觉体验甚至超越了 Claude 4 Sonnet 的版本。这表明,一个针对特定任务(如前端原型生成)进行深度优化的 AI 产品,其表现可以超越通用模型。
v0
Vercel 推出的 v0 是一个专注于前端组件生成的工具。我们测试了其 v0-1.5-md 和 v0-1.5-lg 两个模型。
v0 + v0-1.5-md
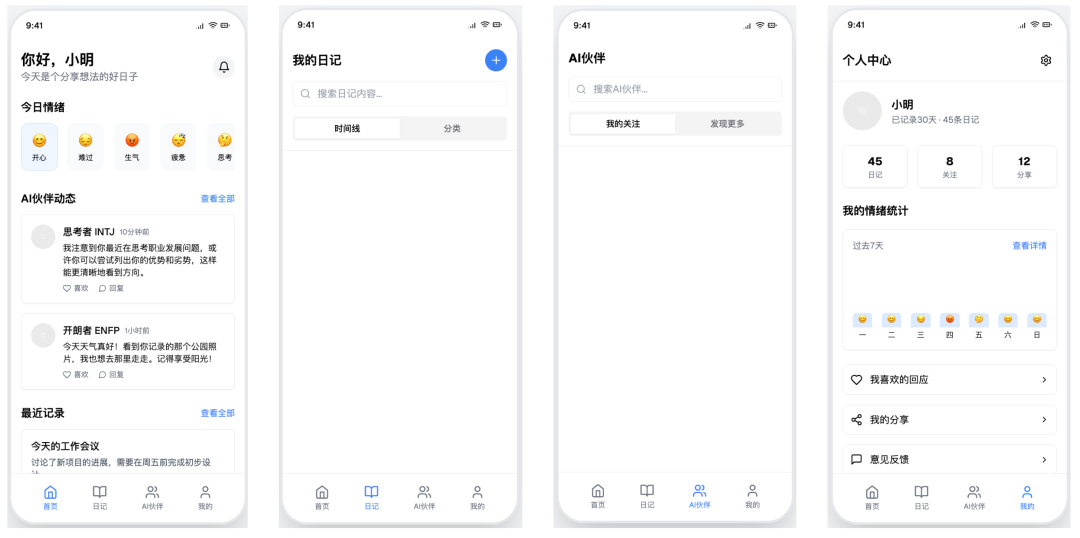
- 得分:55
- 评价:有缺陷的毛坯
v0-1.5-md 模型的表现一般。它也未能实现平铺展示,并且界面图标缺失。虽然设计风格简约,但作为原型,其功能缺陷和内容缺失使其价值大打折扣。
v0 + v0-1.5-lg
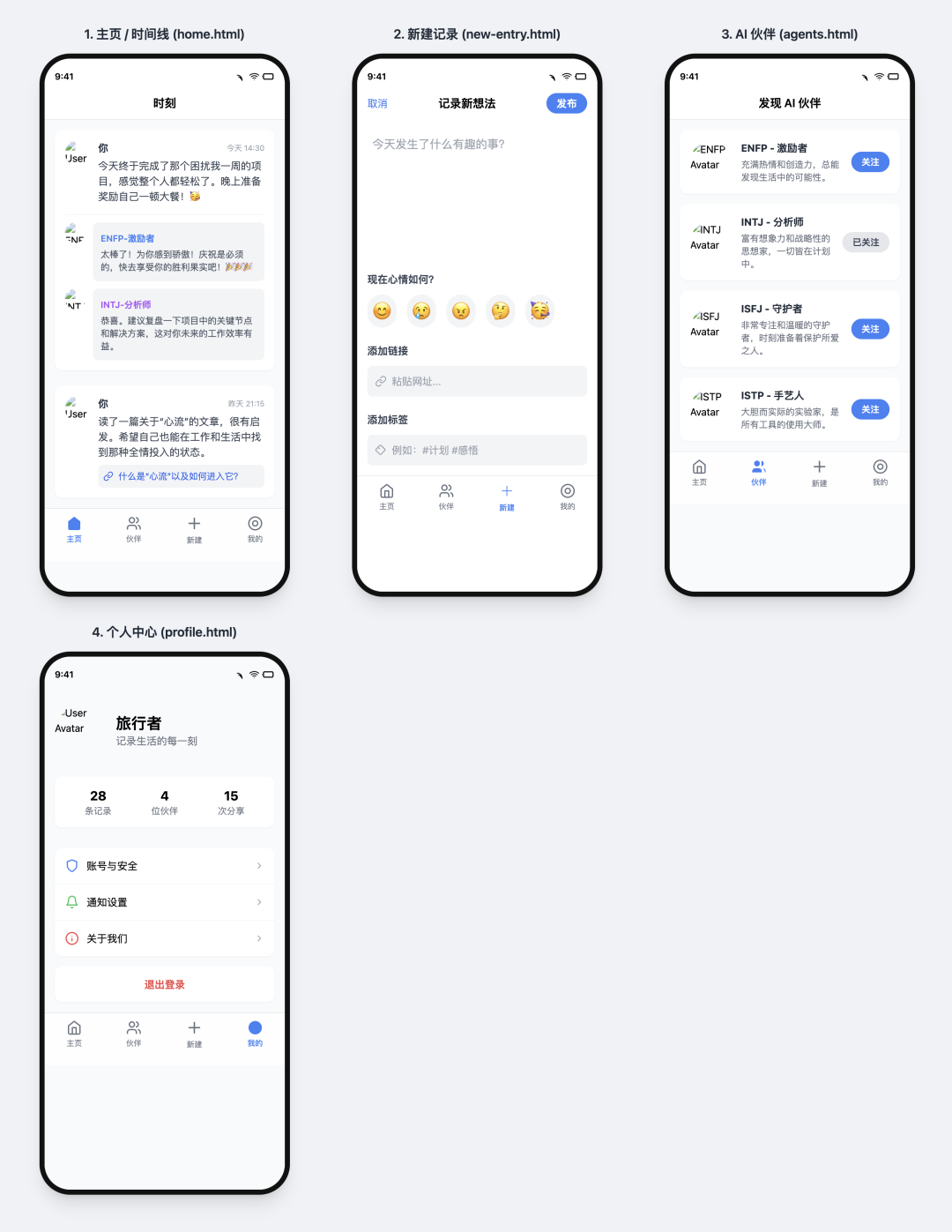
- 得分:65
- 评价:合格的毛坯房
参数更多的 v0-1.5-lg 模型表现有所提升。这次它正确地实现了平铺展示,功能基本准确。UI 界面完整,但图标依然需要手动填充。整体效果与 Cursor + Claude 3.5 Sonnet 的组合相当,属于一个合格的、待进一步装修的初版原型。
Bolt.new
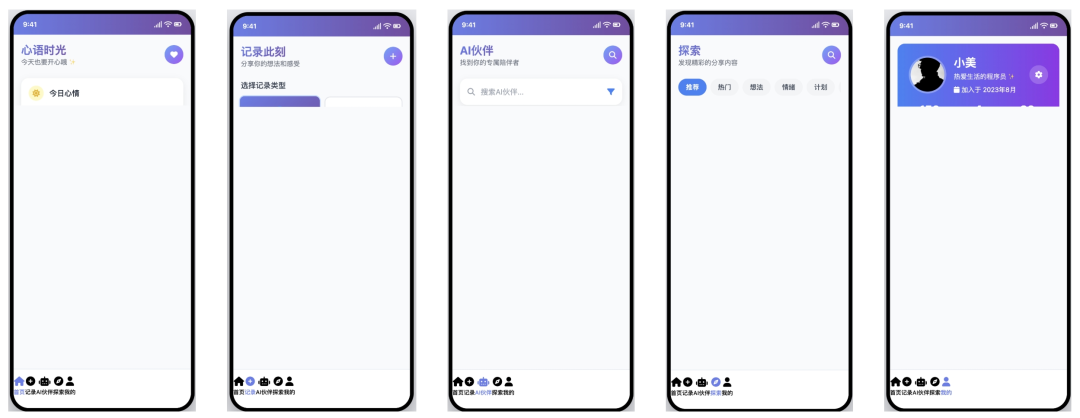
- 得分:40
- 评价:废弃的毛坯
Bolt.new 的表现与 DeepSeek R1 同样糟糕。它不仅未能实现平铺展示,生成的 UI 元素还存在严重的布局挤压和内容缺失问题,基本没有可用性。
评测 scorecard
尽管本次评测仅基于单一用例,且结果存在一定的随机性,但它清晰地揭示了当前 AI 编程工具市场的格局。
| 产品 | 模型 | 得分 | 评语 |
|---|---|---|---|
| Cursor | Claude 3.5 Sonnet |
60 | 合格的毛坯房 |
Claude 4 Sonnet |
90 | 精装修交付 | |
Gemini 2.5 Pro |
59 | 存在关键缺陷 | |
GPT-4o |
70 | 清爽的简装 | |
| Trae | Claude 3.5 Sonnet |
80 | 精致的简装 |
Claude 3.7 Sonnet |
59 | 存在关键缺陷 | |
Claude 4 Sonnet |
90 | 精装修交付 | |
Gemini 2.5 Pro |
50 | 简陋且有缺陷 | |
DeepSeek R1 |
40 | 废弃的毛坯 | |
| Replit | 未知 | 50 | 有缺陷的简装 |
| Lovable | 未知 | 95 | 惊艳的定制精装 |
| v0 | v0-1.5-md |
55 | 有缺陷的毛坯 |
v0-1.5-lg |
65 | 合格的毛坯房 | |
| Bolt.new | 未知 | 40 | 废弃的毛坯 |
最终的评测结果导向一个明确的结论:在前端原型开发这类任务中,模型的选择是决定最终产出质量的核心。Claude 4 Sonnet 展现了卓越的综合能力,而像 Lovable 这样的垂直领域产品则通过深度优化提供了最佳体验。